
Современная обработка естественного языка (NLP) в значительной степени опирается на большие и мощные модели Transformer. Языковые модели, такие как BERT, продемонстрировали почти человеческую способность обрабатывать естественный язык. При точной настройке на набор данных ответов на вопросы они отлично подходят для получения содержательных ответов из больших коллекций документов.
Но для некоторых приложений — например, для развертывания на мобильных устройствах — самые производительные модели могут оказаться слишком громоздкими. Они также медленно выполняют вывод, что может стать проблемой, если вы хотите масштабировать свою модель для обработки сотен или тысяч запросов в день.
Возможно, вы слышали о перегонке знаний и дистиллированных моделях — меньших моделях, которые используют мощь своих более крупных аналогов, экономя при этом время и ресурсы. Мы рады сообщить, что Структура Haystack теперь предоставляет все инструменты, необходимые для создания собственных моделей, всего в нескольких строках кода. Итак, если вы хотите повысить производительность своих моделей, сделав их быстрее или точнее, эта статья для вас!
Что такое модельная дистилляция?
Чтобы определить размер модели, вы можете посмотреть на количество обучаемых параметров. Это общее количество весов во всех различных слоях вашей модели, и оно часто исчисляется миллионами или даже миллиардами. BERT-base, например, имеет 110 миллионов параметров, а BERT-large в три раза больше. Однако исследования показали, что в моделях глубокого обучения много избыточности.
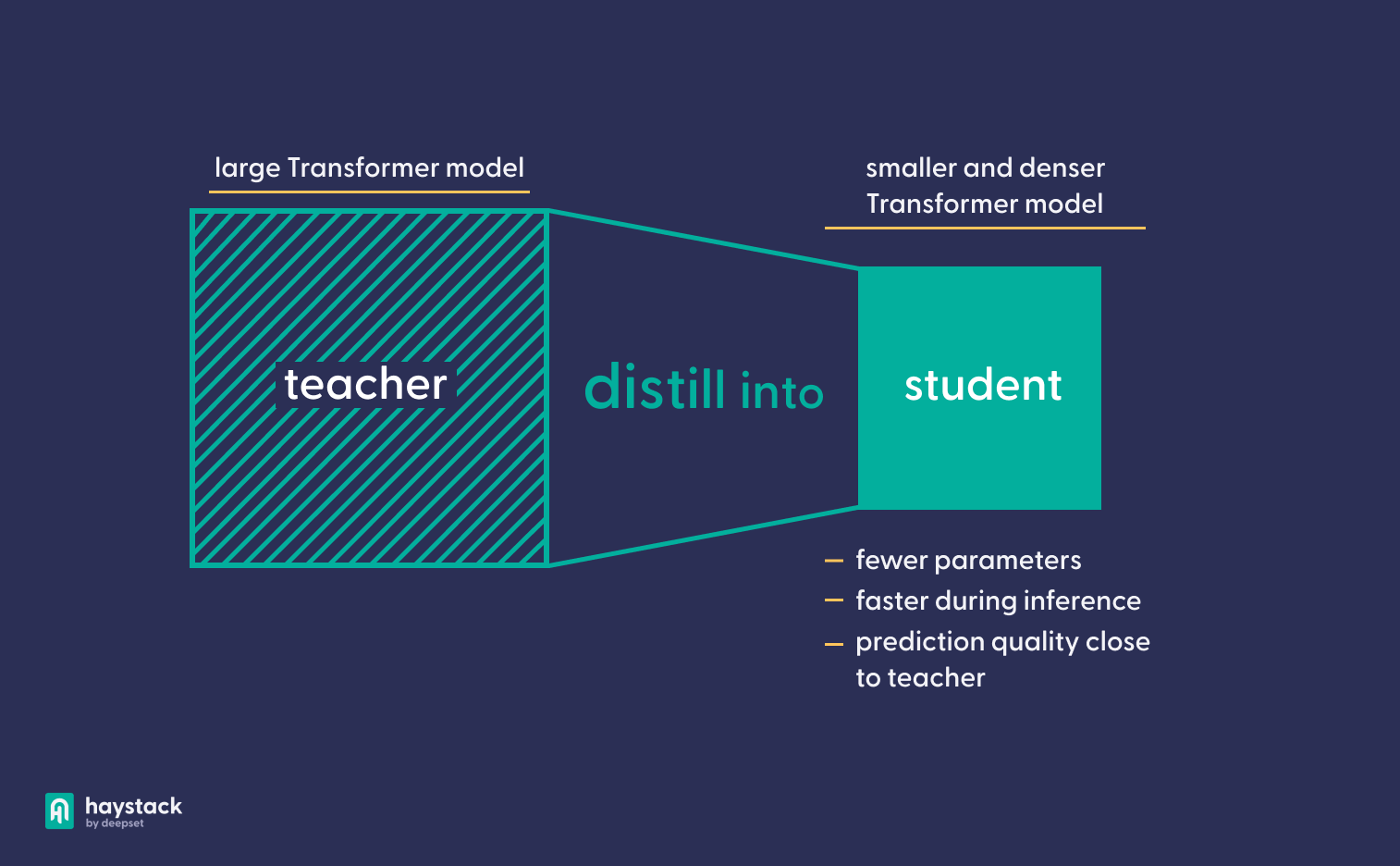
Методы сжатия моделей направлены на создание моделей меньшего размера за счет устранения избыточной информации. Дистилляция модели, тип сжатия модели, описывает перенос знаний из большой модели в меньшую модель с меньшим количеством параметров. Дистиллированная модель намного быстрее, чем большая модель, из которой она получена. В то же время он работает лучше, чем неперегнанная модель того же размера.
Зачем вам дистиллировать свои модели?
