
Добро пожаловать в очередной пост о Python. Сегодняшняя тема посвящена тому, как создать нейронную сеть с прямой связью на Python с нуля. Это означает, что без использования Tensorflow, Keras, Pytorch и т. д. Основная библиотека, которую мы будем использовать, — это numpy, вычислительная библиотека для Python.
Обычно мне нравится понимать основные концепции того, как все работает, прежде чем использовать такой инструмент, как Tensorflow, для обработки вещей за меня. Выполнение этого самостоятельно позволяет мне лучше изучить концепции и иметь более прочную основу для реализации. В частности, я хотел бы рассказать о некоторых концепциях линейной алгебры, лежащих в основе работы глубоких нейронных сетей.
Существует много типов искусственных нейронных сетей: сверточные, полносвязные, рекуррентные и т. д. Этот пост посвящен полностью связанным сетям с прямой связью и тому, как они работают.
Ресурсы
Если вы ищете отличный ресурс по машинному обучению, я рекомендую третье издание книги О’Рейли Орельена Жерона: Практическое машинное обучение с помощью Scikit-Learn, Keras & Tensorflow. Новое издание вышло в октябре 2022 года и содержит более актуальную информацию о трансформаторах и диффузионных моделях. Он также охватывает такие темы, как контролируемое и неконтролируемое обучение, случайные леса, глубокое обучение, обработка естественного языка, обучение и развертывание моделей TensorFlow, а также многие другие темы.
Так что, если вам интересно, вы можете получить это здесь по моей реферальной ссылке. Цена такая же для вас, но я могу получить комиссию.
Еще одна вещь, которая мне нравится в книге, это то, что она включает сквозной проект машинного обучения, чтобы изучить весь процесс работы специалиста по данным.
Что такое нейронные сети?
Искусственные нейронные сети пытаются имитировать работу человеческого мозга. Есть «нейроны», которые сами выполняют простые вычисления. Однако, складывая вместе слои этих «нейронов», нейронная сеть может демонстрировать сложное и неожиданное поведение.
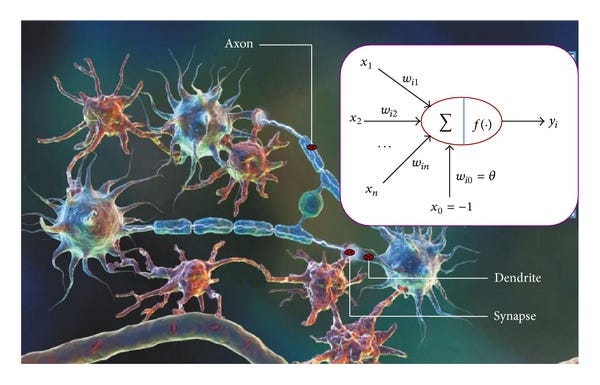
Конечно, человеческий мозг гораздо сложнее, но аналогия делает его простым для понимания.
Математически искусственные нейронные сети — это функции, которые принимают входные данные и производят выходные данные. Их называют универсальными аппроксиматорами функций, потому что с соответствующими весами и обучением они могут аппроксимировать поведение широкого круга функций.
Нейронные сети как матрицы
Когда у нас есть основная концепция искусственных нейронных сетей, нам нужно найти способ представить их в коде. Для меня наиболее естественным способом сделать это является использование матриц из линейной алгебры.
