
Современные рекомендательные системы с нейронными сетями
Создавайте гибридные модели с помощью Python и TensorFlow
Краткое содержание
В этой статье я покажу, как создавать современные системы рекомендаций с нейронными сетями, используя Python и TensorFlow.

Системы рекомендаций – это модели, которые предсказывают предпочтения пользователей в отношении нескольких продуктов. Они используются в самых разных областях, таких как видео- и музыкальные сервисы, электронная коммерция и платформы социальных сетей.
Наиболее распространенные методы используют характеристики продукта (на основе контента), сходство пользователей (на основе совместной фильтрации), личную информацию (на основе знаний). Однако с ростом популярности нейронных сетей компании начали экспериментировать с новыми гибридными рекомендательными системами, которые объединяют их все.
В этом уроке я собираюсь показать, как использовать традиционные модели и как создать современную рекомендательную систему с нуля. Я представлю некоторый полезный код Python, который можно легко применить в других подобных случаях (просто скопируйте, вставьте, запустите) и пройдусь по каждой строке кода с комментариями, чтобы вы могли воспроизвести этот пример (ссылка на полный код ниже).
Я буду использовать набор данных MovieLens, содержащий тысячи фильмов, оцененных сотнями пользователей, созданный GroupLens Research (ссылка ниже).
В частности, я пройду:
- Настройка: импорт пакетов, чтение данных, предварительная обработка