Есть как минимум две веские причины для дистилляции ваших моделей. Возможно, вас устраивает качество прогнозов вашей модели, но вы хотите, чтобы она выполняла выводы быстрее — возможно, чтобы увеличить количество запросов, которые ваша система может обработать за заданный период времени. В этом случае ваша модель может быть преобразована в модель меньшего размера. В зависимости от метода дистилляции вы можете приблизить точность своей меньшей модели к точности большой модели.
В качестве альтернативы вы можете улучшить качество прогнозирования вашей модели, сохранив при этом ее размер и скорость вывода. В этом случае вы можете сначала обучить более крупную модель, а затем преобразовать эту модель в исходную архитектуру меньшей модели.
Как правило, мы рекомендуем дистилляцию модели всем, кто хочет использовать модель Transformer в производстве. Это позволяет вам экономить память, ускорять вывод или повышать качество прогнозов вашей модели — что может не нравиться?
Как работает дистилляция модели?
Дистилляция модели работает с парадигмой учитель-ученик. «Учитель» — это более крупная модель, чьи знания мы хотим сжать в меньшую модель «ученика». Для достижения этой цели мы используем ряд функций потерь, которые побуждают ученика подражать поведению учителя — либо только в его прогнозирующем слое, либо также и в скрытых слоях.
Процесс дистилляции модели аналогичен обучению модели с нуля: модель видит данные и должна предсказать правильные метки. Например, модель «вопрос-ответ» должна предсказать правильный диапазон ответов на заданный вопрос. С помощью функции потерь, которая измеряет, насколько близки ее прогнозы к истине, модель учится аппроксимировать истинное распределение. В контексте дистилляции модели мы используем комбинацию различных функций потерь, которые служат для подгонки новой модели не только к данным, но и к ее учителю.
В отличие от других методов сжатия, таких как обрезка (которая создает модель меньшего размера за счет удаления избыточных весов), дистилляция не зависит как от модели, так и от оборудования: она работает из коробки для любой архитектуры модели и независимо от базового ЦП или процессора. Аппаратное обеспечение графического процессора. Однако, как вы увидите, ваш выбор метода дистилляции может повлиять на комбинацию учитель-ученик, которую вы можете использовать.
