История REstringer — нового деобфускатора Javascript с открытым исходным кодом.
TL;DR
Теперь это история о том, как
Мой код переворачивается-переворачивается с ног на голову
И я хотел бы уделить минутку
Просто сядьте вот здесь
Я вам расскажу как я пришел к созданию своего деобфускатора — REstringer.
Короче говоря, я выпускаю инструмент деобфускации Javascript под названием REstringer, как как код, так и как онлайн-инструмент. инструмент, некоторые дизайнерские решения и процесс, посредством которого я добавляю к нему новые возможности — так что вы можете присоединиться к веселью! Пришло время добавить ВЕСЕЛЬЯ в Javascript o̶b̶f̶u̶s̶... d̶e̶o̶b̶F̶U̶N̶s̶c̶a̶… — Хорошо, это может потребовать некоторой доработки 😅.
РЕШИТЬ, ЗАМЕНИТЬ, ПОВТОРИТЬ
Имя Картер. Магкартер.
Пару лет назад я начал работать в исследовательской группе Code Defender в PerimeterX. Часть моего рабочего процесса включает в себя расследование атак Magecart, которые теперь почти синонимичны атакам скимминга. Эти атаки обычно принимают форму файлов Javascript, внедряемых либо непосредственно на скомпрометированные сайты, либо через скомпрометированный сторонний скрипт. Я собираю эти файлы и анализирую их. Я расскажу больше о моем процессе расследования в следующем посте.
Существует множество подходов к анализу кода, хотя в основном мы можем разделить их на следующие категории:
- Статический — просмотр кода без его запуска. Поиск шаблонов и отслеживание потока выполнения кода.
- Динамический — запуск кода в любой исследовательской среде, которая вам подходит, остановка в середине выполнения и наблюдение за значениями и порядком стека в контексте.
Если сценарий не очень прост для понимания или вы уже имели дело с подобным кодом, вам следует использовать комбинацию двух подходов, чтобы получить полное представление о том, что и как делает сценарий.
Например, при анализе такого скрипта, как скиммер anti-vm, упомянутого в моих предыдущих сообщениях в блоге (Дальняя точка статической встречи и Автоматизация деобфускации скиммера), я бы использовал сочетание статического анализа структуры кода и запуска только частей кода (в Chrome devtools, на странице about:blank):
- Определите функцию распаковки/декодирования, наблюдая за структурой кода. Как это определяется, упоминалось в предыдущих блогах.
Функция UDS соответствует описанию:
function UDS(b) {
// …
return f.join('');
}
2. Определите экземпляр, в котором UDS вызывается со строковым аргументом.
Я заменил переменную MXQ на ее значение 759 — 748, равное 11.
3. Динамически распаковывать/декодировать соответствующие строки, запуская как можно меньше кода.
Я копирую функцию UDS и потом добавляю к ней вызов, чтобы получить значение:
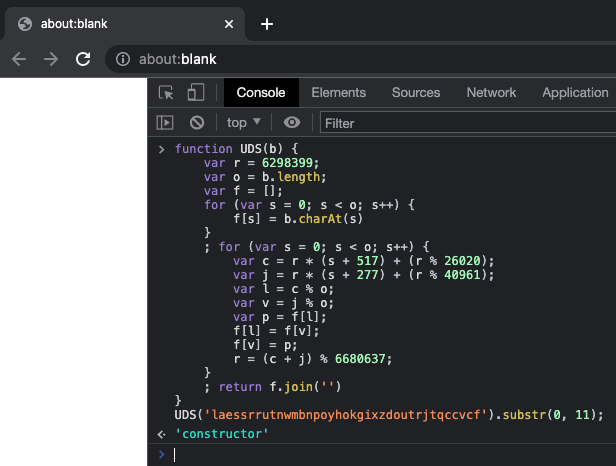
Теперь я беру это значение и заменяю им вызов функции.
Это не так уж плохо, не так ли? Делать это один или два раза — это хорошо и модно, но это может занять довольно много времени и утомительно, когда сталкиваешься со все большим количеством случаев одного и того же обфускации.
