
Введение
Анализ настроений — это хорошо изученная область с сотнями статей или блогов, предлагающих методы и алгоритмы для решения задачи. Важность настроения в тексте может иметь решающее значение для некоторых компаний, организаций или частных лиц. Например, компания, которой нужно знать, получает ли продукт, который они продают, положительные отзывы, или артист, который хочет отслеживать общественное мнение (положительное или отрицательное) о своей музыке.
Многие из предложенных методов и алгоритмов, которые решают эту задачу, обладают высокой производительностью, но в большинстве случаев они требуют маркировки данных, которые обычно маркируются экспертами в предметной области. Этот процесс может занять много времени, может быть дорогим и трудным.
Напротив, получение неразмеченных данных является относительно более простой задачей. В современном мире существует бесконечное количество платформ, где люди могут писать свои мысли или комментарии. Большое количество текстов написано людьми, и эти тексты можно использовать для анализа настроений.
Из сказанного выше у меня возник вопрос, можем ли мы использовать неразмеченные данные или только небольшую их часть для прогнозирования тональности в тексте?
Хотя существуют модели-трансформеры (в Huggingface), которые были обучены анализу настроений и дают хорошие результаты, я представлю другой метод в качестве доказательства концепции, который может быть полезен для других задач. Этот метод включает в себя использование предварительно обученного внедрения предложений для прогнозирования тональности в тексте, в основном на основе предварительно обученной модели, а не на основе помеченных данных, если они существуют.
Фон
Помеченные данные

Маркировка данных может оказаться сложной задачей. Для этой задачи требуются люди со знанием предметной области, которые изучат весь набор данных и пометят его. Этот процесс может занять много времени, особенно в области текста, где разработчик должен прочитать текст, который может быть длинным, а затем решить, что такое метка.
В анализе тональности часто меткой является тональность текста. Обычно настроения положительные или отрицательные (иногда также нейтральные). На некоторых платформах авторы могут добавлять рейтинг, который коррелирует с настроением, но на других человеку нужно определить настроение на основе самого текста, что является долгой и дорогой задачей.
Встраивание предложения

В популярной статье Word2Vec мы познакомились с качественными векторами слов. Они содержат семантические отношения между словами. С тех пор были проведены обширные исследования для улучшения качества векторов слов. Следующий значительный скачок в производительности и качестве векторов произошел с публикацией BERT, алгоритма на основе преобразователя, который создает векторы слов на основе контекста. BERT и все его преемники (такие как ROBERTA) прошли обучение на огромном количестве текстов, изучили отношения между словами и достигли самых современных результатов в различных задачах НЛП.
Одной из областей исследования является изучение векторного встраивания для полного предложения/абзаца, в отличие от оригинального BERT, где каждое слово имеет свой собственный вектор. Преимущество наличия одного вектора для предложения очевидно: вектор одного размера (независимо от длины предложения), который представляет основную концепцию предложения.
Одним из примеров использования встраивания предложений является вычисление сходства между двумя предложениями, например, двумя новостными статьями, посвященными одной и той же истории. Близкие тексты предполагают наличие «похожих» векторов в скрытом пространстве.
Сегодня несколько компаний, имеющих доступ к огромному количеству текстовых данных и мощности компьютеров, часто выпускают предварительно обученные модели для общего пользования. Это изменило правила игры, так как многие не могут обучить такую модель самостоятельно. Сегодня каждый человек, компания или организация могут использовать эти предварительно обученные модели, чтобы повысить производительность своих желаемых проектов.
Цель исследования
Прежде чем мы продолжим, давайте определим цель нашего исследования, на какой вопрос мы пытаемся ответить.
Можем ли мы использовать предварительно обученную модель встраивания предложений, чтобы предсказывать настроение в тексте на основе обученных взаимосвязей, с минимальными помеченными данными или без них?
Данные
Следующие эксперименты были проведены на четырех различных наборах данных.
- Образец из обзоров Amazon TV. Я использовал только положительные (4 или 5 звезд) и отрицательные (1 или 2 звезды) отзывы. Позитивное настроение — 18 389 записей, Отрицательное настроение — 6 539 записей.
- Образец из обзоров ноутбуков Amazon. Я использовал только положительные (4 или 5 звезд) и отрицательные (1 или 2 звезды) отзывы. Позитивное настроение — 2955 записей, Отрицательное настроение — 792 записи.
- Отзывы об авиакомпаниях в твиттере. Позитивное настроение — 314 записей, отрицательное настроение — 1466.
- Рецензии на фильмы на IMDB. Я использовал только положительные и отрицательные отзывы. Позитивное настроение — 12 500 записей, Отрицательное настроение — 12 500 записей.
