
Этот блог продолжает изучение методов глубокого обучения для табличных данных. Ранее мы рассмотрели TabNet, одну из первых моделей глубокого обучения, разработанную специально для табличных данных. В этом блоге основное внимание будет уделено VIME (вменение значений и оценка по маске) — платформе самообучения и полуконтролируемого обучения для табличных данных.
Цель этого блога — дать вам возможность глубже погрузиться в архитектуру и показать, когда и как ее можно применять для обнаружения мошенничества. Вы можете найти все блокноты и код в этом репозитории github. Он содержит полный рабочий пример, поэтому мы настоятельно рекомендуем его проверить. Данные по обнаружению мошенничества берутся с Kaggle, а оригинальный репозиторий VIME можно найти здесь.
Почему самообучение/полуконтролируемое обучение?
Представьте ситуацию, когда помечен только 1% всего набора данных. Это может произойти в областях, где маркировка данных является непомерно дорогой и/или требует очень много времени. Например, при обнаружении мошенничества проверяется только небольшая выборка транзакций.
Может показаться заманчивым обучить полностью контролируемую модель на этом 1% меток, но это может дать вам ложное чувство безопасности. Классические модели для табличных наборов данных (такие как DNN или XGBoost) очень хорошо справляются с изучением строгих границ вокруг помеченных примеров, но это может промахнуться с немаркированными точками данных. Вместо этого этот вид задач может лучше подходить для полуконтролируемого обучения, поскольку он может использовать как размеченные, так и неразмеченные данные.
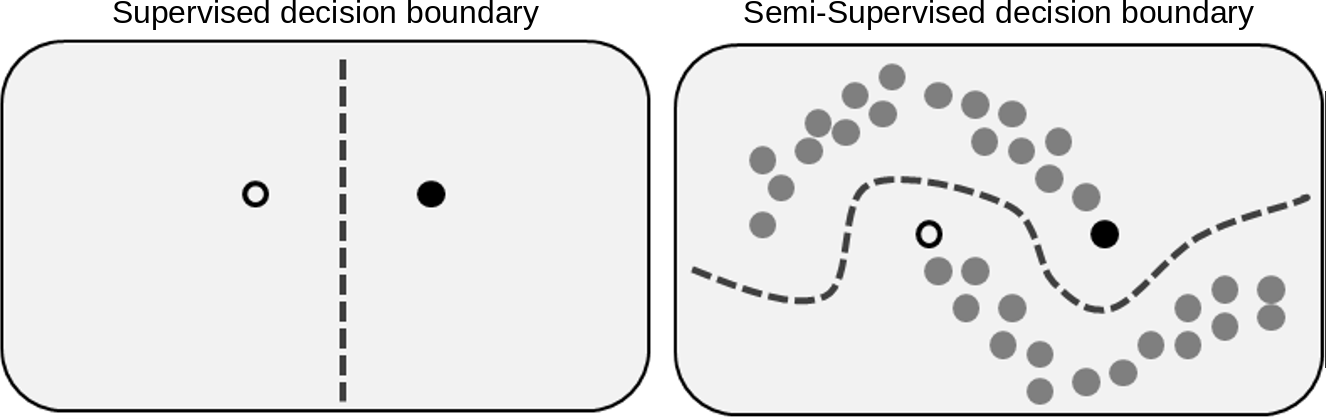
Главная идея
Представлено Yoon et al. (2020), VIME — это систематический подход к обучению с самостоятельным и полууправляемым обучением для табличных данных. Основная идея заключается в том, что окончательная модель обучается в 2 этапа:
- Кодер данных обучается на немаркированном наборе данных с помощью задачи реконструкции (обучение с самоконтролем).
- Затем обученный кодировщик используется для обучения предиктора, который точно настраивается как для помеченных, так и для немаркированных наборов данных (полуконтролируемое обучение).