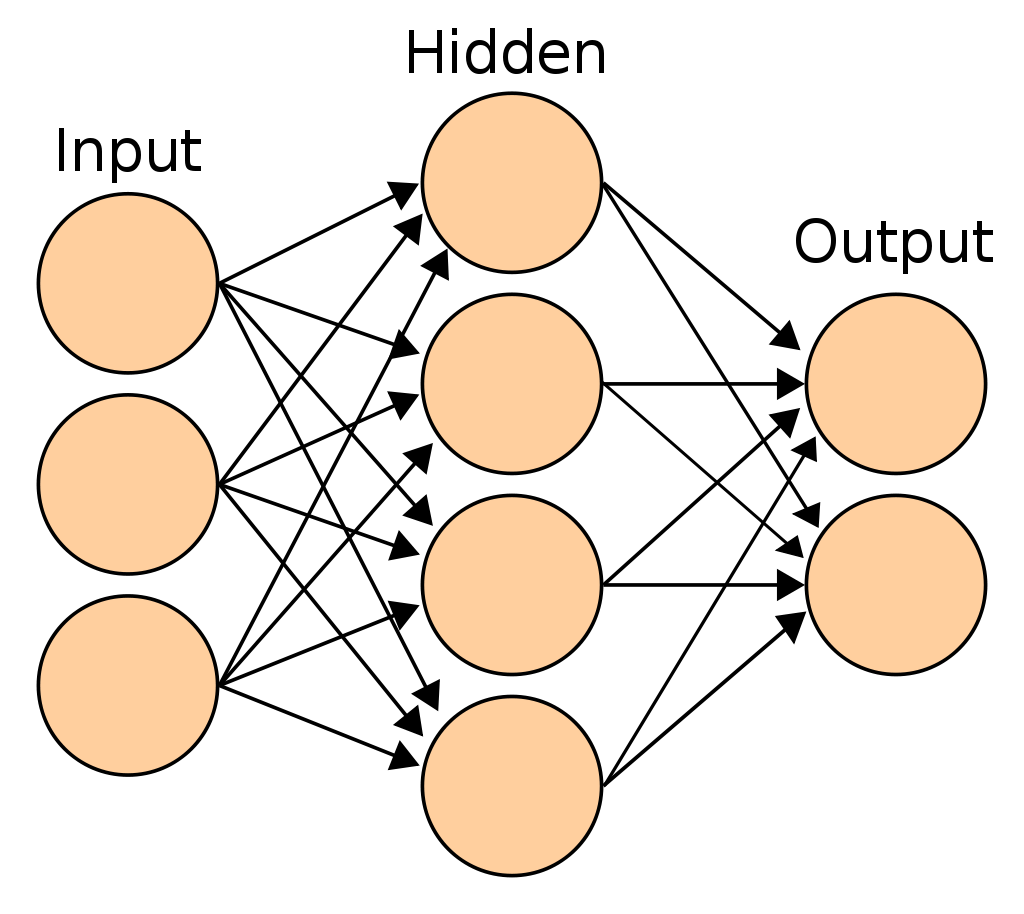
Давайте используем эту сеть, чтобы показать в качестве примера. Всего у нас 3 слоя. Есть входной слой с 3 узлами, затем один скрытый слой с 4 узлами. Наконец, у нас есть выходной слой с двумя узлами или нейронами.
В полностью связанной нейронной сети с прямой связью каждый нейрон в слое имеет связь со всеми нейронами в следующем слое. Кроме того, каждое соединение имеет вес (число), связанный с ним. Это число обычно устанавливается случайным образом в начале, а затем уточняется на этапе обучения (обучения).
Мы можем представить эту сеть как серию матриц, где каждая строка представляет собой узел, а каждый столбец — это соединение с узлами следующего слоя.
Например, в примере сети на изображении у нас будет всего 2 матрицы. Первая матрица представляет связи между входным слоем и скрытым слоем, в результате получается матрица 3×4.

У нас есть 3 строки, по одной для каждого входного узла, и значения в этой строке — это все соединения от этого входного узла ко всем скрытым узлам в следующем слое. Мы делаем то же самое для следующих двух слоев (L2 и L3), в результате чего получается матрица 4×2.
Нейронная сеть с прямой связью в коде Python
В Python мы могли бы представить сеть в виде класса, и если вам нужно освежить в памяти классы Python, ознакомьтесь с моим предыдущим постом. Вот простая реализация:
import numpy as np
class NeuralNet(object):
RNG = np.random.default_rng()
def __init__(self, topology:list[int] = []):
self.topology = topology
self.weight_mats = []
self._init_matrices()
def _init_matrices(self):
#-- set up matrices
if len(self.topology) > 1:
j = 1
for i in range(len(self.topology)-1):
num_rows = self.topology[i]
num_cols = self.topology[j]
mat = self.RNG.random(size=(num_rows, num_cols))
self.weight_mats.append(mat) j += 1
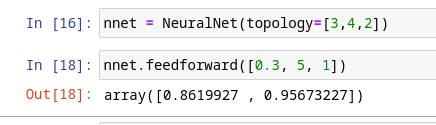
Для нашего примерного изображения мы бы передали следующие значения: потому что у нас есть 3 входных узла, 4 узла в скрытом слое и 2 в выходном слое. Каждый элемент в topology представляет другой слой.
Матрицы инициализируются случайными значениями. Я не уделял особого внимания методу инициализации, потому что он не является предметом поста. Тем не менее, это может иметь большое влияние на время обучения, если веса не инициализированы с некоторой осторожностью. Я раскрою эту тему в следующем посте.