- Проблема с холодным пуском
- Методы на основе содержимого с tensorflow и numpy
- Традиционная совместная фильтрация и нейронная совместная фильтрация с помощью tensorflow/keras
- Гибридная (контекстно-зависимая) модель с tensorflow/keras
Настраивать
Прежде всего, я импортирую следующие пакеты:
## for data import pandas as pd import numpy as np import re from datetime import datetime ## for plotting import matplotlib.pyplot as plt import seaborn as sns ## for machine learning from sklearn import metrics, preprocessing ## for deep learning from tensorflow.keras import models, layers, utils #(2.6.0)
Затем я прочитаю данные, как данные о продуктах (в данном случае о фильмах), так и данные о пользователях.
dtf_products = pd.read_excel("data_movies.xlsx", sheet_name="products")
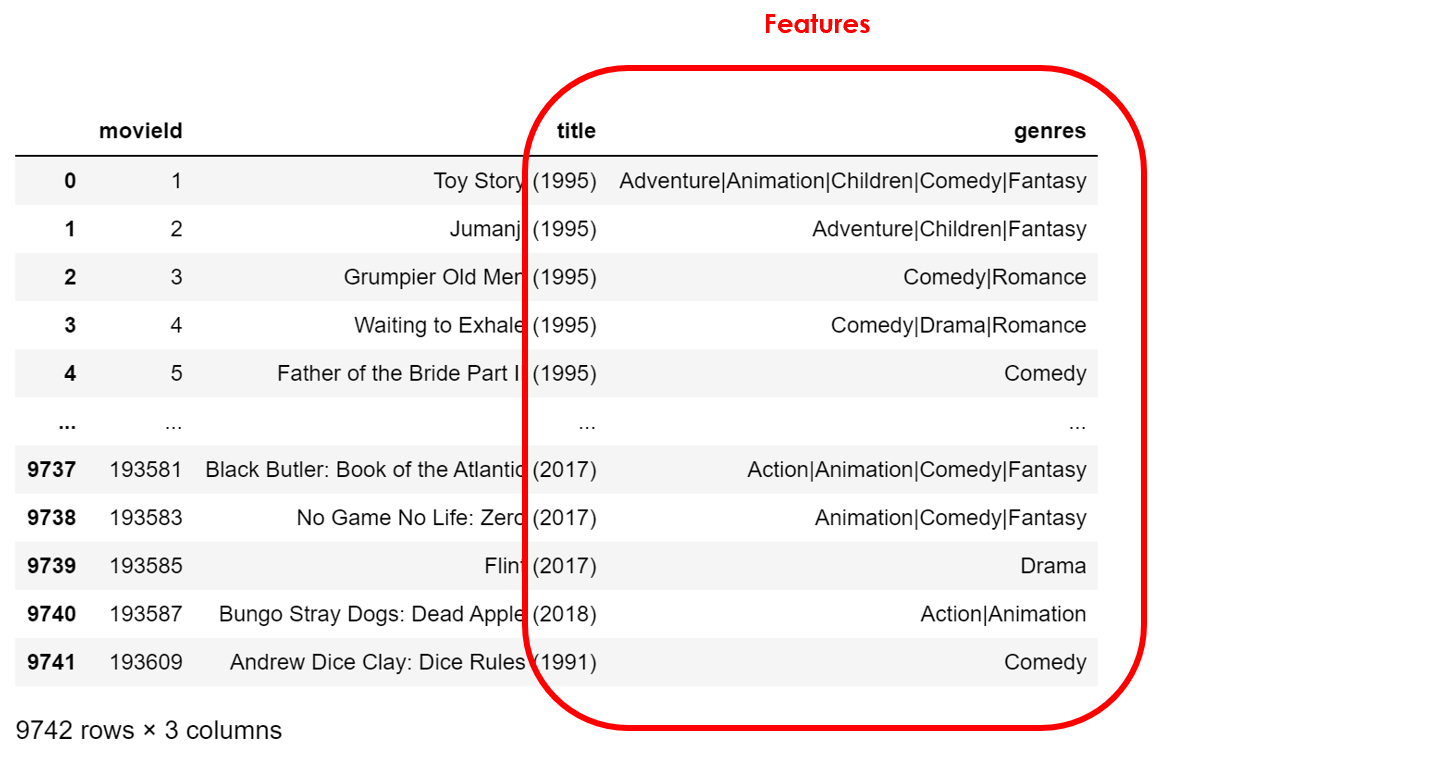
В таблице продуктов каждая строка представляет элемент, а два столбца справа содержат его характеристики, которые являются статическими (вы можете видеть их как метаданные фильма). Прочитаем пользовательские данные:
dtf_users = pd.read_excel("data_movies.xlsx", sheet_name="users").head(10000)
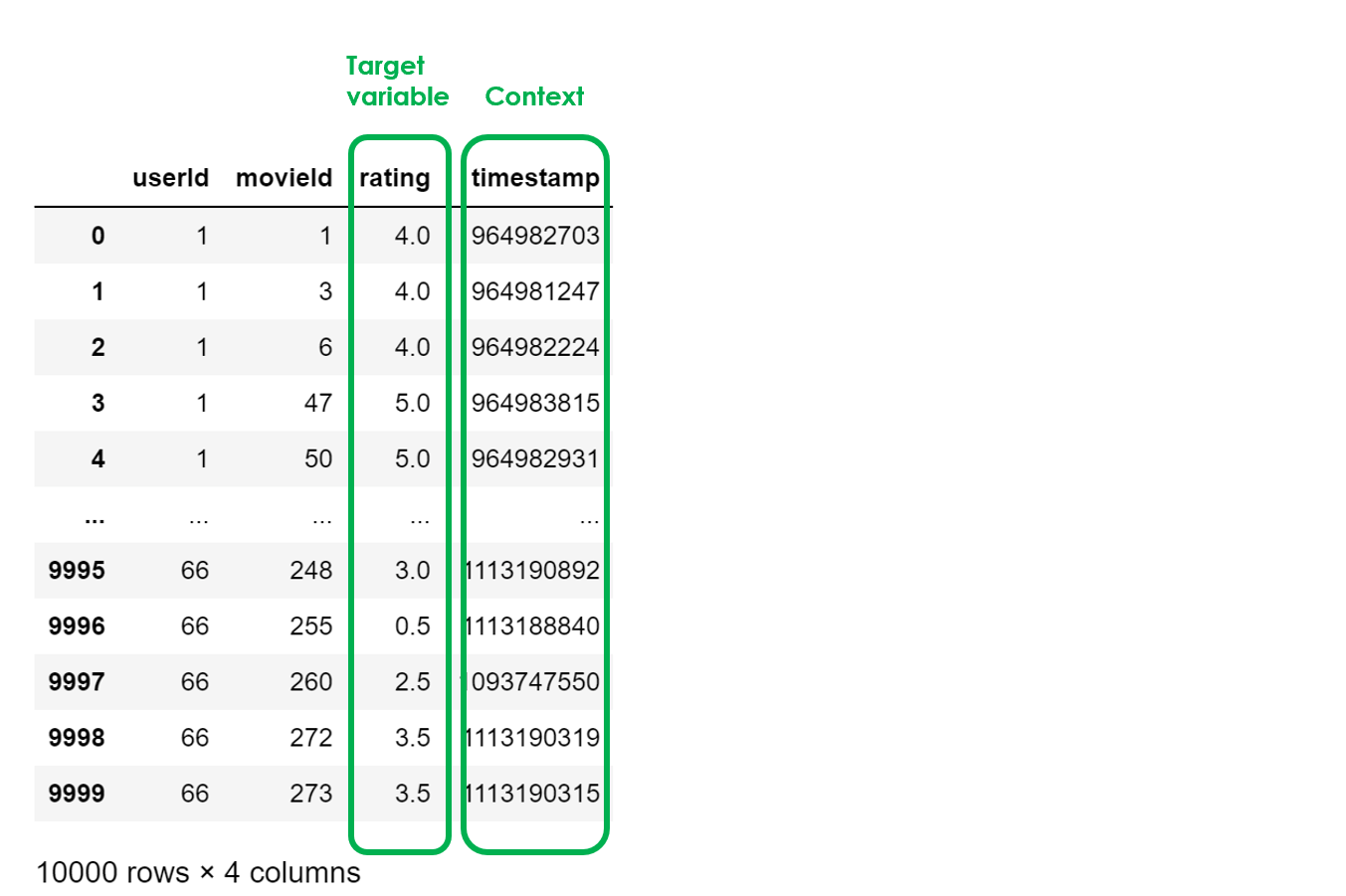
Каждая строка этой другой таблицы представляет собой пару пользователь-продукт и показывает оценку, которую пользователи дали продуктам, что является целевой переменной. Очевидно, что не каждый пользователь видел все товары. Собственно, поэтому нам и нужны рекомендательные системы. Они должны предсказать, какой рейтинг пользователь