Самостоятельное обучение
Теория
Идея самоконтролируемого обучения очень проста: мы хотим использовать немаркированные данные для изучения полезных представлений функций. Обычно это делается путем обучения модели кодировщика выполнению какой-либо искусственной, но сложной задачи. Например, в доменах изображений мы можем захотеть реконструировать выборки, дополненные вращением, добавлением шума и т. д. Та же логика применима к VIME, где входные выборки повреждены и впоследствии восстановлены. Процесс увеличения матрицы признаков X выполняется с использованием следующих шагов:
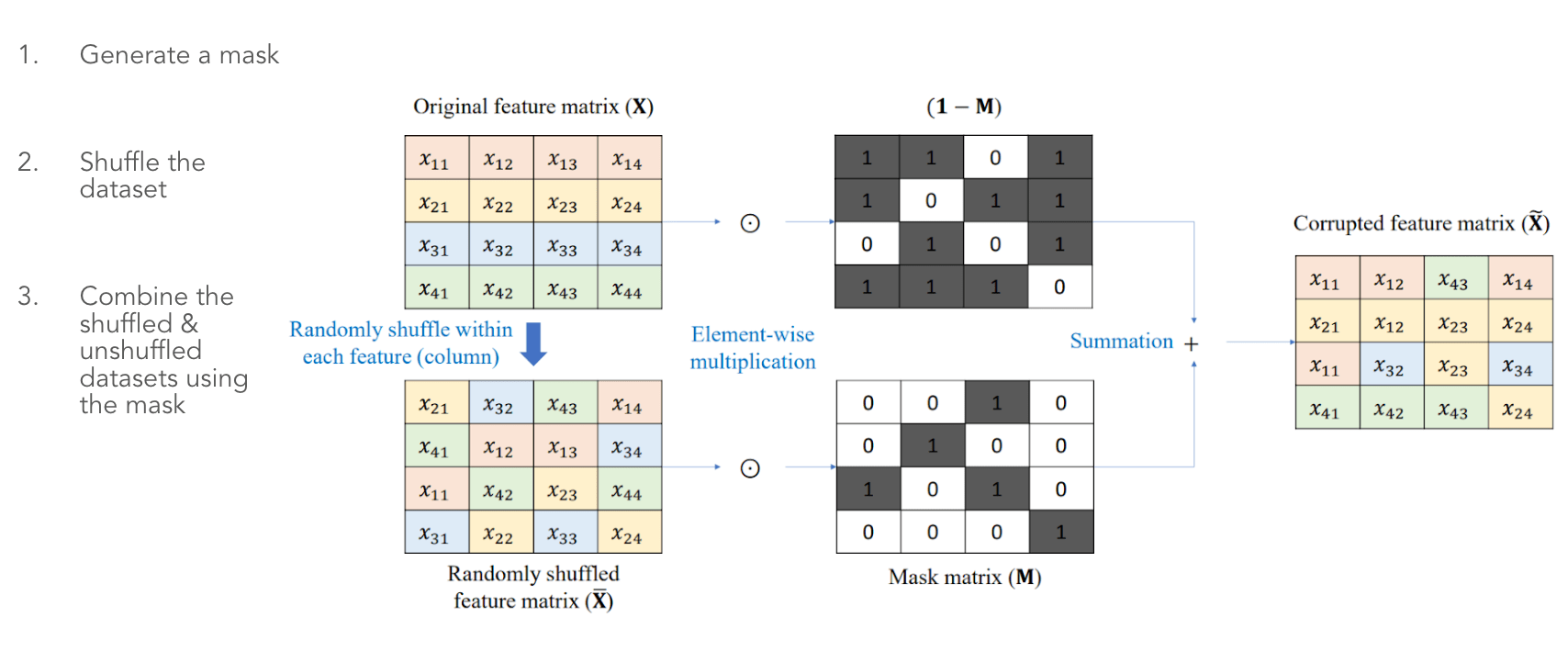
По сути, мы просто меняем некоторые значения признаков из одного наблюдения на соответствующие значения из другого наблюдения. Этот тип аугментации известен как CutMix. По словам авторов, восстановление поврежденных табличных выборок может быть довольно сложной задачей для модели, поэтому задача фактически разбита на 2 отдельные подзадачи:
- Реконструкция маски искажения
- Реконструкция исходных функций.
Каждая из этих подзадач имеет свою собственную модель, которая использует общие вложения кодировщика в качестве входных данных. Интуитивно, используя эти две задачи, кодировщик подталкивается к изучению корреляций между функциями и выводу вложений, которые могут восстановить исходные данные.

Оптимизированные потери рассчитываются по следующей формуле:

где Mask Reconstruction Loss — двоичная кросс-энтропия, Feature Reconstruction Loss — среднеквадратическая ошибка, а alpha — гиперпараметр для настройки.
Обратите внимание, что из всей этой модели единственная часть, о которой мы действительно заботимся, — это кодировщик. После обучения он должен знать полезные представления функций, которые будут использоваться в полуконтролируемой обстановке.
Код
Обратите внимание, что архитектуры кодировщика и декодера можно настроить в зависимости от сложности вашего набора данных. Вы можете использовать больше слоев, разные активации или даже архитектуру TabNet.
Модель возвращает 2 массива — реконструированную маску и реконструированные признаки. После подготовки данных самоконтролируемая модель может быть обучена как любая другая модель TensorFlow. Гиперпараметр alpha определяет, какой вес придается потерям при реконструкции объектов.
