
Веб-API повсюду, и мы, как разработчики, обычно тратим много времени на их создание и обновление. Хотя наиболее распространенными реализациями являются REST API, существуют альтернативы, с которыми вы, возможно, не экспериментировали. Цель этой статьи — представить одну из таких альтернатив — GraphQL.
Что такое GraphQL?
GraphQL — это язык запросов и манипулирования данными с открытым исходным кодом в сочетании с кроссплатформенной серверной средой выполнения, которая обеспечивает основу для масштабируемой и эффективной связи для веб-приложений. Несмотря на свое название, это не замена системам баз данных. Вместо этого он предоставляет веб-клиентам систему для запроса данных API или управления ими путем указания необходимых объектов и полей, в то время как среда выполнения на стороне сервера взаимодействует с базой данных.
Это похоже на REST API?
Между REST и GraphQL есть сходство. Оба охватывают межмашинное взаимодействие, чаще всего между клиентом веб-приложения и внутренним сервером. Оба часто используют JSON для передачи информации в запросах. Однако их возможности и цели различны. GraphQL ведет себя как запрашиваемая иерархическая строго типизированная модель данных. REST — это более свободный и общий набор принципов проектирования веб-API. GraphQL — это протокол прикладного уровня, работающий на стороне сервера, а REST определяет архитектурный стиль.
Давайте рассмотрим сценарий, в котором мы хотим получить имя автора блога, название всех постов, которые он написал, и имя его последних трех подписчиков.
REST API получает запросы и отправляет ответы по протоколу HTTP. Он использует методы HTTP, такие как GET, POST, PUT и DELETE, с шаблонами URL и параметрами для указания действия. Для каждого запроса может быть выполнен только один шаг, а возвращаемые данные обычно имеют фиксированный формат. Типичный REST API потребует следующих шагов для получения необходимых данных.
