Наука о данных
Веб-скрейпинг: введение, важность и методы
Парсинг в Интернете с помощью библиотек Python
«Тем, у кого нет навыков, программирование может показаться чем-то вроде волшебства. Если программирование — это волшебство, то просмотр веб-страниц — это волшебство; то есть применение магии для особо впечатляющих и полезных» —Райан Митчелл

Index Of Contents · Introduction · Applications of Webscraping · Points to remember before Web scraping · Steps involved in Web Scraping process · Python · Best Python Libraries to Perform Web Scraping ∘ Requests ∘ Beautiful Soup ∘ Selenium ∘ Python Scrapy Framework ∘ Python lxml.html library · Conclusion
Введение
В современном мире мы все оснащены данными вокруг нас. Умение собирать и использовать данные в наших проектах — обязательный навык для каждого специалиста по данным. Если вы когда-либо копировали и вставляли информацию с веб-сайта, вы выполняли ту же функцию, что и любой парсер, только в микроскопическом масштабе вручную. В отличие от скучного, утомительного процесса ручного извлечения данных, веб-скрапинг использует интеллектуальную автоматизацию для извлечения сотен, миллионов или даже миллиардов точек данных из Интернета.
Веб-скрапинг — это процесс сбора данных с веб-сайтов с помощью автоматизированных скриптов. Это решение для тех, кто хочет получить доступ к структурированным веб-данным. Как правило, извлечение веб-данных используется людьми и предприятиями, которые хотят использовать огромное количество общедоступных веб-данных для принятия более взвешенных решений. Существуют различные виды инструментов веб-скрейпинга с возможностями, которые можно настроить в соответствии с различными проектами извлечения.
Это наиболее полезно, если общедоступный веб-сайт, с которого вы хотите получить данные, не имеет API или предоставляет только ограниченный доступ к данным. Веб-скребки могут извлекать все данные, которые хочет пользователь, с определенного сайта или определенные данные с сайтов. Например, вы хотите очистить страницу Amazon для поиска различных типов книг, но вам нужны только данные о различных категориях книг, а не рейтинги клиентов. Он состоит из трех основных шагов: получение страницы, анализ HTML и извлечение необходимой информации.
Приложения парсинга веб-страниц
Исследование рынка имеет решающее значение и должно основываться на самых точных доступных данных. Высококачественные, большие объемы и очень информативные данные веб-скрапинга любой формы и размера подпитывают анализ рынка и бизнес-аналитику во всем. Некоторые из основных вариантов использования веб-скрапинга включают в себя:
- Веб-скрапинг полезен для компаний, занимающихся недвижимостью, для получения данных о новых проектах, покупки или продажи недвижимости и т. д.
- Порталы мониторинга цен и сравнения цен, такие как Trip Advisor, активно используют веб-скрапинг для получения информации о продуктах и ценах с различных сайтов электронной коммерции.
- Мониторинг новостей и лидогенерация.
- Анализ тенденций рынка и ценообразование.
- Исследования и разработки.
- Мониторинг конкурентов.
О чем следует помнить перед веб-скрапингом:
- Парсинг в масштабе: парсинг одной страницы прост, но есть проблемы с парсингом миллионов веб-сайтов, управлением кодом, сбором данных и поддержанием хранилища данных.
- Рекомендации по сбору данных: Сбор данных с веб-сайтов без разрешения владельца может быть расценен как злонамеренный. Необходимо соблюдать определенные правила, чтобы гарантировать, что скребкам не будет отказано в доступе.
Шаги, связанные с процессом парсинга веб-страниц:
- Определите свой целевой веб-сайт.
2. Определите URL-адреса страниц, с которых вы хотите извлечь данные.
3. . Проверьте, чтобы понять элементы структуры HTML и установите соответствующие библиотеки.
4. Отправьте HTTP-запрос к URL-адресам по вашему выбору, чтобы получить доступ к элементам HTML (тегам и атрибутам).
5. Используйте локаторы, чтобы найти определенные данные в HTML
6. Напишите код, создайте вспомогательные функции и вызовите все эти функции в конечном коде.
7. Запустите последнюю функцию, чтобы создать фрейм данных без ошибок.
8. Сохраните данные в файле JSON или CSV или в любом другом структурированном формате (.xlsx, .xml).
Питон
Python является наиболее широко используемым и признанным языком программирования, который имеет множество библиотек, созданных специально для веб-скрейпинга. Сообщество Python предоставило несколько мощных инструментов для очистки веб-страниц. Всегда соблюдайте правила веб-сайтов, которые вы планируете парсить. Если доступны API, всегда используйте их в первую очередь.
Лучшие библиотеки Python для выполнения парсинга веб-страниц