Обзоры Amazon взяты с http://jmcauley.ucsd.edu/data/amazon/links.html [1]. Для получения данных требовалось отправить владельцам гугл-форму. Набор данных является общедоступным и бесплатным для использования после утверждения.
Обзоры твитов авиакомпаний можно получить (с действительным пользователем в data.world) с https://data.world/crowdflower/airline-twitter-sentiment. Данные являются общедоступными и могут использоваться бесплатно.
Обзоры фильмов IMDB можно получить по адресу https://ai.stanford.edu/~amaas/data/sentiment/ [2]. Набор данных является общедоступным и бесплатным для использования.
Помеченные данные в четырех наборах данных использовались для оценки или обучения (только небольшая выборка). Наборы данных относятся к разным областям, разным размерам и разным пропорциям между положительными и отрицательными классами.
Предварительно обученная модель встраивания предложений
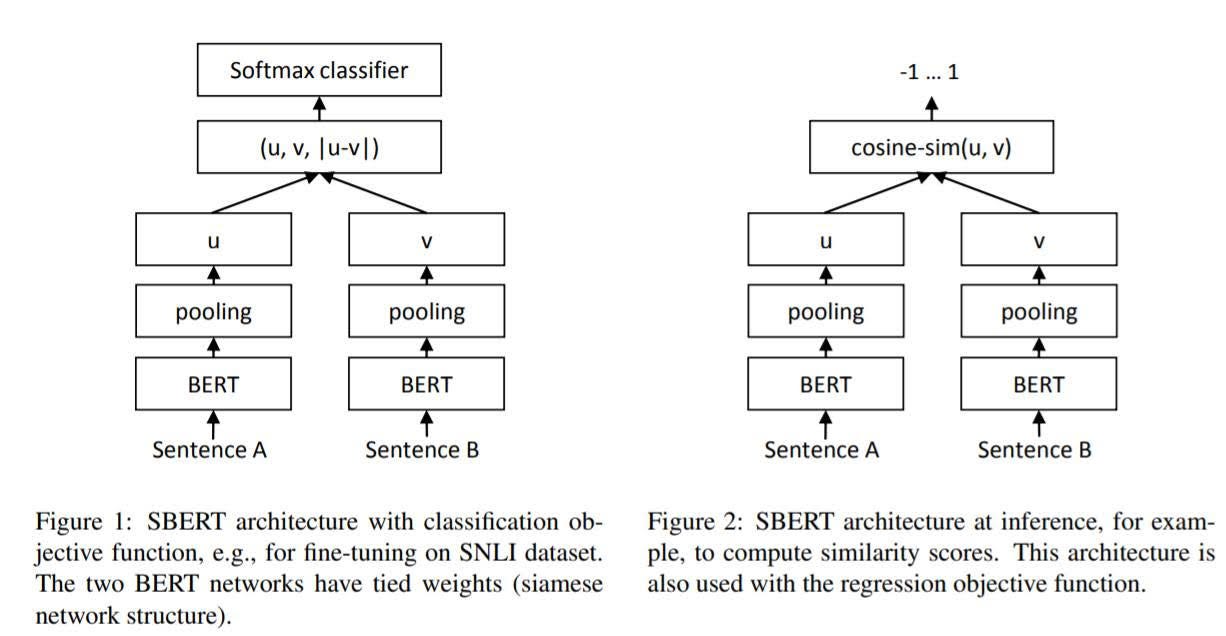
В следующих экспериментах я использовал модель Sentence Bert (в Huggingface она называется nli-roberta-large — отказ от ответственности, эта модель устарела). Модель основана на документе Sentence-BERT: Sentence Embeddings с использованием сиамских сетей BERT [3].
В статье нам представлена новая модель, основанная на BERT, с дополнительными слоями и конкретной задачей по улавливанию связей между близкими текстами.
Новая архитектура:
- слой объединения поверх векторов слов BERT (было протестировано несколько слоев объединения, но среднее объединение дало наилучшие результаты).
- Объединение векторов из двух предложений и другого вектора вычитания между ними (были протестированы и другие комбинации, но эта дала наилучшие результаты).
- Сиамские Bert-Networks (общие веса).
Задание:
- Мультиклассовая классификация с перекрестной энтропийной потерей в наборе данных SNLI для подобия текста.
Во время вывода предложение подается в алгоритм, и на выходе получается вектор фиксированного размера. Тесты на сходство (например, основанные на косинусном сходстве) могут быть выполнены, чтобы решить, похожи ли два текста.
Модель превзошла исходный BERT (с использованием средних векторов или вектора CLS) и Average GLOVE.