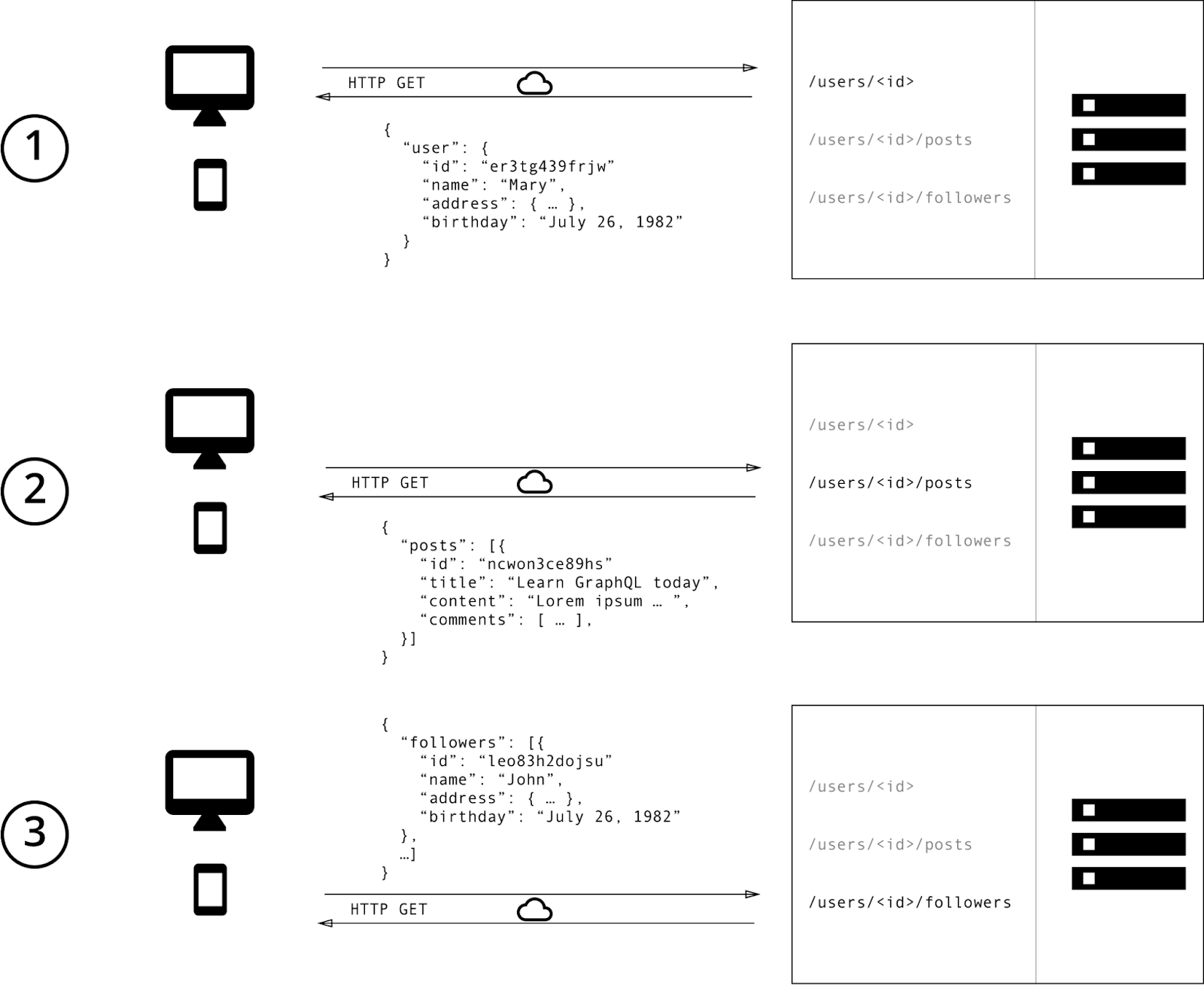
Для получения нужных данных требуется три запроса, и есть ненужные элементы данных. Давайте немного поговорим об этом.
Запрос к /users/<id> дает нам некоторую базовую информацию о пользователе, но не дает всего необходимого. Этот сценарий называется при извлечении и вынуждает клиента выполнять дополнительные вызовы в другом месте, чтобы получить необходимые данные.
Что, если у нас есть список пользователей и нам нужна одна и та же информация для каждого пользователя? Нам нужно будет вызвать конечные точки /users/<id>/posts и /users/<id>/followers для каждой записи пользователя. Этот сценарий представляет собой проблему n+1 и может быстро выйти из-под контроля по мере роста списка пользователей.
Как насчет всех ненужных данных, возвращаемых каждой из трех конечных точек? Этот сценарий называется избыточной выборкой, что приводит к увеличению размера данных и влияет на стоимость и предполагаемую производительность.
Как мы можем решить эти проблемы? Мы могли бы создать конечные точки REST для каждого варианта использования — это реактивный подход, и его может быть сложно масштабировать в соответствии с потребностями клиентов. Давайте посмотрим, как GraphQL решает эти проблемы.
Хотя GraphQL также получает запросы и отправляет данные по протоколу HTTP, он использует ограниченный набор методов HTTP, таких как GET или POST, и клиент может запрашивать одно или несколько действий или отношений из одной конечной точки запроса. Полезная нагрузка запроса указывает точные необходимые данные, а возвращаемые данные всегда в формате JSON. Эквивалентный поток GraphQL для пользовательского примера REST API будет выглядеть следующим образом.