Запросы
Получение HTML-контента веб-страницы — это первый и главный шаг веб-скрейпинга. «Запросы» позволяют нам делать HTML-запросы на сервер веб-сайта для получения данных на его странице. Это библиотека Python, используемая для выполнения различных типов HTTP-запросов, таких как GET, POST и т. д. Это самая простая, но необходимая библиотека для парсинга веб-страниц.
`requests.get()`используетсядля полученияURL-адреса веб-страницы, а результат сохраняется в переменной. Итак, давайте рассмотрим переменную как `response`. response.status_code должен находиться в диапазоне от 200 до 299.
Прекрасный суп
BeautifulSoup более удобен для пользователя и позволяет вам быстрее учиться и легче приступать к веб-скрейпингу небольших задач. Хотя у него есть некоторые ограничения по очистке только статических веб-сайтов, и обычно он плохо работает с динамическими сайтами. Это библиотека Python, подходящая для просмотра веб-страниц, которая обычно используется для анализа данных из документов XML и HTML.
- Установите и импортируйте библиотеку BeautifulSoup.
- Нам нужно создать объект Beautiful Soup для поиска и анализа данных из HTML.

- doc.title получает название страницы. Объект документа содержит все данные во вложенном формате. Попробуйте найти шаблон для навигации по всем элементам со страницы. После этого мы можем найти эти элементы с помощью методов find() и find_all().
- Первым параметром является тег -div’, ‘a’, ‘li’, ‘tr’, ‘meta’, ‘ul, заключенный между ‹›. Второй параметр — это атрибуты — (пары имя-значение) — class, id, span, style. find() возвращает одно значение с соответствующим тегом и атрибутом в качестве вывода. find_all() возвращает список всех значений с соответствующим тегом и атрибутом в качестве вывода.
- Организуя этот проанализированный контент в более доступные деревья, BeautifulSoup значительно упрощает навигацию и поиск в больших наборах данных. Он создает дерево синтаксического анализа, которое можно использовать для извлечения данных из HTML на веб-сайте. Красивый суп также имеет несколько функций для навигации, поиска и изменения этих деревьев синтаксического анализа.
Селен
Selenium — это библиотека Python, которая используется для автоматизации браузера и кросс-браузерного тестирования. У всех библиотек Python, которые мы обсуждали в этом блоге, есть ограничение — мы не можем легко собирать данные с динамически заполняемых веб-сайтов. Это происходит потому, что иногда данные, присутствующие на странице, загружаются через JavaScript, т.е. динамический веб-сайт. Это веб-драйвер, созданный для рендеринга веб-страниц, но эта функциональность делает его особенным. Там, где другие библиотеки не могут запускать JavaScript, Selenium преуспевает. Он может совершать клики по странице, заполнять формы, прокручивать страницу и делать многое другое.
Эта возможность запускать JavaScript на веб-странице дает Selenium возможность очищать динамически заполняемые веб-страницы. Но здесь есть компромисс. Единственный недостаток Selenium заключается в том, что он загружает и запускает JavaScript для каждой страницы, что делает его медленнее и не подходит для крупномасштабных проектов. Если время и скорость вас не волнуют, то вы определенно можете использовать Selenium.
- Установите и импортируйте библиотеку Selenium и Webdriver.
- Чтобы найти и проанализировать данные с помощью Selenium, нам нужно импортировать «By».
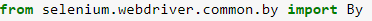
- driver.title получает название страницы. Попробуйте найти шаблон для навигации по всем элементам со страницы. После этого мы можем найти эти веб-элементы, используя методы find_element() и find_elements().
- Один параметр либо тег, либо класс. (По.TAG_NAME, 'значение'), (По.CLASS_NAME,'значение'), (По.ID,'значение'). find_element() возвращает одно значение с соответствующим тегом или атрибутом в качестве выходных данных, а find_elements() возвращает список всех значений с соответствующим тегом или атрибутом в качестве выходных данных. Могут быть случаи, когда элементы не могут быть найдены с помощью общих локаторов, таких как идентификатор, имя, класс и т. д. И это когда используется XPath.
- Нам нужно разобраться с chromedriver, что может доставить немало хлопот . Но есть встроенная библиотека Kora.selenium, которая позволяет нам работать в Google Colab без драйвера Chrome, о котором мы поговорим в следующей части. Установите chrome driver и path здесь
Среда Python Scrapy