Оценка
Реконструкция маски — это, по сути, задача бинарной классификации, поэтому ее можно оценить с помощью ROC AUC. Для реконструкции признаков мы можем использовать RMSE или коэффициент корреляции. Разные столбцы имеют разную простоту реконструкции, поэтому стоит посмотреть на распределение этих метрик по функциям.

В целом, модель, которую мы обучили, работает относительно хорошо. Реконструированные признаки имеют положительную корреляцию, и замаскированные значения имеют тенденцию получать более высокие оценки маски.
Еще один способ оценить самоконтролируемую модель — посмотреть на вложения. Когда мы искажаем набор данных, мы учим модель учиться генерировать надежные вложения. Если образец был поврежден 5 раз, все 5 вложений должны быть относительно близко друг к другу в векторном пространстве. Давайте проверим эту гипотезу, искажая 10 разных образцов 5 раз и проецируя их вложения в 2-мерное пространство с помощью UMAP.

Из графика выше видно, что действительно вложения для одних и тех же образцов близки друг к другу. Также обратите внимание, что когда модель не обучалась на поврежденных выборках, вложения плохо сгруппированы в векторном пространстве. Основываясь на этих графиках, мы можем быть уверены, что кодировщик изучил полезную информацию и может быть использован в части полуконтролируемого обучения.
Полуконтролируемое обучение
Теория
Часть полуконтролируемого обучения использует как помеченные, так и немаркированные наборы данных. С помеченной частью все как обычно — контролируемое обучение по меткам с использованием либо кросс-энтропии, либо потерь MSE. Обучение без маркировки немного сложнее и состоит из следующих шагов:
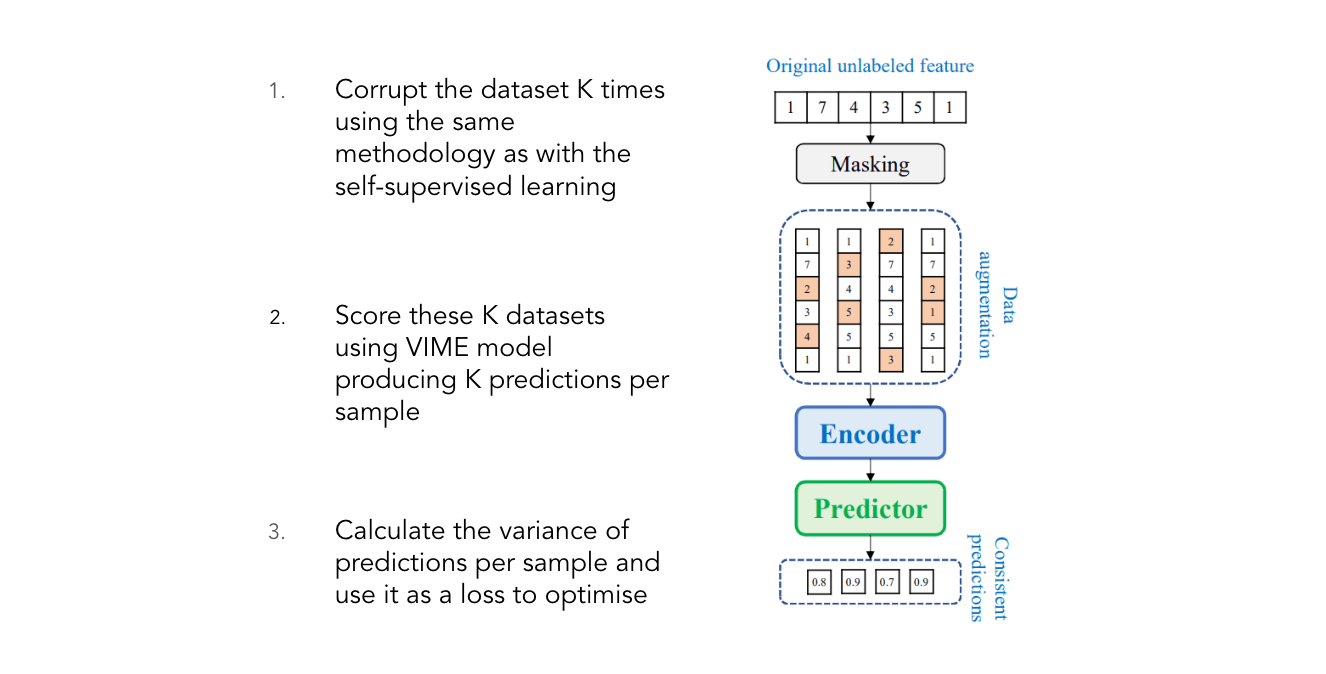
Основная идея снова состоит в том, чтобы сбалансировать две цели — точно предсказать размеченные данные и вывести согласованные прогнозы для поврежденных неразмеченных образцов. Неконтролируемая задача действует как регуляризатор, не позволяющий модели забыть все, чему она научилась в самоконтролируемой части.