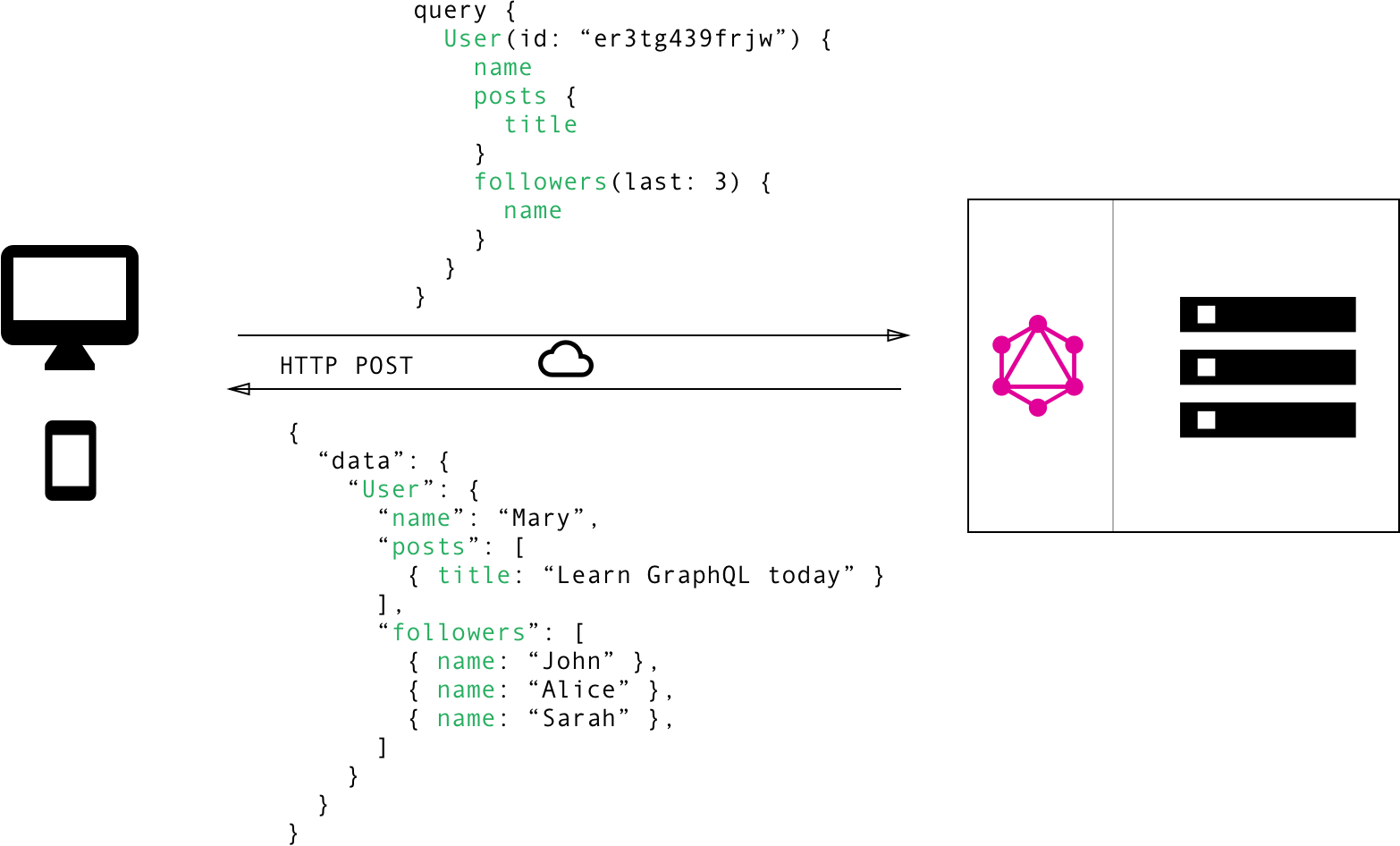
Это эффективный подход: клиент определяет, что нужно, делает один запрос, чтобы получить все необходимые данные, а сервер возвращает только запрошенные данные.
Опять же, хотя между REST API и GraphQL есть сходство, их возможности сильно различаются.
Давайте рассмотрим это подробнее в следующем разделе.
Контракты и безопасность типов со схемами GraphQL
Основная проблема с сервисами на основе JSON заключается в отсутствии строгого встроенного контракта относительно того, что может ожидать клиент, и точного типа данных для каждого объекта или свойства.
Контракты в большинстве API-интерфейсов REST на основе JSON состоят из документации и командного взаимодействия, которые не являются гарантиями времени выполнения. Такой подход к контрактам может привести к недопониманию и не имеет автоматической проверки для обеспечения соблюдения.
JSON также ограничен количеством нативных типов данных — строк, чисел, логических значений, массивов, общих объектов и null — и не может быть расширен для предоставления дополнительных универсальных типов данных с проверкой типов.
GraphQL решает эти проблемы, используя расширяемую и надежную схему на основе типов для определения возможностей API. Схемы определяются с использованием языка определения схем (SDL). SDL имеет простой синтаксис и позволяет использовать краткую схему. Схема конечной точки GraphQL доступна как серверу, так и клиенту, и каждый запрос и ответ проверяются перед запросом или отправкой данных.
