Наша двухнедельная подборка обязательных к прочтению сообществ для сообщества
Работать с данными сложно. Первая проблема возникает, когда нам нужно его импортировать. Обычно нам приходится иметь дело с широким спектром форматов, типов, форм и спецификаций баз данных. После того, как мы, наконец, импортировали и предварительно обработали наши данные, мы можем захотеть смоделировать их для получения прогнозов. На этом этапе нам нужно пройти через море библиотек машинного обучения, зависимостей, возможных несовместимостей и быть готовыми отладить их, чтобы получить работающую модель. Не говоря уже о том, что если мы хотим сравнить производительность разных алгоритмов, нам нужно повторить процесс несколько раз. Наконец, если мы хотим визуализировать наши результаты и создать интерактивную информационную панель для отчетов, нам нужно очень хорошо разбираться в JavaScript-кодировщиках, иначе мы, вероятно, создадим непривлекательные визуализации. Разве не было бы здорово сделать все вышеперечисленное в полностью интегрированной, бесплатной и открытой среде, которая позволяет проводить сквозную аналитику данных без кода?
Статьи, которые мы выбрали для этого выпуска Workflow, иллюстрируют, как KNIME может охватить все этапы проекта по науке о данных (даже сложного и четко сформулированного!). От проницательного и простого руководства по многим форматам данных и типам баз данных, к которым можно получить доступ всего несколькими щелчками мыши, до вдохновляющего решения без кода для обнаружения мошенничества с использованием машинного обучения и глубокого обучения — вы избалованы выбором, когда дело доходит до приема данных. и моделирование. А как насчет создания пользовательских отчетов? В последней статье представлено введение в узлы виджетов KNIME и показано, как использовать их возможности для параметризации и настройки ваших информационных панелей. Вы уже создаете свое комплексное приложение?

Доступ к данным с помощью KNIME, SQL и Co
Автор Деннис Ганзароли
Первым шагом в любой задаче, управляемой данными, является импорт данных для дальнейшей обработки. Данные могут быть разной формы, формы, могут делиться на несколько типов, храниться локально или в облачных сервисах. Есть ли инструмент, который лучше всего подходит для обработки их всех? Ответ - да! В этом проницательном руководстве Деннис Ганзароли фокусируется на узлах KNIME, которые позволяют вам получать файлы CSV и Excel, получать доступ к файлам SAS или SPSS и подключаться к данным, хранящимся в базах данных SQLite и MongoDB. Он дает краткие теоретические пояснения, четкие инструкции по установке специальных расширений и/или подключаемых модулей, а также создает примеры рабочих процессов, которые помогут вам начать работу. Работаете ли вы с традиционными электронными таблицами, изображениями, текстами, аудиофайлами, базами данных SQL (MySQL, Snowflake, Oracle, Amazon Redshift, Microsoft SQL Server, H2 и т. д.) и базами данных NoSQL (MongoDB, AmazonDynamoDB, OrientDB и т. д.) — вы назови это! — KNIME может справиться с ними полностью без кода!
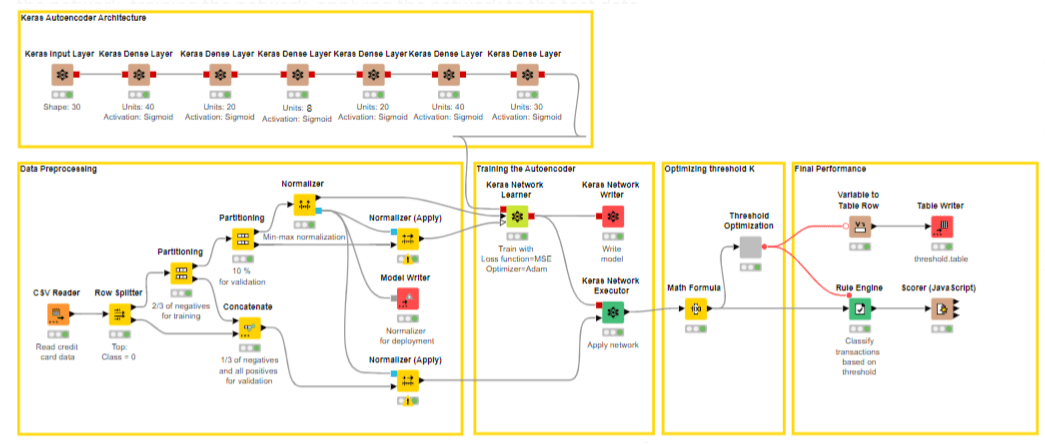
Обнаружение мошенничества с использованием Random Forest, Neural Autoencoder и Isolation Forest
Авторы Кэтрин Мельчер и Розария Силипо
В связи с ростом убытков от мошенничества с кредитными картами во всем мире важно, чтобы банки, а также компании электронной коммерции могли обнаруживать мошеннические транзакции до того, как они будут успешно завершены. За прошедшие годы был предложен ряд аналитических методов, в основном связанных с обнаружением аномалий в науке о данных. Большинство этих методов можно свести к двум основным сценариям в зависимости от доступного набора данных: A) набор данных содержит достаточное количество примеров мошенничества; Б) в наборе данных нет (или есть незначительное количество) примеров мошенничества. В этой статье Kathrin Melcher и Rosaria Silipo показывают, как выявлять мошеннические транзакции с помощью бескодового подхода с использованием KNIME. Если в наборе данных имеется достаточное количество примеров мошенничества, используются контролируемые алгоритмы машинного обучения для классификации, такие как случайный лес; в противном случае авторы реализуют либо подход к обнаружению выбросов с использованием метода изолированного леса, либо обнаружение аномалий с использованием нейронного автоэнкодера. Отличное чтение, которое вы не должны пропустить!