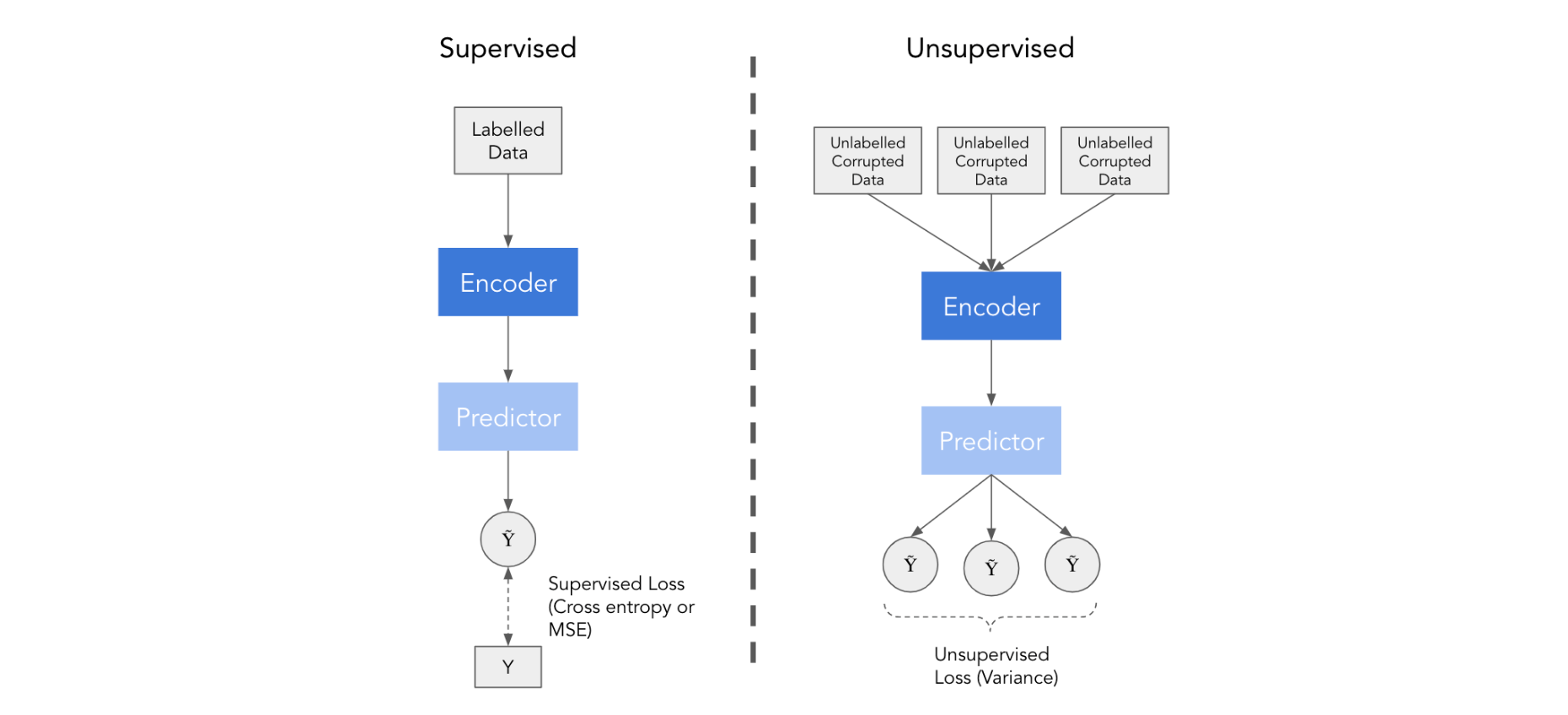
Общий убыток при частичном контроле рассчитывается по следующей формуле:

где Контролируемая потеря — это категориальная кросс-энтропия для задач классификации и среднеквадратическая ошибка для задач регрессии, Неконтролируемая потеря — это дисперсия прогнозов по выборке, а бета — это гиперпараметр.
Код
Как видите, архитектура, выполняющая обе задачи, одинакова. Следовательно, нам просто нужно добавить модель предиктора поверх предварительно обученного кодировщика, чтобы получить окончательную модель.