Схема GraphQL для нашего примера авторов блогов может выглядеть так:

В этом примере есть что распаковать. Хотя это только царапает поверхность, основные моменты здесь таковы:
type Query— это объект особого типа. Объект Query содержит все точки входа верхнего уровня для запроса данных, напримерgetUser(id: ID!).- SDL позволяет добавлять комментарии в строке, чтобы объяснить их поведение или использование. Хотя в моем примере показан комментарий для точки входа
getUser(id: ID!), вы можете добавлять комментарии где угодно. - Точки входа могут принимать параметры и возвращать данные. Параметры и возвращаемые данные всегда имеют типы данных.
- Другие типы —
User,Post,AddressиPostComments— определяют объекты службы. В каждом объекте перечислены поля, и каждое поле связано с типом данных. - SDL определяет некоторую базу типов данных, таких как
IDиString, называемых скалярами. Вы можете определить пользовательские скалярные типы. Я создал пользовательские скалярные типыISO8601DateиISO8601DateTime, чтобы указать, что эти типы имеют определенный формат. - Точка входа или поле могут возвращать массив значений, обозначенный как
[]. - Наличие символа «
!» означает, что поле или возвращаемое значение не будут нулевыми. - Поля объекта могут иметь аргументы, например
followers(last: Int), что позволяет клиентам фильтровать или ограничивать подполя.
Каждая служба GraphQL имеет только одну схему, и эта схема определяет действия, объекты, отношения и типы данных, которые должен ожидать клиент.
Как насчет повторного использования объектов и данных?
Вы можете захотеть ссылаться на объекты службы за пределами одной службы; объект User — отличный пример. Одним из возможных решений является дублирование всех пользовательских данных между службами GraphQL, но такой подход создает тесную связь и усложняет работу. Используя распределенную архитектуру GraphQL для объединения нескольких схем GraphQL, нет необходимости дублировать пользовательские данные или вводить тесную связь. Давайте посмотрим, как это работает, в следующем разделе.
Объединение нескольких схем GraphQL
Вы можете создать одно монолитное приложение вместо того, чтобы жонглировать многочисленными сервисами GraphQL. Этот подход избавляет от необходимости комбинировать различные схемы; однако ваш вариант использования может потребовать микросервисного подхода для масштабирования определенных компонентов вашей системы или обеспечения принципа разделения задач.
Для последнего мы рассмотрим распределенную архитектуру GraphQL Apollo Federation (федерация).
Существует множество распределенных архитектур и методов GraphQL для достижения этой цели — слияние схем, сшивание схем, обертывание схем и объединение. В этой статье я сосредоточусь на федеративном подходе, поскольку он подходит для моего примера.
Федерация представляет шлюз, называемый шлюзом суперграфа, который объединяет несколько схем службы GraphQL в единый граф или суперграф. Каждая служба GraphQL, зарегистрированная в шлюзе суперграфа, называется службой подграфа, и схема каждой службы подграфа объединяется в суперграф, обслуживаемый шлюзом суперграфа. Клиенты взаимодействуют со шлюзом суперграфа, а шлюз суперграфа направляет запросы в соответствующую службу подграфа.
Давайте разделим наш пример схемы авторов блогов на два подграфа — подграф «Пользователи», который обрабатывает User и Address, и подграф «Сообщения», который обрабатывает Post и PostComment. Мы хотим, чтобы веб-клиенты взаимодействовали со шлюзом суперграфа, а шлюз суперграфа перенаправлял бы запросы к соответствующему подграфу после их регистрации.
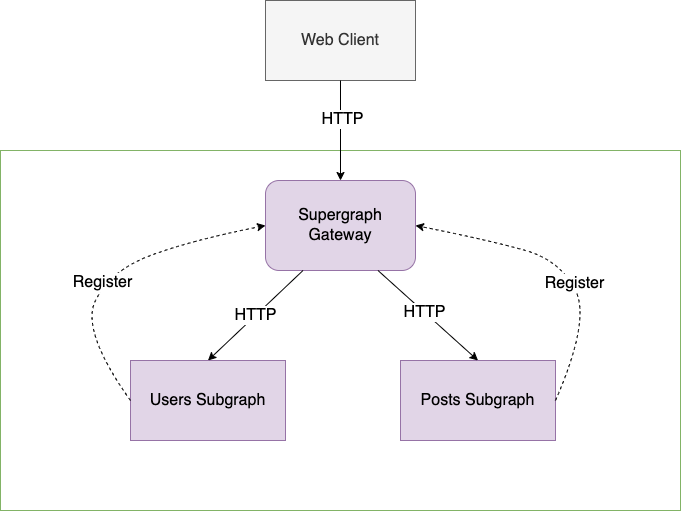
Такой подход обеспечивает большую гибкость при проектировании архитектуры. Давайте посмотрим, как наша исходная схема GraphQL может быть разделена по микросервисам.