даст новому продукту, и если прогнозируемый рейтинг высокий/положительный, то он рекомендуется. Кроме того, здесь также есть кусочки информации, касающиеся контекста целевой переменной (когда пользователь поставил оценку).
Давайте проведем очистку данных и разработку функций, чтобы лучше понять, что у нас есть и как мы можем это использовать.
# Products
dtf_products = dtf_products[~dtf_products["genres"].isna()]
dtf_products["product"] = range(0,len(dtf_products))
dtf_products["name"] = dtf_products["title"].apply(lambda x: re.sub("[\(\[].*?[\)\]]", "", x).strip())
dtf_products["date"] = dtf_products["title"].apply(lambda x: int(x.split("(")[-1].replace(")","").strip())
if "(" in x else np.nan)
dtf_products["date"] = dtf_products["date"].fillna(9999)
dtf_products["old"] = dtf_products["date"].apply(lambda x: 1 if x < 2000 else 0)
# Users
dtf_users["user"] = dtf_users["userId"].apply(lambda x: x-1)
dtf_users["timestamp"] = dtf_users["timestamp"].apply(lambda x: datetime.fromtimestamp(x))
dtf_users["daytime"] = dtf_users["timestamp"].apply(lambda x: 1 if 6<int(x.strftime("%H"))<20 else 0)
dtf_users["weekend"] = dtf_users["timestamp"].apply(lambda x: 1 if x.weekday() in [5,6] else 0)
dtf_users = dtf_users.merge(dtf_products[["movieId","product"]], how="left")
dtf_users = dtf_users.rename(columns={"rating":"y"})
# Clean
dtf_products = dtf_products[["product","name","old","genres"]].set_index("product")
dtf_users =
dtf_users[["user","product","daytime","weekend","y"]]