Самая сложная часть работы с VIME с полуучителем — это обучение. У нас есть 2 задачи, которые имеют совершенно разные наборы данных и потери (маркированные и немаркированные). Чтобы решить эту проблему, мы решили создать собственный цикл обучения, используя генераторы в качестве входных данных.
Оценка
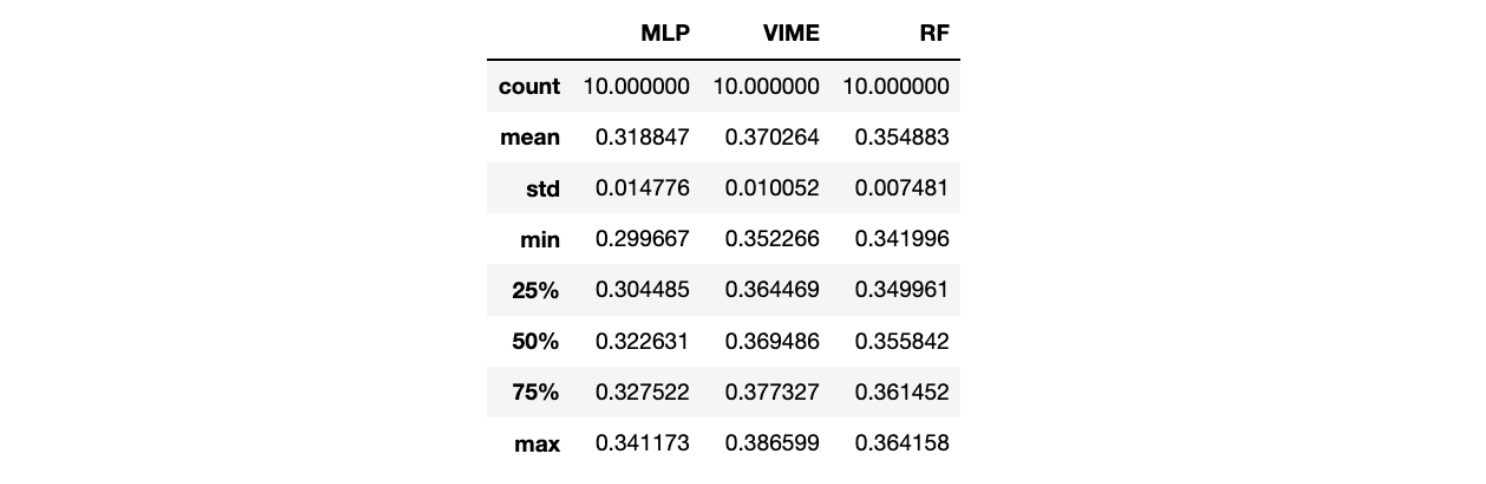
Давайте посмотрим, как он работает на тестовом наборе, который имеет все ярлыки мошенничества в течение следующих 2 месяцев. Помните, что модель была обучена только на 1% меток, поэтому мы ожидаем, что VIME превзойдет полностью контролируемые модели в этом параметре. Для сравнения используются две модели: многоуровневый персептрон (MLP) и случайный лес (RF). Мы сравниваем с MLP, потому что хотим увидеть, насколько велика польза от предварительного обучения с использованием VIME. Мы выбрали для сравнения RF, потому что это отраслевой стандарт обнаружения мошенничества. Все модели были обучены 10 раз для оценки средней производительности. Распределение PR AUC можно увидеть ниже.

Мы видим, что VIME значительно превосходит полностью контролируемые модели. MLP в среднем имеет PR AUC на 0,05 ниже, чем VIME, что означает, что задачи перед обучением действительно повышают ценность нейронной сети. Кроме того, VIME превосходит RF в среднем на 0,015, что может быть значительным при больших объемах и стоимости транзакций.
Заключение
В ситуациях, когда помечена лишь небольшая часть набора данных, полууправляемое обучение может привести к лучшим результатам по сравнению с полностью контролируемыми моделями.
В этом блоге показано, как полууправляемое обучение может выполняться на табличных данных с помощью VIME. Кроме того, мы глубоко погрузились в архитектуру и процедуру обучения, чтобы вы лучше понимали, что происходит под капотом. Наконец, вы увидели, как обучать VIME с использованием набора данных для обнаружения мошенничества в Tensorflow и как его оценивать. Еще раз, мы рекомендуем вам ознакомиться с полной записной книжкой в этом репозитории github и сообщить нам, если у вас есть какие-либо комментарии, предложения или пожелания для дальнейшего углубленного изучения.