Какие типы дистилляции моделей существуют?
Есть две категории дистилляции моделей. Дистилляция слоя прогнозирования выполняется быстро, работает только с выходным слоем модели и почти не накладывает ограничений на комбинацию учитель-ученик. С другой стороны, дистилляция промежуточного слоя занимает гораздо больше времени и включает несколько более глубоких слоев модели. Рассмотрим оба метода подробнее.
Дистилляция прогнозного слоя
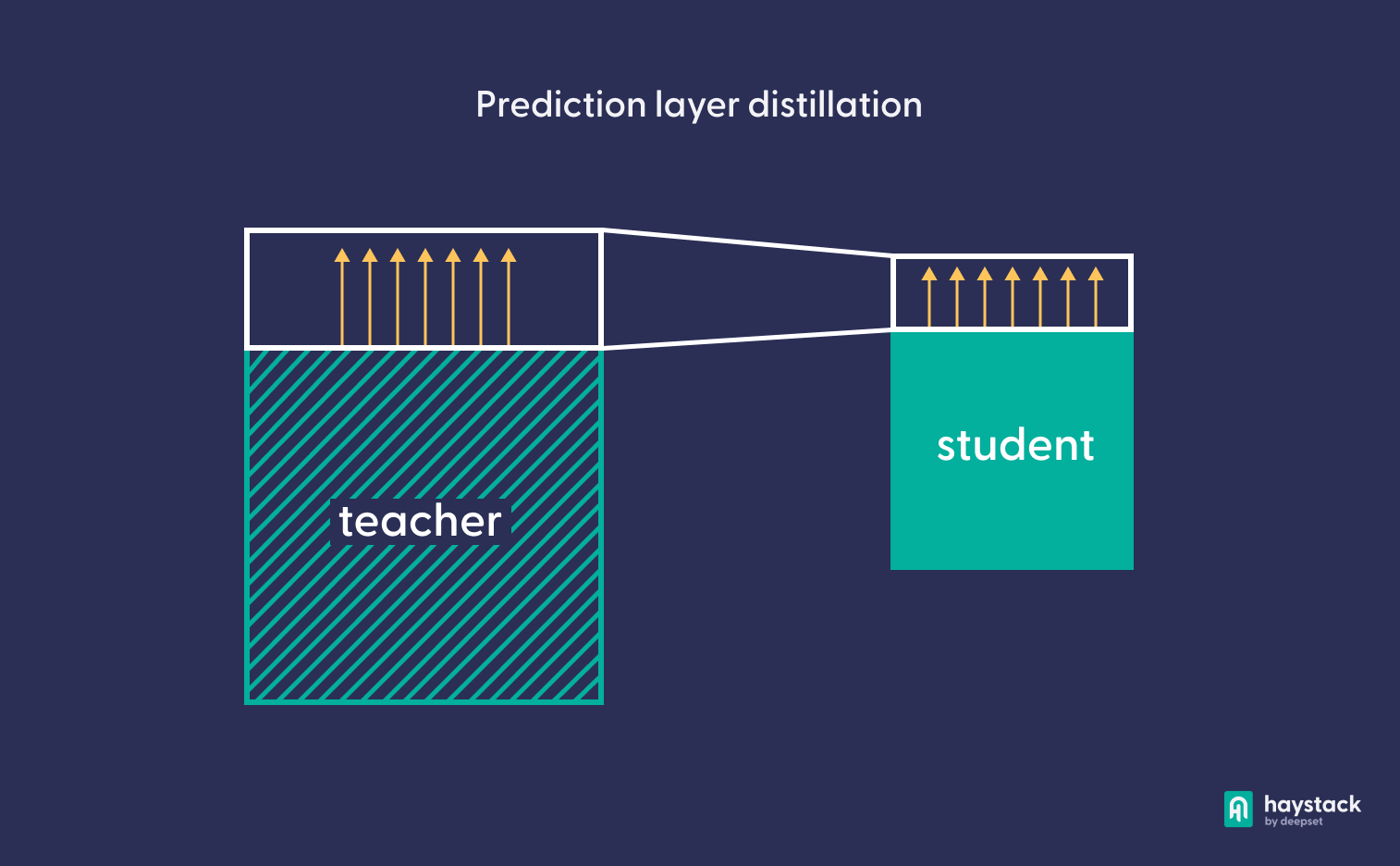
Первоначально предложенный в 2015 году Хинтоном и др., этот метод направлен на то, чтобы научить ученика аппроксимировать результаты слоя прогнозирования учителя. Он основан на осознании того, что в модели глубокого обучения знания о предметной области передаются не только верхним прогнозом модели, но и всем распределением вероятностей по выходным меткам. Если модель ученика научится аппроксимировать это распределение, она сможет успешно имитировать поведение модели учителя.