Эксперименты
Определение настроения
Первое, что нужно сделать, это определить, что является «позитивным» или «негативным» вектором настроений. Первое, о чем я подумал, был вектор для слова «положительный» и еще один для «отрицательного». Логика моего решения заключалась в том, что модель, обученная на огромном количестве текста, изучит значение этих слов. Чтобы «усилить» настроение, я также добавил к каждому вектору слова «хороший» и «плохой» соответственно.
Процедура эксперимента
- Использование косинусного сходства между текстовым вектором и двумя векторами настроений, чтобы решить, каково настроение текста (если косинусное сходство между текстом и положительным вектором выше, чем два, то текст будет классифицироваться как положительный и то же самое для отрицательного).
2. Сочетание помеченных данных и сходства косинусов:
- Обучите сеть с категориальной кросс-энтропийной потерей (классы положительные и отрицательные). Каждый текст был классифицирован с помощью того же процесса, что и в первом эксперименте.
2. Точная настройка сети с данными с метками X (X — количество данных с метками, это параметр, который я контролировал в этом эксперименте).
Во втором эксперименте я сравнил два подхода. Первый, с двумя шагами, как указано выше. Второй, только с обучением на размеченных данных (только второй шаг). Я повторил эксперимент 100 раз и рассчитал средний отзыв, точность и балл F1, чтобы получить более высокую статистическую значимость.
Полученные результаты
Первый эксперимент
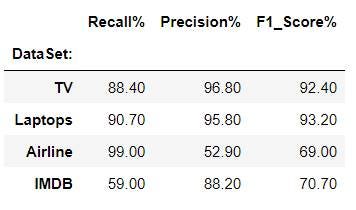
Результаты первого эксперимента, основанного только на косинусе, довольно интересны. В наборах данных Amazon метод показал высокие результаты без каких-либо размеченных данных.
В наборах данных Airline и IMDB мы видим компромисс между полнотой и точностью. В то время как модель предсказывает более положительные тексты в наборе данных Airline, что приводит к высокому отзыву, точность была ниже. На IMDB мы видим обратное.
В целом, результаты первого эксперимента показывают, что есть основания использовать встраивание предложений, когда у нас вообще нет размеченных данных (лучше, чем случайная классификация).
Второй эксперимент

Метрика, которую я использовал для оценки в этом эксперименте, — это оценка F1, которая учитывает полноту и точность. В трех из четырех наборов данных оценка F1 была выше при двухэтапном подходе, т. е. первое обучение с косинусным сходством улучшило производительность модели для размеченных данных небольшого размера. Наибольшее улучшение наблюдается в наборе данных авиакомпаний, когда помеченные данные = 10 (увеличение оценки F1 на 22%).
По мере увеличения количества помеченных данных разница в баллах F1 между двумя подходами уменьшается до тех пор, пока разница не исчезнет (например, в наборе данных Airline).
Как и в первом эксперименте, двухэтапный подход не работал с набором данных IMDB (мы получили более низкую производительность с увеличением размеченных данных). Кроме того, производительность модели (с одноэтапным обучением) относительно хуже по сравнению с другими тремя наборами данных. Это может указывать на то, что модель, которую я использовал, может не подходить (возможно, другая архитектура может повысить производительность).
Заключение
Мы начали с вопроса о том, можем ли мы использовать предварительно обученную модель, встраивающую предложение, для повышения производительности задач сентиментов. Мы экспериментировали с помеченными данными и без них. Хотя существует потребность в более глубоком исследовании и оценке, основанной также и на других показателях, из эксперимента, который я провел в этой статье, кажется, что в некоторых случаях мы можем использовать предварительно обученную модель для улучшения результатов нашей модели. Это в том случае, если у нас мало или нет помеченных данных.
В первом эксперименте по рекомендации Amazon была достигнута высокая производительность только на основе модели встраивания предложений. Во втором эксперименте первый шаг повысил производительность модели для наборов данных Amazon для всех размеченных размеров данных. Будет интересно продолжить исследование этой области также с проблемами классификации (такими как категории новостей и т. д.). Кроме того, интересны дальнейшие исследования с другими и более качественными моделями встраивания предложений или моделями, которые были точно настроены на задачу тональности.
[1] Он, Руининг и Джулиан Маколи. «Взлеты и падения: моделирование визуальной эволюции модных тенденций с помощью одноклассовой совместной фильтрации». Материалы 25-й международной конференции по всемирной паутине. 2016.
[2] Маас, Эндрю и др. «Изучение векторов слов для анализа настроений». Материалы 49-го ежегодного собрания ассоциации компьютерной лингвистики: технологии человеческого языка. 2011.
[3] Реймерс, Нильс и Ирина Гуревич. «Приговор-берт: вложения предложений с использованием сиамских берт-сетей». препринт arXiv arXiv:1908.10084 (2019 г.).