Обратите внимание, что я извлек 2 переменные контекста из столбца отметка времени: дневное время и выходные дни. Я сохраню их в фрейме данных, так как они могут нам понадобиться позже.
dtf_context = dtf_users[["user","product","daytime","weekend"]]
Что касается продуктов, следующим шагом будет создание матрицы Products-Features:
tags = [i.split("|") for i in dtf_products["genres"].unique()]
columns = list(set([i for lst in tags for i in lst]))
columns.remove('(no genres listed)')
for col in columns:
dtf_products[col] = dtf_products["genres"].apply(lambda x: 1 if col in x else 0)

Матрица разрежена, так как большинство продуктов не имеют всех функций. Давайте визуализируем это, чтобы лучше понять ситуацию.
fig, ax = plt.subplots(figsize=(20,5))
sns.heatmap(dtf_products==0, vmin=0, vmax=1, cbar=False, ax=ax).set_title("Products x Features")
plt.show()

Разреженность становится еще хуже с матрицей Пользователи-Продукты:
tmp = dtf_users.copy()
dtf_users = tmp.pivot_table(index="user", columns="product", values="y")
missing_cols = list(set(dtf_products.index) - set(dtf_users.columns))
for col in missing_cols:
dtf_users[col] = np.nan
dtf_users = dtf_users[sorted(dtf_users.columns)]


Последним шагом перед изучением моделей является предварительная обработка. Поскольку мы будем иметь дело с нейронными сетями, всегда рекомендуется масштабировать данные.
dtf_users = pd.DataFrame(preprocessing.MinMaxScaler(feature_range=(0.5,1)).fit_transform(dtf_users.values), columns=dtf_users.columns, index=dtf_users.index)

Наконец, мы разделим данные на наборы train и test. Я собираюсь разбить набор данных по вертикали, чтобы все пользователи участвовали как в обучении, так и в тестировании, в то время как 80 % продуктов остаются для обучения, а 20 % для тестирования. Так:

split = int(0.8*dtf_users.shape[1]) dtf_train = dtf_users.loc[:, :split-1] dtf_test = dtf_users.loc[:, split:]
Хорошо, теперь мы можем начать… может быть.
Холодный запуск
Представьте, что у вас есть совершенно новое приложение, похожее на Netflix, и первый пользователь подписывается. Мы должны иметь возможность предлагать рекомендации независимо от предыдущих взаимодействий пользователя, поскольку ни одно из них еще не было записано. Когда пользователь (или продукт) новый, возникает проблема холодного запуска. Система не может сформировать какую-либо связь между пользователями и продуктами, потому что у нее недостаточно данных.
Чтобы решить эту проблему, основным методом является подход, основанный на знаниях: например, запрос предпочтений пользователя для создания начального профиля или использование демографической информации (например, школьные шоу для подростков). и мультфильмы для детей).
Если пользователей немного, можно работать с Content-Based методами. Затем, когда у нас будет достаточно оценок (т. е. не менее 10 продуктов на пользователя и более 100 пользователей в целом), можно будет применять более сложные модели.
Контент-ориентированный
Методы, основанные на содержании основаны на содержании продукта. Например, если Пользователю А нравится Продукт 1,и Продукт 2 похож на Продукт 1, тогда Пользователю А, вероятно, также понравится Продукт 2. Два продукта похожи, если они имеют схожие характеристики.
В двух словах, идея состоит в том, что пользователи на самом деле оценивают характеристики продукта, а не сам продукт. Другими словами, если мне нравятся продукты, связанные с музыкой и искусством, это потому, что мне нравятся эти функции (музыка и искусство). Исходя из этого, мы можем оценить, насколько я хотел бы другие продукты с такими же функциями. Этот метод лучше всего подходит для ситуаций, когда известны данные о продуктах, но нет данных о пользователях.
Давайте выберем одного пользователя из данных в качестве примера нашего первого подписчика, который уже использовал достаточно продуктов, и создадим векторы train и test.
# Select a user i = 1 train = dtf_train.iloc[i].to_frame(name="y") test = dtf_test.iloc[i].to_frame(name="y") # add all the test products but hide the y tmp = test.copy() tmp["y"] = np.nan train = train.append(tmp)
Теперь нам нужно оценить веса, которые пользователь присваивает каждой функции. У нас есть вектор User-Products и матрица Products-Features.
# shapes
usr = train[["y"]].fillna(0).values.T
prd = dtf_products.drop(["name","genres"],axis=1).values
print("Users", usr.shape, " x Products", prd.shape)

Умножая эти два объекта, мы получаем вектор User-Features, содержащий оценочные веса, которые этот пользователь присваивает каждой функции. Эти веса должны повторно применяться к матрице Products-Features, чтобы получить прогнозируемые рейтинги.
# usr_ft(users,fatures) = usr(users,products) x prd(products,features) usr_ft = np.dot(usr, prd) # normalize weights = usr_ft / usr_ft.sum() # predicted rating(users,products) = weights(users,fatures) x prd.T(features,products) pred = np.dot(weights, prd.T) test = test.merge(pd.DataFrame(pred[0], columns=["yhat"]), how="left", left_index=True, right_index=True).reset_index() test = test[~test["y"].isna()] test

