
Также известно как изучение разреженного словаря, разреженное кодирование. Тем не менее, концепция словарного изучения является одной из неправильно понятых концепций в мире машинного обучения, несмотря на частое присутствие в исследовательских работах.
Что такое изучение словаря?
Во-первых, это никак не связано со структурой данных словаря. Идея «словаря» исходит из построения основ для данного векторного пространства в линейной алгебре. Матрица оснований также называется словарной матрицей, а алгоритм построения, предназначенный для генерации словарной матрицы, носит название «словарное изучение».
Изучение словаря представляет собой разреженную схему кодирования. Где схема кодирования без потерь с точки зрения аналитической реализации. И это гарантированное глобальное оптимальное кодирование с точки зрения численной реализации, поскольку аналитическая переформулировка представляет собой задачу выпуклой оптимизации.
Где используется изучение словаря?
Поскольку концепция обучения по словарю представляет собой четко определенное аналитическое решение для кодирования векторного пространства, концепция обучения по словарю используется от чисто математического вывода до обучения нейронной сети, которая может анализировать изображения мозга ЭЭГ. Области обработки сигналов, дистанционное зондирование, сжатие данных, обработка изображений, обработка видео, обучение нейронных сетей — популярные области, в которых широко используется словарное обучение.
Теоретическая основа изучения словаря
Если вы знакомы с концепциями базисов, остовных множеств и ранжирования в линейной алгебре, было бы полезно получить более глубокое понимание концепции, которую мы собираемся обсудить. Если вы не знакомы или не в курсе, посмотрите это видео, прежде чем продолжить.
Проще говоря, изучение словаря — это численное решение для вычисления «основ» на заданном наборе векторов. Итак, Почему мы не можем использовать аналитическое решение? просто потому, что это NP-полная задача с точки зрения вычислительной сложности. Следовательно, нет никакой гарантии, что мы получим решение, особенно с большой матрицей.
Словарь (базовая матрица) состоит из атомов (баз), атомы не обязательно должны быть ортогональны явно и, возможно, являются сверхполным остовным набором (нарушение свойства линейной независимости баз)
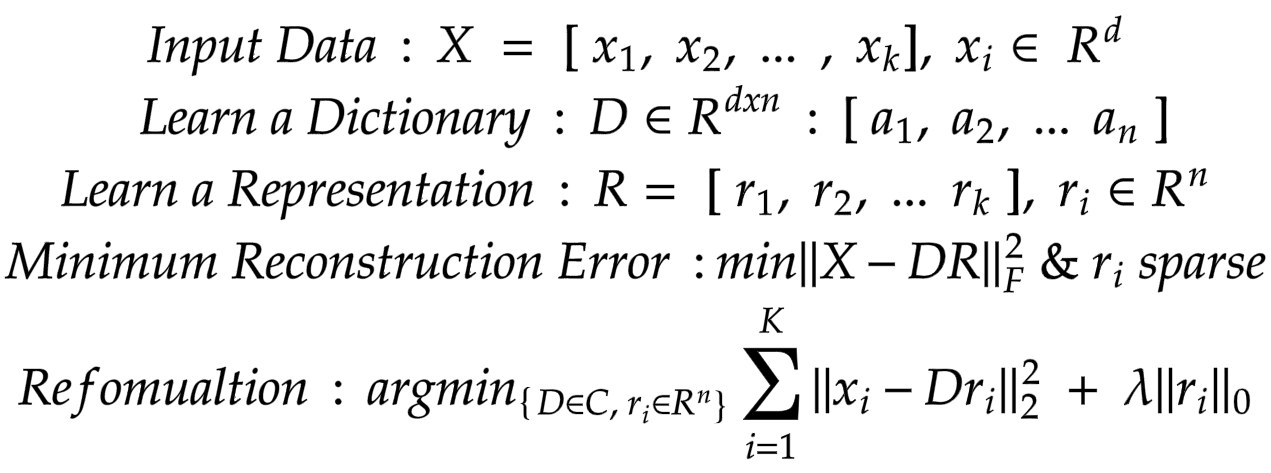
Изучение словаря тренируется в задаче оптимизации ограничений, где ограничениями являются увеличение разреженности коэффициента выше заданного порога и оптимизация, выполняемая для минимизации разницы умножения изученной матрицы «D» и ее матрицы коэффициентов «R» из матрицы входных данных «X».