Распространение с прямой связью
Нейронная сеть «думает», когда мы подаем ей какие-то входные данные и позволяем потоку информации перебрасывать слои, пока не достигнет выходного слоя. Этот поток является распространением с прямой связью, и он включает в себя некоторую простую линейную алгебру, в частности, матричное умножение и скалярное произведение.
Умножение матриц и скалярное произведение
При выполнении умножения матриц следует помнить, что внутренние стороны обеих матриц должны быть одинакового размера. Это требование существует из-за скалярного произведения (объяснено ниже). Вот что я имею в виду:
Предположим, у нас есть две матрицы: матрица A и матрица B.
Матрица A имеет размер 4 × 3 (4 строки и 3 столбца), а матрица B — 3 × 5 (3 строки и 5 столбцов). Мы можем сделать это умножение, потому что внутренний размер обеих матриц равен 3.

Результатом этого умножения будет новая матрица T размером 4×5 (внешние размеры исходных матриц). В общем, если у вас есть матрица размера NxG и другая матрица размера GxM, вы можете перемножить их, и их результатом будет матрица размера NxM.
Затем фактический процесс умножения включает в себя повторяющиеся операции скалярного произведения. У Numpy есть функция для этого, но мы кратко расскажем о ней.
Для скалярного произведения вам нужны два вектора (одномерные массивы), по одному из каждой матрицы. Начнем с того, что возьмем первую строку матрицы А и первый столбец матрицы В.

Затем мы умножаем каждый из их элементов и складываем их вместе в одно число.


Приведенное выше скалярное произведение даст первый элемент результирующей матрицы T или элемент t00.
Умножение матриц с помощью NumPy
>>> import numpy as np
>>> A = np.random.rand(3,4)
>>> A
array([[0.58117773, 0.4367495 , 0.17583791, 0.97634689],
[0.81055793, 0.84320293, 0.32176276, 0.05177668],
[0.57115715, 0.44588042, 0.07577211, 0.7077594 ]])
>>> B = np.random.rand(4,5)
>>> B
array([[0.41545468, 0.60417725, 0.37690862, 0.18888787, 0.5116385],
[0.03382709, 0.01476612, 0.90917151, 0.8484174 , 0.8438094],
[0.67937006, 0.23757462, 0.23856111, 0.06583954, 0.5626110],
[0.51240073, 0.83905954, 0.29712731, 0.68606154, 0.0547106]])
>>> T = np.dot(A, B)
>>> T.shape
(3, 5)
>>> T
array([[0.87596684, 1.21857125, 0.94817851, 1.16173444, 0.8182313],
[0.61039958, 0.62205787, 1.16426669, 0.9251993 , 1.3100753],
[0.66650649, 0.96351789, 0.84902675, 0.97673267, 0.7498163]])
Подача входных данных в нейронную сеть
Наша примерная сеть имеет 3 входных узла. Это означает, что нам нужно предоставить ему входной вектор (или матрицу) размером 1×3. Поскольку наша первая весовая матрица имеет размер 3×4, первое умножение матриц будет выглядеть так:


результатом матричного умножения будет новый вектор из 4 элементов. В матричной нотации мы могли бы сказать, что она имеет размер 1 × 4, что идеально, поскольку матрица следующего слоя имеет размер 4 × 2 и условие размера выполнено.
Однако, прежде чем мы умножим этот новый вектор на следующую матрицу, нам нужно немного преобразовать его. Это преобразование выполняется с помощью функции активации, и это то, что мы рассмотрим далее.
Что такое функция активации?
Концепция функции активации исходит из аналогии с нейронной сетью человека. В реальной жизни нейроны обладают активационным потенциалом. Если входной сигнал, который достигает нейрона, недостаточно силен, то нейрон не сработает, и информация не будет поступать на следующий слой.
В случае искусственных нейронных сетей функции активации могут добавить в сеть нелинейность. Я думаю, что этот пост хорошо объясняет, почему функции активации важны.
В любом случае у каждого нейрона в сети есть функция активации, и он применяет эту функцию к получаемому входу. Поскольку мы используем numpy, мы можем воспользоваться преимуществами векторизации и одновременно применить все функции активации для слоя.
Типы функций активации
Существуют различные функции активации, которые можно использовать. Некоторыми распространенными из них являются сигмоидальные функции, которые имеют удобную характеристику легкости дифференцируемости (взятие их производной несложно с точки зрения вычислений).