Как видите, я разработал этот простой подход, используя просто numpy. То же самое можно сделать, используя только необработанный tensorflow:
import tensorflow as tf # usr_ft(users,fatures) = usr(users,products) x prd(products,features) usr_ft = tf.matmul(usr, prd) # normalize weights = usr_ft / tf.reduce_sum(usr_ft, axis=1, keepdims=True) # rating(users,products) = weights(users,fatures) x prd.T(features,products) pred = tf.matmul(weights, prd.T)
Как оценить наши прогнозируемые рекомендации? Я обычно применяю Точность и Средний обратный ранг (MRR). Последнее является статистической мерой для оценки любого списка возможных ответов, упорядоченных по вероятности правильности.
def mean_reciprocal_rank(y_test, predicted):
score = []
for product in y_test:
mrr = 1 / (list(predicted).index(product) + 1) if product
in predicted else 0
score.append(mrr)
return np.mean(score)
Обратите внимание, что показатели меняются в зависимости от количества продуктов, которые мы рекомендуем. Поскольку мы сравниваем наши предсказанные элементы top k с элементами в наборе test, порядок также имеет значение.
print("--- user", i, "---")
top = 5
y_test = test.sort_values("y", ascending=False)["product"].values[:top]
print("y_test:", y_test)
predicted = test.sort_values("yhat", ascending=False)["product"].values[:top]
print("predicted:", predicted)
true_positive = len(list(set(y_test) & set(predicted)))
print("true positive:", true_positive, "("+str(round(true_positive/top*100,1))+"%)")
print("accuracy:", str(round(metrics.accuracy_score(y_test,predicted)*100,1))+"%")
print("mrr:", mean_reciprocal_rank(y_test, predicted))

У нас есть 4 товара, но заказ не совпадает. Вот почему Точность и MRR низкие.
# See predictions details
test.merge(
dtf_products[["name","old","genres"]], left_on="product",
right_index=True
).sort_values("yhat", ascending=False)

Совместная фильтрация
Совместная фильтрация основана на предположении, что схожим пользователям нравятся похожие продукты. Например, если Пользователю А нравится Товар 1, а Пользователь Б похож на Пользователь А, тогда Пользователю Б, вероятно, также понравится Товар 1. Два пользователя похожи, если им нравятся похожие продукты.

Для работы этого метода не нужны функции продукта, вместо этого требуется множество оценок от многих пользователей. Чтобы продолжить пример нашей платформы, представьте, что наш первый подписчик больше не одинок, и у нас достаточно пользователей, чтобы применить эту модель.
Коллаборативная фильтрация обрела популярность, когда Netflix провел открытый конкурс (2009 г.) на лучший алгоритм, и люди придумали несколько реализаций. Их можно объединить в 2 семейства:
- На основе памяти — поиск похожих пользователей с помощью показателей корреляции, косинусного сходства и кластеризации.
- На основе модели – предскажите, как пользователи оценят определенный продукт, применяя машинное обучение с учителем и матричную факторизацию, которая разбивает большую матрицу Пользователи-продукты на 2 меньших фактора, представляющих матрица Пользователи и матрица Продукты.
В Python наиболее удобным для пользователя пакетом является surprise, простая библиотека для построения и анализа рекомендательных систем с явными рейтинговыми данными (аналогично scikit-learn). Его можно использовать как для подходов на основе памяти, так и для моделей. В качестве альтернативы можно использовать tensorflow/keras для создания вложений для более сложного подхода на основе моделей, что я и собираюсь сделать.
Прежде всего, нам необходимо иметь данные в следующем виде:
train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
train.head()

Основная идея состоит в том, чтобы использовать уровень встраивания нейронной сети для создания матриц Пользователи и Продукты. Важно понимать, что входные данные — это пары «пользователь-продукт», а выходные данные — рейтинг. При прогнозировании новой пары «пользователь-продукт» модель будет искать пользователя в пространстве внедрения Пользователи и продукт в пространстве Продукты . По этой причине вам необходимо заранее указать общее количество пользователей и продуктов.
embeddings_size = 50 usr, prd = dtf_users.shape[0], dtf_users.shape[1] # Users (1,embedding_size) xusers_in = layers.Input(name="xusers_in", shape=(1,)) xusers_emb = layers.Embedding(name="xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in) xusers = layers.Reshape(name='xusers', target_shape=(embeddings_size,))(xusers_emb) # Products (1,embedding_size) xproducts_in = layers.Input(name="xproducts_in", shape=(1,)) xproducts_emb = layers.Embedding(name="xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in) xproducts = layers.Reshape(name='xproducts', target_shape=(embeddings_size,))(xproducts_emb) # Product (1) xx = layers.Dot(name='xx', normalize=True, axes=1)([xusers, xproducts]) # Predict ratings (1) y_out = layers.Dense(name="y_out", units=1, activation='linear')(xx) # Compile model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="CollaborativeFiltering") model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
Обратите внимание, что я рассматриваю этот вариант использования как проблему регрессии, используя Среднюю абсолютную ошибку в качестве потери, даже если в конце концов нам понадобится не сама оценка, а сортировка предсказанных продуктов.
utils.plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)