По словам Рэймонда Хеттингера — «Должен быть лучший способ»!
Конечно, он есть! Если вы можете сделать это вручную, вы почти наверняка сможете написать скрипт для этого.
Лучший способ (дубль 1) — массив ссылок
Давайте начнем с чего-то простого и будем двигаться дальше.
Одним из основных типов запутывания, активно используемых злоумышленниками Magecart, является метод Замены массива. Он характеризуется наличием массива, инициализированного строками, и ссылками по всему коду на индексы внутри массива.
Как это выглядит?
Я последую примеру Гая Бэри в его сообщении в блоге Анализ вредоносного ПО Magecart — от нуля до героя:
- Загрузите массив в память.
- Найдите ссылки на массив, используя регулярное выражение.
- Получите их значение, запустив их с помощью eval.
- Замените ссылки фактическим значением.
Хотя это действительно работает, требуется ручное вмешательство — предоставление имени массива. Конечно, мы могли бы и должны также кэшировать результаты или использовать replaceAll для повышения производительности, но это ухудшило бы простоту примера.
Обратите внимание, что сначала я запускаю только первую строку кода, используя code.split(‘\n’)[0], чтобы избежать любых побочных эффектов, которые могут возникнуть из-за запуска всего кода, а именно сообщения «hello world», распечатываемого во время выполнения. Хотя здесь мне удалось избежать этого, исходный скрипт мог разместить массив практически где угодно или полностью лишиться новых строк (как это часто бывает с внедренным кодом). Побочный эффект также может быть намного хуже, чем просто доброкачественное сообщение.
Увеличение сложности
Давайте немного смешаем это. Рассмотрим эволюцию этого метода запутывания, метод замен расширенного массива. Он имеет те же характеристики, что и его нерасширенный аналог, но с дополнительным Выражением немедленно вызываемой функции (или IIFE) со ссылкой на массив в качестве одного из своих аргументов, которое изменяет (дополняет) значения в массиве в некоторых способ.
Как это выглядит?
После объявления arr IIFE меняет свой порядок, так что теперь каждый индекс указывает на правильное значение. Если мы попытаемся запустить на нем скрипт деобфускации как есть, мы получим этот неработающий код:
console['world'](''+'hello'+'log');
Простое решение — запустить сценарий как есть, чтобы получить правильный контекст, а затем выполнить поиск и замену. Для этого мы удаляем разделение строки с eval(code.split(‘\n’)[0]) и оставляем eval(code).
Ловушки на весенних каникулах (Казнь)
Однако в блоге Гая рассматривается другой тип запутывания — замены расширенных функций массива (не дополненная версия пропущена). Этот тип запутывания также содержит массив со строками и IIFE, дополняющий его, но вместо того, чтобы на него напрямую ссылались по всему коду, используется вызов функции со строковыми/числовыми параметрами. Эта функция извлекает значение из массива, соответствующего предоставленным параметрам.
Как это выглядит?
Этот игрушечный пример показывает дополнительную ценность функции и то, почему она предпочтительнее более простых замен массивов: вы можете делать все, что хотите внутри функции, а именно, отделять значение параметра от фактического индекса массива, чтобы избежать простая тактика поиска и замены, а также расстановка ловушек, чтобы заманить в ловушку следователей и привлечь внимание любопытных 👉👀. Ловушка, которую я включил, приостанавливает выполнение (но не прерывает его), если инструменты разработки открыты или если он работает внутри IDE с возможностями отладки. Из-за того, что скрипт очень короткий, всего 4 вызова функции dec, он на самом деле не более чем раздражает, но представьте себе скрипт с сотнями вызовов — он довольно быстро устаревает. Конечно, вы можете противодействовать этой простой ловушке несколькими способами, такими как отключение точек останова, удаление этой строки вручную и т. д.
Вот несколько примеров условий, при которых ловушки могут сработать и сломать выполнение:
- Инструментарий открыт.
- Сценарий украшен.