Перегонка слоя предсказания занимает пару часов на GPU, и есть два важных гиперпараметра, которые регулируют его поведение: температура и потеря веса перегонки.
Температура
Чтобы улучшить выразительность распределения выходных данных учителя, мы хотим, чтобы оно давало «мягкие», а не «жесткие», четкие прогнозы. При дистилляции модели мягкость предсказанных меток можно контролировать с помощью гиперпараметра, известного как температура. Более высокая температура приводит к более мягкому распределению.
Потери веса при перегонке
Этот параметр регулирует, насколько модель ученика во время дистилляции отдает приоритет выходным данным учителя по сравнению с реальными целями в обучающих данных. Он варьируется от 0 (используйте только ярлыки, игнорируйте предсказания учителя) до 1 (изучайте только поведение учителя, а не ярлыки).
Дистилляция промежуточного слоя
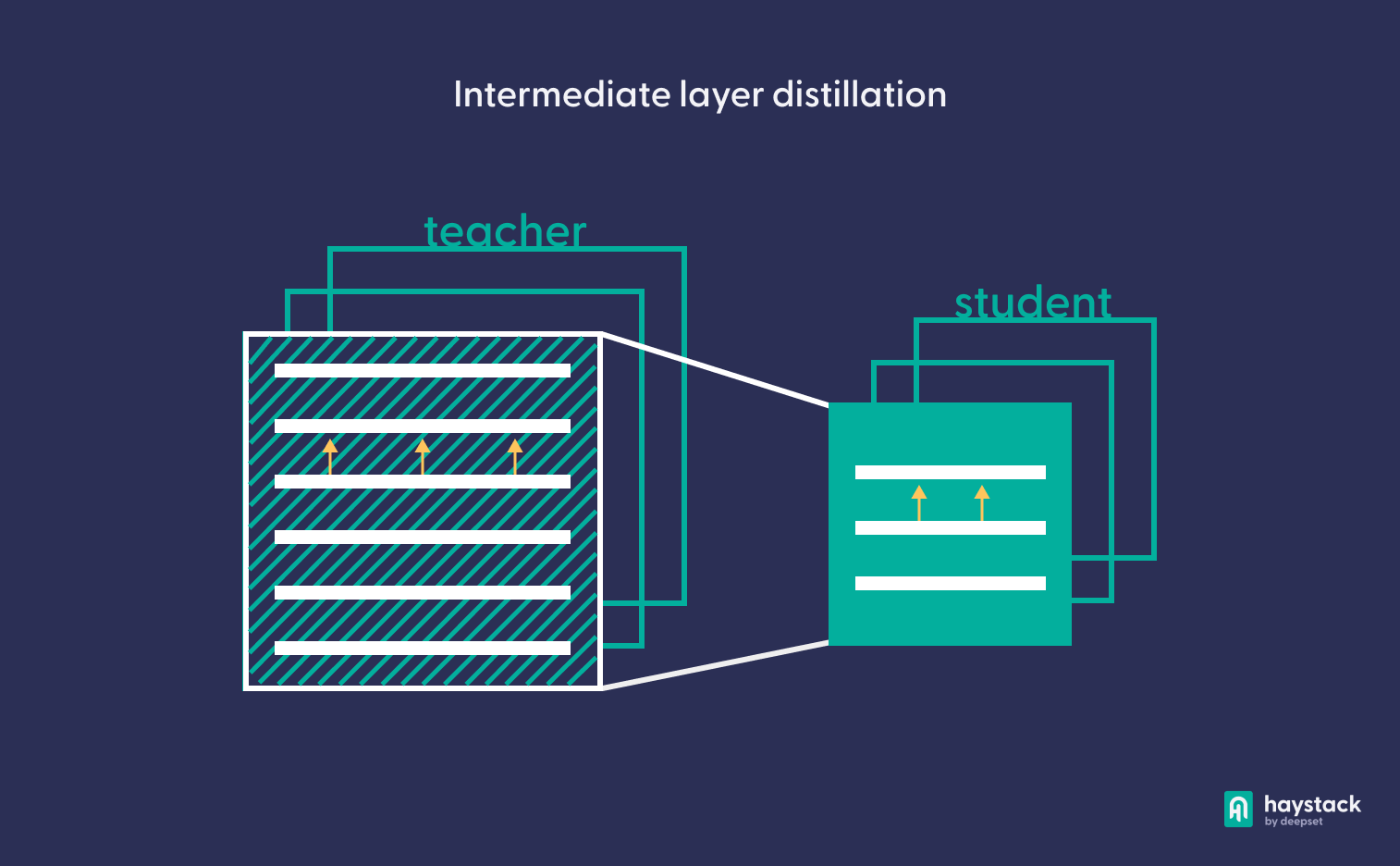
Основными строительными блоками в Transformers являются уровни внимания с несколькими головками, которые учатся фиксировать отношения между входными токенами. При дистилляции промежуточного слоя, предложенной Jiao et al., ученик учится аппроксимировать поведение учителя в отношении не только слоя прогнозирования, но также слоев внимания и внедрения.
Поскольку дистилляция промежуточного уровня включает в себя скрытые слои учителя, она работает только для пар учитель-ученик, которые имеют схожую архитектуру. Например, вы можете использовать BERT-base или BERT-large в качестве учителей для модели TinyBERT.
