Предшественник всего машинного обучения: веб-скрапинг: техника, инструменты и реализация (учебник 1)
Это первая часть двух руководств по парсингу веб-страниц. По ссылке вторая часть:
Веб-скрапинг. Это искусство идентификации и извлечения данных из Интернета.
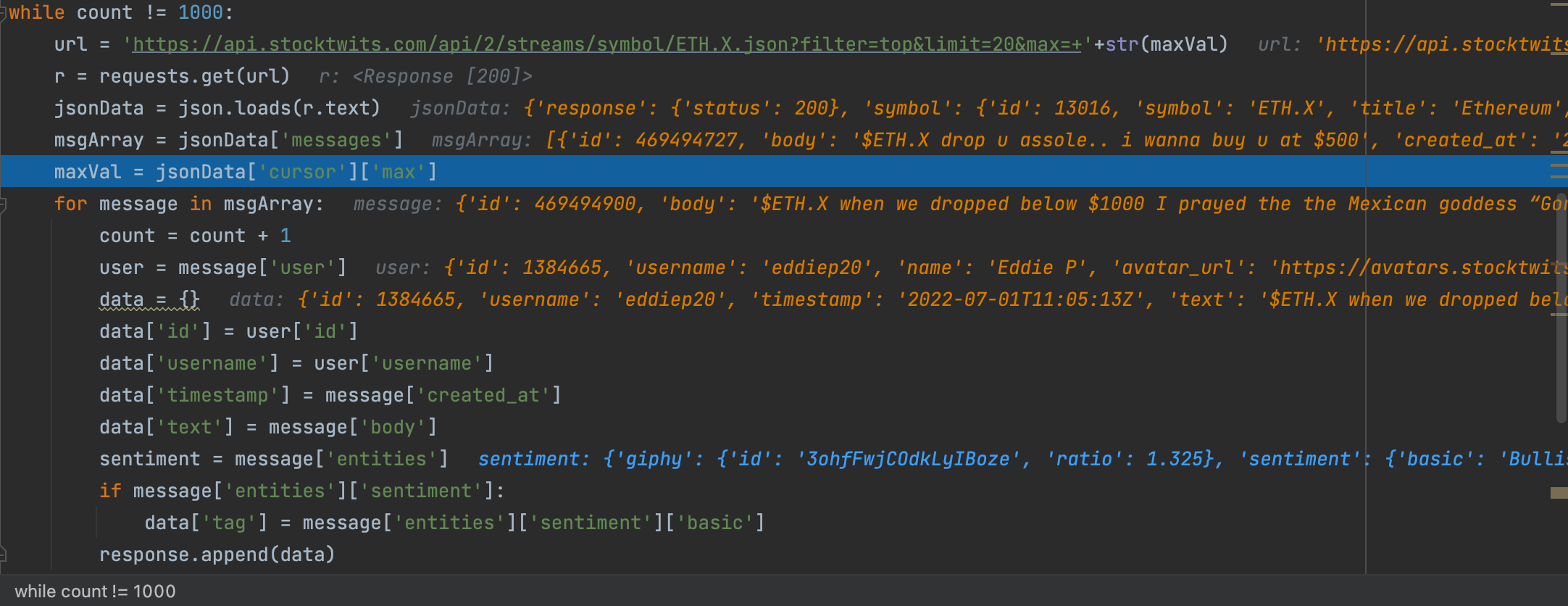
Постановка задачи. Извлеките текст из последних 1000 твитов с хэштегом $ETH.X (Ethereum), размещенных на Stocktwits:
Решение:
Шаг 1. Определите веб-сайт, который будет использоваться:
https://stocktwits.com/symbol/ETH.X
Шаг 2. Являются ли данные частью содержимого HTML или отображаются с помощью вызова javascript для получения JSON? В этом случае выполняется вызов GET API.
Шаг 3. Определите вызов GET на вкладке сети и проверьте его соответствие содержимому на экране. Здесь вызов GET
https://api.stocktwits.com/api/2/streams/symbol/ETH.X.json?filter=top&limit=20
Но если мы будем неоднократно вызывать этот API, мы будем продолжать получать один и тот же JSON.