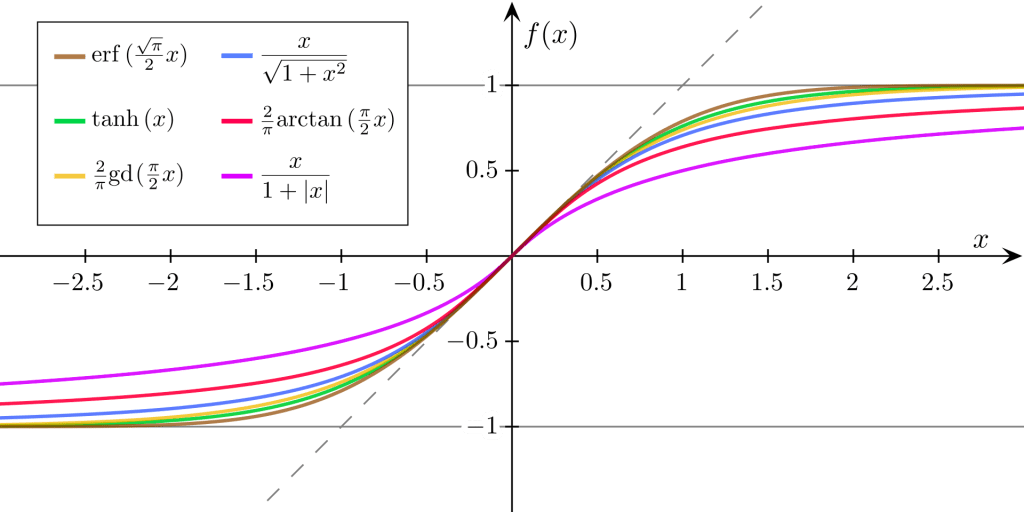
В последнем примере после выполнения первого матричного умножения у нас остается новый вектор I. Именно на этом этапе мы применяем функцию активации к этому вектору поэлементно. Одной из общих функций для этого является функция гиперболического тангенса (tanh). Функция tanh представляет собой тип сигмоидальной функции, и ее производную легко вычислить, поэтому именно ее мы будем использовать в этом примере. Он также отображает любое значение в диапазоне [-1,1].
Некоторые функции активации, о которых вы могли слышать, следующие:
- Выпрямленная линейная единица (ReLU)
- Дырявый ReLU
- Сигмоидальные функции
- Гиперболический тангенс (tanh)
- Софтмакс
Вы должны проанализировать, какие из них наиболее удобны для выбранного вами подхода.
Упреждающее распространение в Python
class NeuralNet(object):
...
def feedforward(self, input_vector):
I = input_vector
for idx, W in enumerate(self.weight_mats):
I = np.dot(I, W)
if idx == len(self.weight_mats) - 1:
out_vector = np.tanh(I) #output layer
else:
I = np.tanh(I) #hidden layers
return out_vector
В этом коде я использую tanh в качестве функции активации для всех слоев. Однако на самом деле мы можем использовать другую функцию активации для скрытых слоев, чем для выходного слоя. Например, если сеть учится предсказывать вероятности, то, возможно, функция sigmoid будет лучше, потому что она выводит значение между [0,1] вместо [-1,1], как tanh.
Соображения и предостережения
Целью этого поста было показать, как упреждающее распространение происходит в фоновом режиме. Некоторые вещи, которые я полностью опустил здесь:
- Правильная инициализация веса сети
- Узлы смещения
- Предварительная обработка ввода перед прямым распространением
- Обучение сети с помощью обратного распространения
Далее я напишу последующий пост, посвященный обратному распространению, и, возможно, я также включу другие темы. Если нет, то я мог бы написать больше сообщений для каждой из этих проблем.
Последние мысли
Мы видели, что процесс прямой связи для нейронной сети в основном представляет собой серию матричных умножений с промежуточными функциями активации. По большей части это линейная алгебра, и numpy позволяет нам создавать эту функциональность самостоятельно.
Я считаю, что легче понять такие концепции после того, как проделаю их вручную, и я думаю, что многие другие люди будут чувствовать то же самое. Наконец, вот репозиторий, куда я буду добавлять код, связанный с нейронными сетями, в том числе и в этом посте.
Если вы хотите узнать о следующих сообщениях в этой серии нейронных сетей, подумайте о том, чтобы присоединиться к списку рассылки новостей.
Также, если у вас есть какие-либо вопросы, или если я допустил ошибку, дайте мне знать в комментариях.
Вы также можете подписаться на мой канал YouTube для видео о проектах Python, автоматизации и криптографии:
Первоначально опубликовано на https://andresberejnoi.com 24 июня 2022 г.