
Что такое наивный байесовский алгоритм?
Это метод классификации, основанный на теореме Байеса с предположением, что наличие определенного признака в классе не связано с наличием какого-либо другого признака.
Например, фрукт может считаться бананом, если его цвет желтый и он длинный. Точно так же красный фрукт круглой формы можно считать яблоком. Здесь такие особенности, как форма и цвет плода, являются независимыми признаками.
Наивный байесовский классификатор основан на теореме Байеса, в которой используются условные вероятности.
1. Условная вероятность
Условная вероятность определяется как вероятность наступления события или исхода, основанная на наступлении предыдущего события или исхода. Он рассчитывается путем умножения вероятности предыдущего события на обновленную вероятность последующего или условного события.

Приведенное выше уравнение читается как Вероятность события A при условии, что произошло событие B = Вероятность того, что произошли оба события A и B / Вероятность того, что произошло событие B.
Чтобы лучше понять условную вероятность, рассмотрим пример, в котором в семье с двумя детьми мы хотим найти вероятность того, что оба ребенка — девочки, при условии, что хотя бы один ребенок — девочка.
Пример пространства «S» будет {BG, GB, GG, BB}, где G означает девочку, а B означает мальчика.
Событие «А» -> Оба ребенка девочки; Событие «B» -› По крайней мере, один ребенок — девочка
P(A∩B) = 1/4 ; P(B) = 3/4
∴ P(A|B) = 1/3
2. Теорема Байеса
Теорему Байеса можно математически сформулировать так:

где y=класс зависимой переменной; х = независимая функция
Для нескольких независимых функций эту формулу можно переписать как:

Поскольку знаменатель является константой, мы будем игнорировать его для математической простоты.

3. Работа алгоритма наивного Байеса на примере
Давайте возьмем набор данных, чтобы предсказать, можем ли мы погладить животное или нет, где наши тестовые данные = (Корова, Средний, Черный)
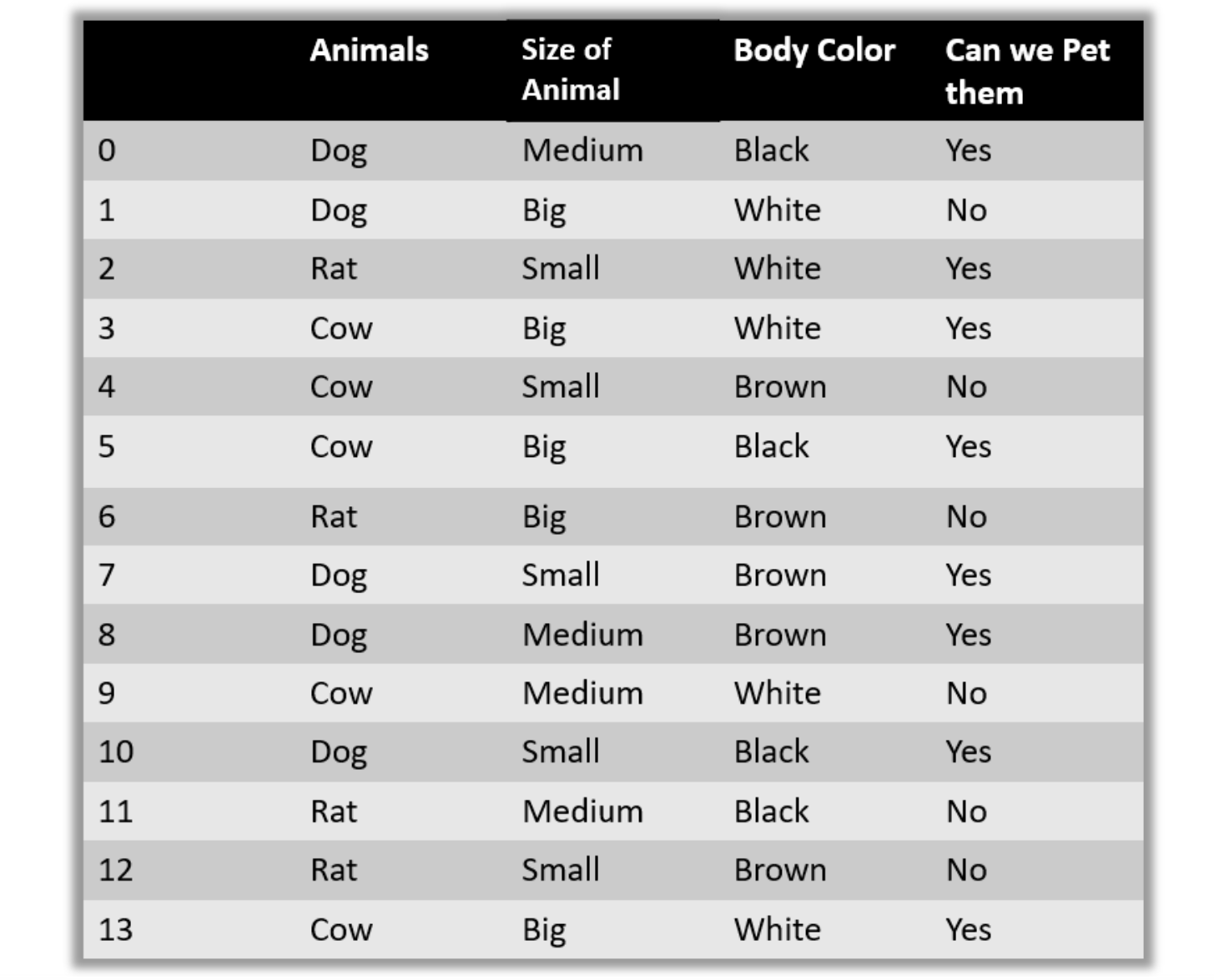
Необходимые действия:
1. Рассчитать условные вероятности
2. Применить наивный байесовский алгоритм
3. Нормировать результат
Шаг 1. Предполагается, что все функции независимы. Нам также потребуется предварительно вычислить следующие вероятности


Шаг 2. Теперь вероятность получить домашнее животное:

Шаг 3. Поскольку P(yes|test) + P(no|test) = 1, мы нормализуем приведенные выше результаты.

Результат: Поскольку P(yes|test) › P(no|test), мы можем предсказать, что тестовое животное является домашним животным.