На практике этот метод требует двухэтапного процесса. На первом этапе модель перегоняется с использованием перегонки промежуточного слоя. Поскольку для этого шага требуется много данных, Haystack теперь предоставляет скрипт augment_squad(). Это позволяет вам искусственно увеличивать ваши данные с заданным коэффициентом перед выполнением дистилляции. На втором этапе мы просто используем дистилляцию слоя предсказания, как и раньше.
Мы рекомендуем предварять эту двухэтапную дистилляцию тонко настроенной модели промежуточным этапом дистилляции общей языковой модели. В этом сценарии, который показал наилучшие результаты в наших экспериментах, ваша процедура дистилляции фактически состоит из трех шагов:
- Дистилляция промежуточного слоя общей языковой модели на большом текстовом корпусе (например, Википедия).
- Дистилляция промежуточного слоя тонко настроенной модели для конкретной задачи с использованием искусственно дополненного набора данных SQuAD.
- Дистилляция уровня прогнозирования тонко настроенной модели с использованием нерасширенного набора данных SQuAD.
Такой подход занимает довольно много времени — три-четыре дня на четырех графических процессорах. Но инвестиции окупаются: ваша дистиллированная модель будет занимать меньше места и будет обрабатывать запросы намного быстрее, чем учитель, с более высокой точностью, чем можно было бы достичь с помощью только дистилляции слоя прогнозирования.
На следующей диаграмме показан размер некоторых моделей по сравнению с качеством их прогнозирования, измеряемым оценкой F1. Модель tinyroberta-squad2 примерно вдвое меньше своего учителя, roberta-base-squad2. Тем не менее, при 81,5 балла F1 учащегося почти такой же высокий, как у учителя (82,6), и он может обрабатывать запросы в два раза быстрее, чем более крупная модель.