Scrapy — это очень популярная платформа для веб-сканирования с открытым исходным кодом, написанная на Python и извлекающая структурированные данные из Интернета. Она идеально подходит для веб-скрейпинга, а также для извлечения данных с использованием API. Он также используется для интеллектуального анализа данных, обработки информации и архивирования исторического контента. Scrapy быстрее, чем BeautifulSoup. Более того, это фреймворк для написания парсеров, в отличие от BeautifulSoup, который представляет собой просто библиотеку для разбора HTML-страниц.
Scrapy предоставляет роботов-пауков, которые могут сканировать несколько веб-сайтов и извлекать данные. С помощью Scrapy вы можете создавать своих роботов-пауков, размещать их в Scrapy Hub или в качестве API. Он позволяет создавать полнофункциональных пауков за несколько минут. Вы также можете создавать конвейеры с помощью Scrapy. Лучшее в Scrapy то, что он асинхронный. Он может делать несколько HTTP-запросов одновременно. Это экономит нам много времени и повышает нашу эффективность.
Вы также можете добавить плагины в Scrapy для расширения его функциональности. Хотя Scrapy не может обрабатывать JavaScript, как селен, вы можете связать его с библиотекой Splash, легким веб-браузером. С помощью Splash Scrapy может извлекать данные даже с динамических веб-сайтов.
Библиотека Python lxml.html

Мы знаем, что библиотека requests не может анализировать HTML-код, извлеченный из веб-страницы. Поэтому нам требуется lxml, высокопроизводительная, быстро развивающаяся, высококачественная библиотека HTML и XML для синтаксического анализа Python. Он уникален тем, что сочетает в себе скорость и возможности XML этих библиотек с простотой собственного API Python.
Библиотека LXML отлично подходит для извлечения больших объемов данных из любых интернет-баз данных. Для извлечения и анализа данных с помощью селекторов XPath и CSS чаще всего используется комбинация запросов и lxml.
Заключение:
Надеюсь, вы ознакомились с наиболее популярными библиотеками веб-скрейпинга, о которых говорилось выше. Я бы посоветовал, если вы новичок и хотите быстро освоиться и выполнять операции веб-скрейпинга, Beautiful Soup — лучший выбор.
Когда вы имеете дело с веб-сайтом с поддержкой Core Javascript, лучшим выбором будет Selenium, но размер данных должен быть ограничен. Если вы имеете дело со сложной операцией очистки, требующей огромной скорости и низкого энергопотребления, Scrapy будет отличным выбором.
Совершенно очевидно, что веб-скрапинг — это то, что будет продолжать расти в следующем году с новыми вариантами использования. Веб-скрейпинг иногда может быть интересным и сложным. Проверьте веб-сайт перед парсингом, однако необходимо соблюдать некоторые правила веб-скрейпинга. Веб-скрапинг является незаконным, когда извлекаются данные, которые не являются общедоступными.
Собирайте ответственно :) В следующем блоге я опубликую детали кода Selenium-веб-скрейпинга. Я бы порекомендовал главу Web Scraping из Automate the Boring Stuff: https://automatetheboringstuff.com/2e/chapter12/. Он более подробный, а также показывает использование модуля selenium, который вам придется использовать, если вы хотите динамически взаимодействовать с веб-сайтом.
Спасибо, что прочитали мой пост — надеюсь, он был полезен. Вы можете найти меня в LinkedIn. Счастливого обучения :)