- Есть индикаторы среды NodeJS.
- Есть индикаторы окружения ВМ.
Еще одна полезная уловка, позволяющая сбить с пути расследование этого запутанного сценария, заключается в предоставлении функции dec одноразового аргумента, который вообще не используется (например, аргумент a в примере). Все вызовы содержат разные и случайный первый параметр, что помогает усложнить шаблоны поиска и замены. Вдобавок ко всему, вы можете даже перегрузить вызовы функций дополнительными ненужными параметрами, чтобы полностью изменить сигнатуру вызова.
Те из вас, кто любит играть с кодом во время чтения, могли заметить, что этот пример все еще может быть деобфусцирован с помощью нашего простого метода поиска и замены, например:
Поэтому, чтобы усложнить ситуацию (а почему бы и нет?), я переместил функцию dec в конец кода и перезаписал массив и функцию dec после выполнения:
Я могу написать более сложный скрипт поиска и замены, который извлекает только массив и функцию, а затем деобфускирует строки, но он не масштабируется. Ну что теперь?
Лучший способ (Возможность 2) — обобщение решения: отход от сценария
Позвольте мне прыгнуть прямо в глубокий конец пула, проведя вас через создание деобфускатора для этого типа запутывания. Это будет базовое решение, и я собираюсь упомянуть о недостатках конкретной реализации в конце этой части, поэтому запишите все, что, по вашему мнению, вы бы сделали по-другому, и дайте мне знать, если я что-то пропустил. .
Небольшое напоминание — я собираюсь использовать пакет flAST, чтобы сгладить AST, чтобы упростить поиск структур кода, которые ссылаются друг на друга, и заменить их строками деобфускации.
Начнем с массива. В этом коротком скрипте мы деобфускируем, есть только один массив, так что это просто, но давайте представим, что их может быть больше одного. Как нам найти конкретный массив, который мы ищем? Сначала мы опишем его, а затем напишем в коде.
Мы ищем:
- Декларатор переменной, инициализированный выражением массива.
- Выражение массива не пусто и содержит только строки (литералы).
- На массив ссылается функция (т. е. не глобальная область).
Используя flAST, мы можем посмотреть на ссылки идентификатора и их область действия:
Это слишком общее. Мы можем проверить, насколько хорошо это описывает искомую структуру, добавив наш запутанный код к незапутанной версии большого скрипта (например, это скрипт jQuery) и подсчитав, сколько массивов соответствует описанию.
В данном случае совпали три массива:
re = ['Top','Right','Bottom','Left']; // 1
Ue = ['Webkit','Moz','ms']; // 2
arr = ['d29ybGQ=', 'IA==', 'aGVsbG8=', 'bG9n']; // 3Таким образом, мы являемся общими, но не слишком общими. Мы можем использовать взаимосвязь между массивом и функцией dec, чтобы выбрать правильный. Что мы ищем:
- Объявление функции только с одной ссылкой на соответствующий массив.
- Имеет как минимум столько ссылок на него, сколько элементов в массиве.
В коде это описание выглядит так:
Итак, для каждого из найденных нами массивов мы можем искать функцию декодирования, соответствующую описанию, пока не найдем совпадение.
Теперь все, что осталось, — это найти увеличивающую функцию, ища выражение вызова, где вызываемый объект является выражением функции (т. е. функцией, объявленной на месте, а не идентификатором или объектом) и нашим массивом в качестве одного из ее аргументов. Нам даже не нужно искать это описание во всем коде, достаточно ссылок на наш массив:
Собрав все вместе, мне кажется более разумным разместить каждое описание в отдельной функции, а все функции в одном классе и совместно использовать проанализированный AST, а не передавать его каждый раз.
Вы можете заменить встроенный код введенным кодом jQuery и протестировать его.
В общем, было не так уж много c̶h̶e̶e̶s̶e̶ кодирования. Однако этого решения по-прежнему нет, поскольку оно не охватывает все возможные сценарии. Вот неполный список сценариев, которые не рассматриваются:
- В коде могут быть другие массивы, соответствующие тому же описанию.