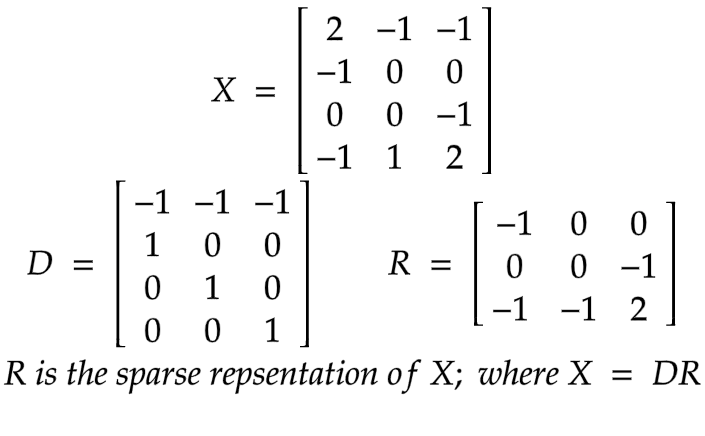
В примере x_1 = [2, -1, 0, 1], где размерность 'd' равна 4. И основания 'D' входного векторного пространства 'X' здесь я вычислил вручную, а его матрица коэффициентов ' Р'. Как показано, кодирующая матрица R имеет меньшую размерность, чем входное векторное пространство X (4 ‹ 3). Таким образом, при работе здесь используйте пространство кодирования R вместо X.
Аналитически было построено несколько методов для решения указанной выше задачи оптимизации ограничений, и каждый метод имеет свои плюсы и минусы. Например, метод оптимального направления (MOD) эффективен в малоразмерном пространстве, гарантирует оптимальное решение при n › минимальном размере выборки. Однако он требует больших вычислительных ресурсов для входных векторных пространств более высокой размерности, поскольку вычисляет псевдоинверсию R. Кроме того, K-SVD — это еще один метод, основанный на концепции k-среднего.
практический пример изучения словаря
В целях реализации здесь я использовал sk-learn встроенный DictionaryLearning модуль. Кроме того, sk-learn module поддерживает намного больше конфигураций изучения словаря, чем я реализовал здесь, поэтому я рекомендую вам перейти по этой ссылке, чтобы получить больше информации о модуле.
Пространство векторов кодирования, сгенерированное нашей реализацией, является более разреженным, чем матрица R, показанная выше. Кроме того, теперь вы можете заметить, что с увеличением разреженности векторы кодирования становятся намного проще и точнее.
Почему разреженность вообще важна? вообще говоря, чем выше разреженность кодирования, тем выше итоговая устойчивость словаря к шуму. Следовательно, алгоритм, питаемый этим векторным пространством, может легко повысить точность при уменьшении времени обработки. Однако важность разреженности в ML — это тема для обсуждения в другой день. Между тем, я рекомендую вам следовать этой статье о разреженном кодировании, если вы ищете дополнительные знания.
почему он используется в машинном обучении?
Просто потому, что изучение словаря — это алгоритм разреженного кодирования. А в машинном обучении почти все время алгоритмы поддерживаются системой обучения представления или системой кодирования данных. Тем не менее, изучение словаря также имеет некоторые бонусы. если `k` › минимальный размер выборки и векторы не были затронуты шумом, гарантируется, что результирующий словарь может дать оптимальное кодирование для любой точки в обученном векторном пространстве, даже для векторов, которые не были замечены в обучении время. кроме того, более редкие и ортогональные кодировки делают его оптимальным для использования в NN или общем алгоритме ML.
Я надеюсь, что теперь вы хорошо понимаете основы изучения словаря. Тем не менее, здесь есть что исследовать в изучении словаря, особенно в области глубокого обучения. И я надеюсь, что эти знания будут полезны в этом путешествии!
Наконец, спасибо, что прочитали эту статью!!