Давайте обучим и протестируем модель.
# Train training = model.fit(x=[train["user"], train["product"]], y=train["y"], epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3) model = training.model # Test test["yhat"] = model.predict([test["user"], test["product"]]) test

Мы можем оценить прогнозы, сравнив рекомендации, созданные для нашего любимого первого пользователя (тот же код, что и раньше):

В настоящее время все современные рекомендательные системы используют глубокое обучение. В частности, Neural Collaborative Filtering (2017) объединяет нелинейность нейронных сетей и матричную факторизацию. Модель разработана таким образом, чтобы максимально эффективно использовать пространство для встраивания, используя его не только для традиционной совместной фильтрации, но и для полностью подключенной глубокой нейронной сети. Дополнительная часть должна фиксировать шаблоны и функции, которые могут быть упущены при матричной факторизации.

В терминах Python:
embeddings_size = 50 usr, prd = dtf_users.shape[0], dtf_users.shape[1] # Input layer xusers_in = layers.Input(name="xusers_in", shape=(1,)) xproducts_in = layers.Input(name="xproducts_in", shape=(1,)) # A) Matrix Factorization ## embeddings and reshape cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in) cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb) ## embeddings and reshape cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in) cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb) ## product cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts]) # B) Neural Network ## embeddings and reshape nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in) nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb) ## embeddings and reshape nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in) nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb) ## concat and dense nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts]) nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx) # Merge A & B y_out = layers.Concatenate()([cf_xx, nn_xx]) y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out) # Compile model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="Neural_CollaborativeFiltering") model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])

Вы можете запустить его, используя тот же код, что и раньше, и проверить, работает ли он лучше, чем традиционная совместная фильтрация.

Гибридная модель
Давайте начнем с краткого обзора того, какие данные предлагает реальный мир:
- Целевая переменная — рейтинги могут быть явными (т. е. пользователь оставляет отзыв) или неявными (т. е. предполагать положительный отзыв, если пользователь просматривает фильм целиком), в любом случае они необходимы.
- Характеристики товара — теги и описания элементов (т. е. жанров фильмов), в основном используемые в методах на основе контента.
- Профиль пользователя — описательная информация о пользователях может быть демографической (например, пол и возраст) или поведенческой (например, предпочтения, среднее время на экране, наиболее частое время использования), в основном используется для рекомендаций, основанных на знаниях.
- Контекст — дополнительная информация о ситуации вокруг рейтинга (т. е. когда, где, история поиска), также часто включаемая в рекомендации, основанные на знаниях.
Современные рекомендательные системы объединяют их все, когда делают прогноз о нашем вкусе. Например, YouTube рекомендует следующее видео, используя все, что Google знает о вас, а они знают очень много.
В этом примере у меня есть характеристики продукта и данные о том, когда пользователь поставил оценку, которые я собираюсь использовать в качестве контекста (в качестве альтернативы их можно использовать для создания профиля пользователя).
features = dtf_products.drop(["genres","name"], axis=1).columns print(features) context = dtf_context.drop(["user","product"], axis=1).columns print(context)

Давайте добавим эту дополнительную информацию в набор train:
train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
## add features
train = train.merge(dtf_products[features], how="left", left_on="product", right_index=True)
## add context
train = train.merge(dtf_context, how="left")