- Дополнительных функций может быть несколько.
- Функция декодирования может использовать API-интерфейс браузера (например, проверка location.href), который изначально не будет работать в нашей среде NodeJS.
- В коде может быть более одного запутанного раздела.
- Массив может быть определен в одной строке и заполнен в другой.
Надеюсь, мне удалось объяснить, как использовать flAST для создания лаконичного и эффективного кода, говорящего структурами узлов и связями.
Путешествие до сих пор
То, чем я поделился до сих пор, — это то, как началось мое путешествие по деобфускации. Как это выглядит сейчас?
Вы можете убедиться в этом сами!
Я сузил некоторые описания обфускации в своем Детекторе обфускации, и для некоторых из этих типов обфускации REstringer предоставляет специальные препроцессоры для удаления ловушек или упрощения кода, прежде чем переходить к более общим попыткам деобфускации.
Например, обфускация Caesar+, которую я разобрал в статье Deobfuscating Caesar+, имеет внешний слой, который действует как своего рода упаковщик, объединяющий упакованную строку кода с помощью элементов HTML. Этот метод используется для предотвращения запуска кода вне среды браузера. Для автоматизации распаковки в среде nodeJS используется смоделированная среда браузера через jsdom.
Основная логика деобфускации изложена в основном методе deobfuscate:
Прежде всего, необходимо определить тип обфускации, запустить соответствующие препроцессоры и настроить все соответствующие постпроцессоры. Затем основные методы деобфускации запускаются в цикле до тех пор, пока они не перестанут быть эффективными. Затем к деобфусцированному коду применяются постпроцессоры.
Наконец, код нормализуется (например, преобразование bracket['notation'] в dot.notation) и удаляется любой мертвый код, если выбран этот параметр.
Безопасный и небезопасный — это термины, указывающие, использует ли метод eval для разрешения вывода кода или нет. Использование eval считается небезопасным, даже при запуске его в среде песочницы, такой как vm2.
Этот цикл устроен таким образом, что безопасные методы выполняются до тех пор, пока не исчерпают себя, а затем небезопасные методы запускаются один раз. Затем цикл повторяется. Это сделано для того, чтобы избежать слишком энергичных оценок кода, который можно деобфусцировать с помощью других методов, дающих более точные результаты.
Метод runLoop берет массив методов деобфускации и… ну, запускает их в цикле (удивлен, правда?). Он делает «моментальный снимок» кода перед запуском и сравнивает его после каждого цикла. Если снимок соответствует текущему состоянию кода, это означает, что ни один из методов не внес никаких изменений, и цикл можно завершить. Также соблюдается максимальное количество циклов, чтобы избежать сценария бесконечного цикла. Вот очищенная версия этого метода:
Это описание было бы неполным без списка доступных в настоящее время безопасных и небезопасных методов:
В будущем я хотел бы более подробно рассказать о том, как я реализовал механизм eval, как работает кэширование, какие решения я принял относительно того, что можно и что нельзя деобфусцировать в любой момент времени, или как я рекурсивно собираю контекст.
В репозитории гораздо больше документации и комментариев.
Куда мы идем? Куда мы сейчас идем?
Этот проект был со мной с тех пор, как я начал работать в PerimeterX, и я очень благодарен за предоставленную возможность и время для работы над таким интересным долгосрочным проектом.
REstringer был закодирован, рефакторинг, переписан, измельчен, склеен обратно, переведен, переименован, потерян, найден, подвергнут общественному расследованию, запрошен, снова потерян и, наконец, одобрен для выпуска с открытым исходным кодом. Какое путешествие!
REstringer великолепен, но он далек от совершенства и полноты. Я собираюсь продолжать в том же духе и надеюсь, что это будет полезно другим исследователям и энтузиастам запутывания, которые могут использовать и вносить свой вклад по своему усмотрению.
Спасибо за прочтение! Я надеюсь, что мы все снова встретимся в REstringer 2: В поисках большего запутывания, и да пребудет с вами Шварц!