В этом примере мы разделяем наши микросервисы по доменам — один микросервис для обработки пользовательских данных, а другой — для обработки данных публикаций и комментариев. Хотя формат похож на наш предыдущий пример, есть несколько новых концепций.
- В подграфе пользователей вы увидите, что тип
Userтеперь имеет атрибут@key(fields: "id"). Директива key указывает, что значенияUserмогут быть однозначно идентифицированы значениемid, и разрешает извлечение пользовательских записей из внешних ссылок. - Подграф сообщений также имеет тип
User. Однако его версия упрощена и содержит только идентификатор пользователя и ссылку на посты пользователя. Мы используем ключевое слово extends, чтобы расширить тип User SubgraphUser, чтобы включить атрибутposts: [Post!]!. - И, наконец, директива external помечает атрибут
User.idподграфа сообщений как принадлежащий отдельному сервису. Микросервису Posts Subgraph потребуется указать только значениеUser.id. Шлюз суперграфа будет запрашивать микрослужбу подграфа пользователей, чтобы предоставить оставшиеся пользовательские данные, прежде чем возвращать результат веб-клиенту.
Это выгодно, потому что разработчикам, работающим над микросервисом Posts, нужно хранить только идентификатор пользователя, хранение других атрибутов пользователя не дублируется, а веб-клиенту нужно сделать только один запрос.
Мысли разработчиков
GraphQL предлагает большую ценность за счет снижения требований к пропускной способности и ускорения запросов веб-клиентов. Однако никогда не бывает серебряной пули, которая решит все проблемы, и реализации GraphQL могут потребовать тщательного планирования. Я не рекомендую отказываться от существующих API REST и заменять их реализацией GraphQL.
Тем не менее, GraphQL — отличный выбор, когда вам нужно поддерживать различные клиентские представления, быть эффективным с пропускной способностью и хранилищем данных, масштабировать в зависимости от задач и беспрепятственно объединять несколько микросервисов в одну конечную точку.
Преимущества:
- Снижение требований к пропускной способности — клиенты запрашивают только то, что необходимо
- Снижает или устраняет необходимость в отдельных дополнительных приложениях Backend for Frontend.
- Поощряет разделение интересов
- Широкая языковая поддержка, как указано на странице Поддержка языка GraphQL.
- Доступны варианты с открытым исходным кодом и коммерческой поддержки
Недостатки:
- Крутая кривая обучения
- Требуется дополнительное планирование при объединении нескольких услуг
- Сложные и динамические структуры данных сложнее кэшировать
Заключение
GraphQL предоставляет функциональные возможности для определения расширяемой и надежной схемы на основе типов для определения возможностей API. Схема является самодокументируемой и сообщает пользователю, чего ожидать и как ее использовать. Запросы и ответы проверяются, чтобы гарантировать, что действие, запрошенные данные и возвращенные данные соответствуют тому, что доступно в схеме. Пользователи указывают точные объекты и поля, необходимые для точек входа, и возвращаются только эти данные.
Несколько сервисов GraphQL можно комбинировать и обслуживать с одного URL-адреса с помощью различных методов. Мы кратко рассмотрели, как это будет работать с использованием распределенной архитектуры GraphQL Apollo Federation (федерация).
Я лишь поверхностно коснулся того, что может предоставить GraphQL и как он работает. Однако у вас должно быть общее представление о том, что такое GraphQL и чем он отличается от REST API.

О данных миссии:
Мы дизайнеры, инженеры и стратеги, создающие инновационные цифровые продукты, которые меняют способ ведения бизнеса компаниями. Узнать больше: https://www.missiondata.com.