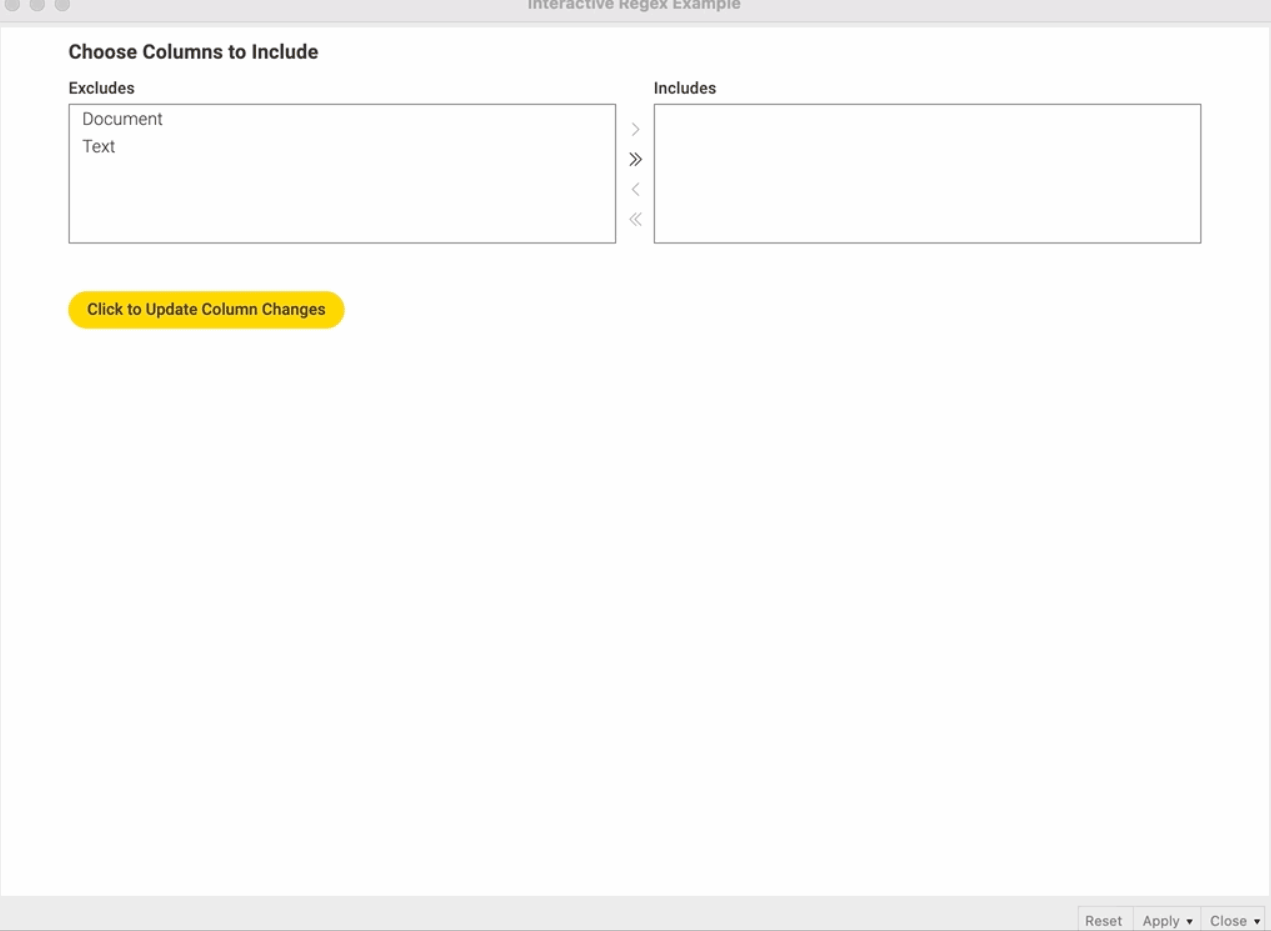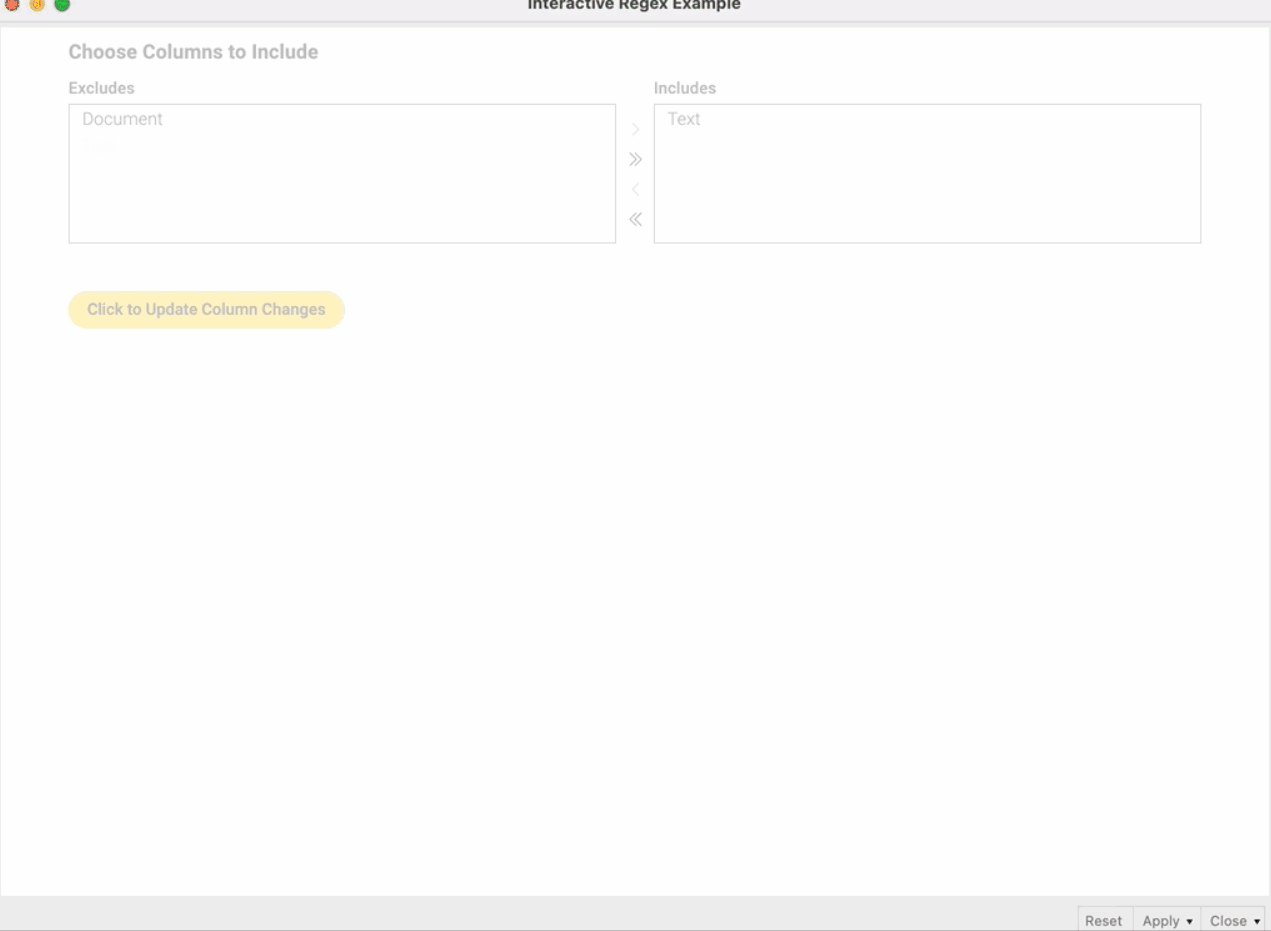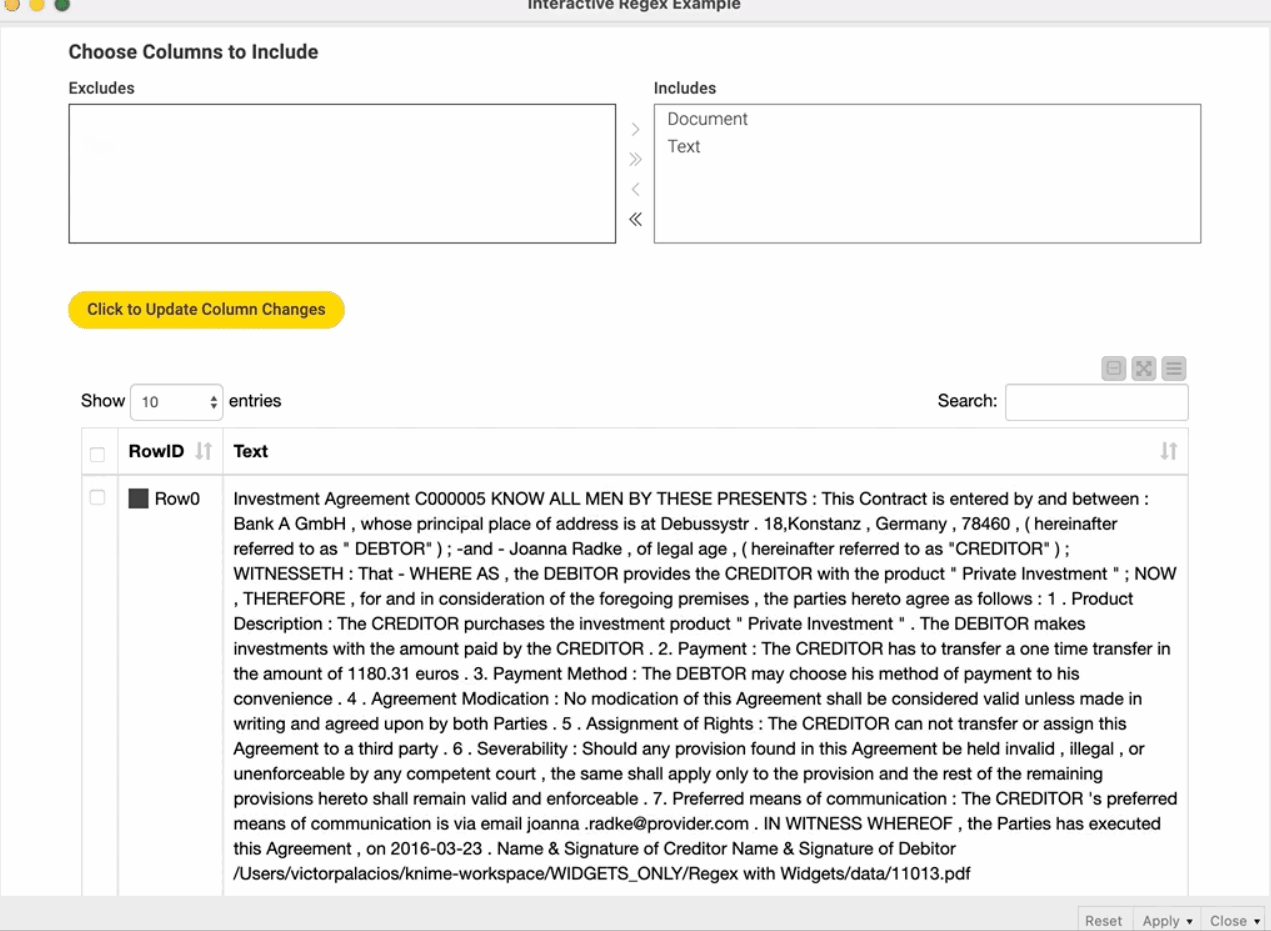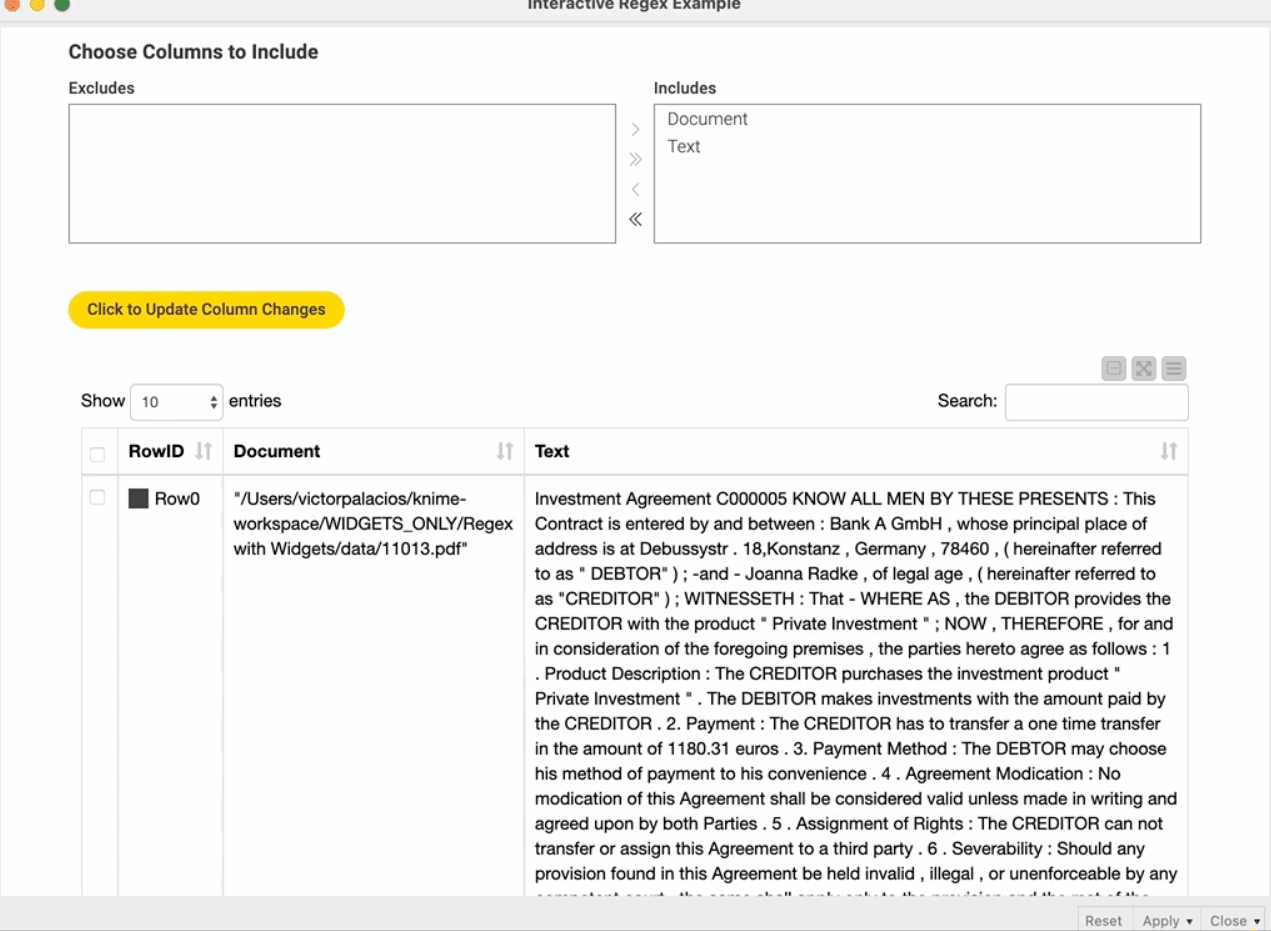
Удивительный мир виджетов! Мини-руководство по использованию узлов виджетов KNIME
Автор Виктор Паласиос
Что такое узлы виджета KNIME? Какие типы узлов виджетов существуют? Можно ли их использовать для создания приложений данных? Вы можете использовать узлы виджетов в своих рабочих процессах KNIME, чтобы обеспечить взаимодействие с вашим анализом данных, выбирая, фильтруя и вводя значения, а также применяя новые настройки в интерактивном представлении. В этом руководстве Виктор Паласиос предоставляет читателям подробное мини-руководство по использованию узлов виджета KNIME. После определения того, что такое виджеты, он описывает существующие типы, их ключевые функции и создает полезный пример рабочего процесса для интерактивного анализа документов с использованием регулярных выражений. Конечно, узлы виджетов можно использовать локально или на веб-портале KNIME. Каков ваш вариант использования узлов виджетов?
Нам нравится изучать новые творческие решения с использованием KNIME из статей, которые мы публикуем, и мы любим делиться ими с вами. Мы гордимся тем, что вместе создали процветающее сообщество, которое поддерживает друг друга, делится опытом и формирует будущее науки о данных с низким кодом.
Увидимся в следующем рабочем процессе,
Редакторы Low Code для продвинутой науки о данных
PS:📅 #HELPLINE. Хотите обсудить свою статью? Нужна помощь в структурировании вашей истории? Назначьте свидание с редакцией через Calendly (каждый второй четверг).