Обратите внимание, что вы можете сделать то же самое для тестового набора, но если вы хотите имитировать реальное производство, вы должны вставить статическое значение для контекста. Проще говоря, если мы делаем прогнозы для пользователя нашей платформы на вечер понедельника, контекстная переменная должна быть daytime=0 и weekend=0.
Теперь у нас есть все ингредиенты для создания гибридной модели с учетом контекста. Гибкость нейронных сетей позволяет нам добавлять все, что мы захотим, поэтому я возьму сетевую структуру Neural Collaborative Filtering и включу в нее как можно больше модулей.
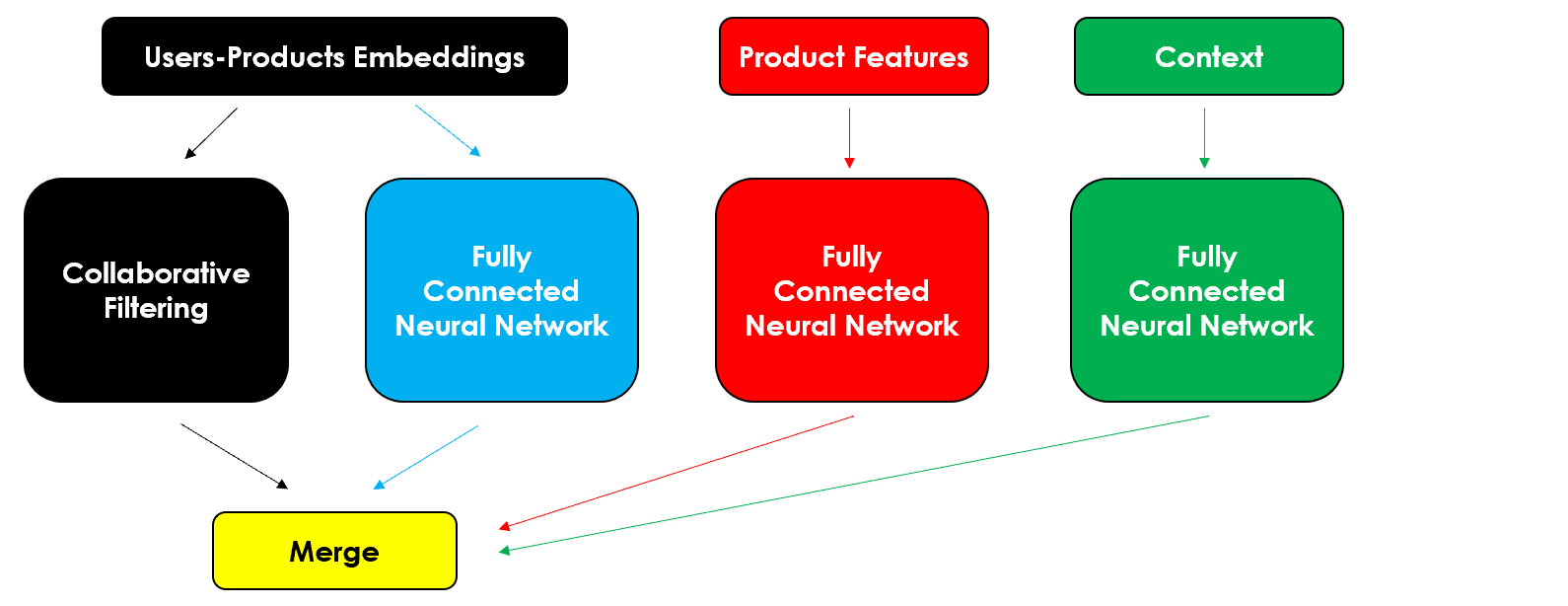
Несмотря на код, который может показаться сложным, мы просто добавляем несколько слоев к тому, что уже использовали.
embeddings_size = 50 usr, prd = dtf_users.shape[0], dtf_users.shape[1] feat = len(features) ctx = len(context) ################### COLLABORATIVE FILTERING ######################## # Input layer xusers_in = layers.Input(name="xusers_in", shape=(1,)) xproducts_in = layers.Input(name="xproducts_in", shape=(1,)) # A) Matrix Factorization ## embeddings and reshape cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in) cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb) ## embeddings and reshape cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in) cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb) ## product cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts]) # B) Neural Network ## embeddings and reshape nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in) nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb) ## embeddings and reshape nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in) nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb) ## concat and dense nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts]) nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx) ######################### CONTENT BASED ############################ # Product Features features_in = layers.Input(name="features_in", shape=(feat,)) features_x = layers.Dense(name="features_x", units=feat, activation='relu')(features_in) ######################## KNOWLEDGE