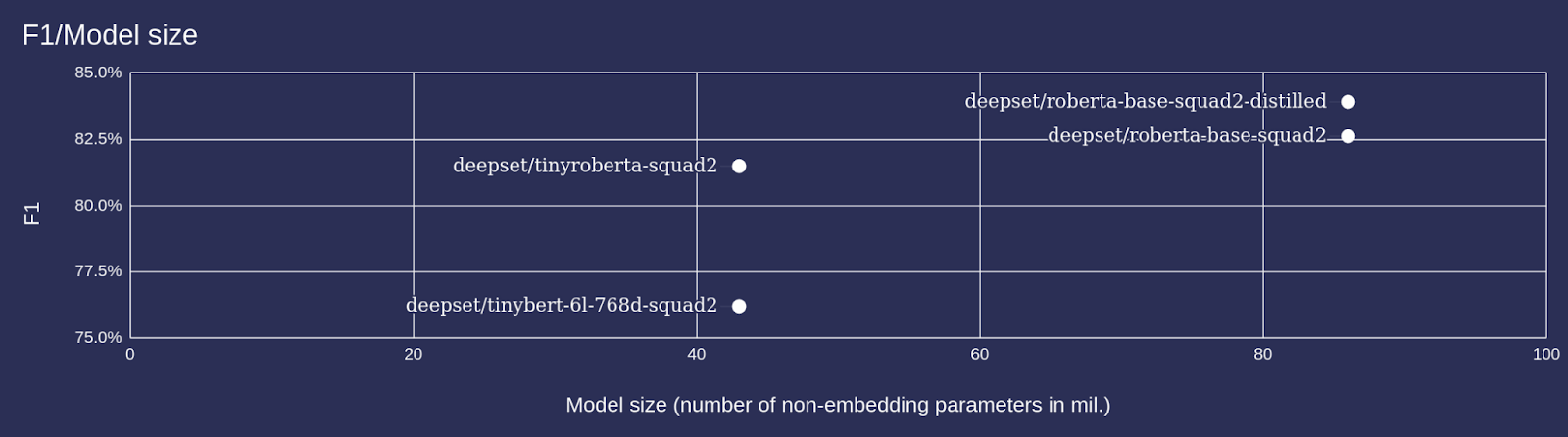
Кроме того, дистиллированная общеязыковая модель может использоваться повторно — она может служить основой для ряда последующих задач. Если вы хотите пропустить первый, затратный по вычислительным ресурсам шаг создания общеязыковой модели, вы даже можете загрузить нашу новую модель deepset/tinyroberta-6l-768d из Hugging Face Model Hub. Мы подготовили его специально для людей с ограниченными вычислительными ресурсами.
Начните с дистилляции модели
Если вы хотите узнать больше о двух типах дистилляции моделей, загляните на нашу страницу документации. На странице также приведены рекомендации по комбинациям учитель-ученик, которые вы можете использовать, оптимальные настройки гиперпараметров и некоторые статистические данные об улучшениях, которые вы можете ожидать от очистки ваших моделей.
Код для дистилляции промежуточного слоя и слоя прогнозирования содержится в этом руководстве по тонкой настройке модели. Блокнот иллюстрирует соответствующие шаги с помощью небольшого игрушечного набора данных. Обратите внимание, что, поскольку реальное приложение дистилляции промежуточного слоя занимает несколько дней на нескольких графических процессорах, мы не рекомендуем запускать его в ноутбуке Colab.
Если к настоящему моменту вы убеждены, что дистилляция моделей — это то, что нужно, но у вас нет времени или ресурсов для дистилляции ваших собственных моделей, вы можете просто использовать deepset/tinyroberta-squad2 вместо его более громоздкого учителя.
Наконец, если вы еще этого не сделали, загляните в Репозиторий Haystack на GitHub. А если у вас есть еще вопросы по дистилляции моделей или вы хотите узнать, что делают другие, обязательно присоединяйтесь к сообществу Haystack в Discord!