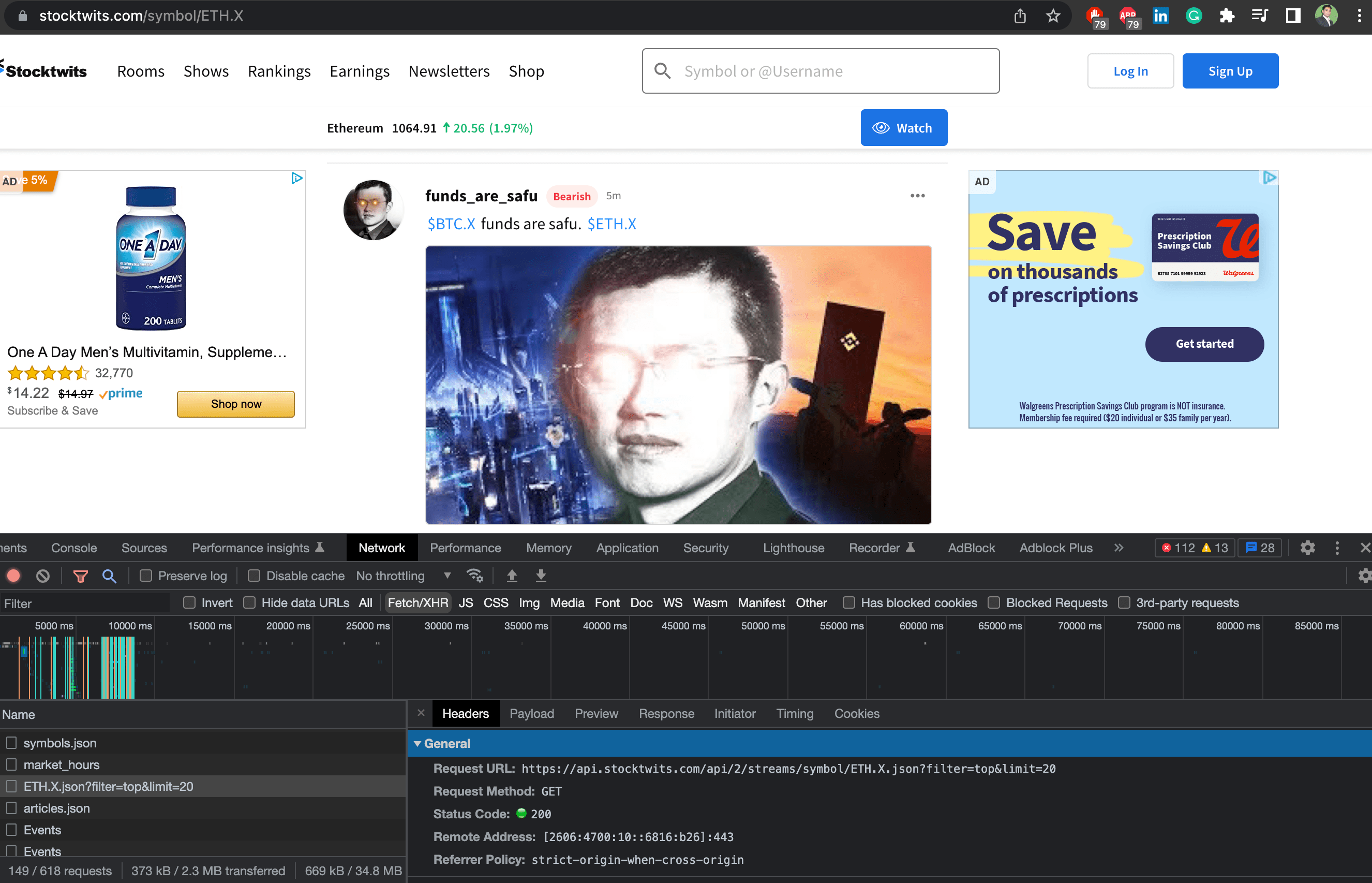
Шаг 4. Углубитесь в ответ.В JSON присутствует поле max, которое мы можем отправить в качестве параметра, чтобы получить выходные данные ниже этого значения. Это поле (макс.) обновляется при каждом вызове API, которое мы можем использовать при следующем вызове.
https://api.stocktwits.com/api/2/streams/symbol/ETH.X.json?filter=top&limit=20&max=469771667

Шаг 5. Вызовите окончательный API, как показано ниже, из кода. Полученный JSON можно проанализировать для получения соответствующей информации и дальнейшего сохранения.