BASED ########################### # Context contexts_in = layers.Input(name="contexts_in", shape=(ctx,)) context_x = layers.Dense(name="context_x", units=ctx, activation='relu')(contexts_in) ########################## OUTPUT ################################## # Merge all y_out = layers.Concatenate()([cf_xx, nn_xx, features_x, context_x]) y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out) # Compile model = models.Model(inputs=[xusers_in,xproducts_in, features_in, contexts_in], outputs=y_out, name="Hybrid_Model") model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
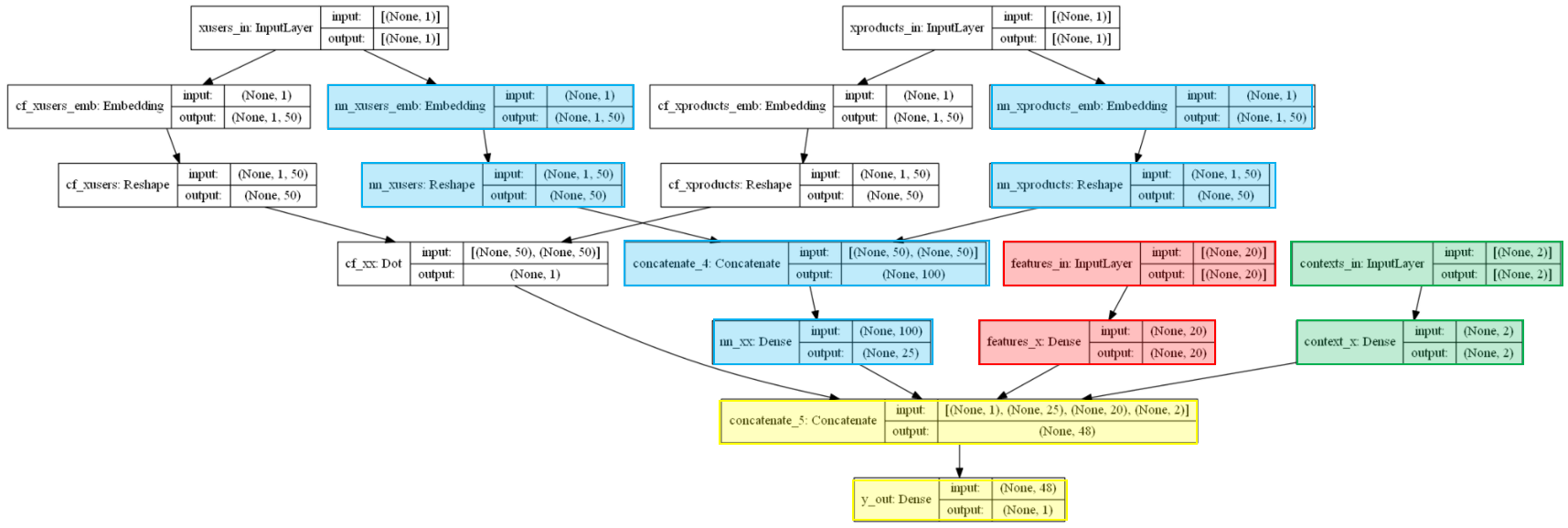
Эта гибридная модель требует большего количества входных данных, поэтому не забудьте также ввести новые данные:
# Train
training = model.fit(x=[train["user"], train["product"], train[features], train[context]], y=train["y"],
epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# Test
test["yhat"] = model.predict([test["user"], test["product"], test[features], test[context]])

По сравнению с другими методами для этого конкретного пользователя гибридная модель получила самую высокую точность, поскольку три прогнозируемых продукта имеют совпадающие заказы.
Заключение
Эта статья была учебным пособием, демонстрирующим, как проектировать и создавать рекомендательные системы с нейронными сетями. Мы рассмотрели различные варианты использования в зависимости от доступности данных: применили подход, основанный на содержании, для однопользовательского сценария, и погрузился в приложения совместной фильтрации для нескольких пользовательских продуктов. Что еще более важно, мы поняли, как использовать нейронные сети для улучшения традиционных методов и создания современных гибридных систем рекомендаций, которые могут включать контекст и любую другую дополнительную информацию.
Надеюсь, вам понравилось! Не стесняйтесь обращаться ко мне за вопросами и отзывами или просто поделиться своими интересными проектами.
👉 Давайте на связи 👈
Эта статья является частью серии статей Машинное обучение с помощью Python, см. также: