Существует два типа моделей линейной регрессии — простые и множественные. Начнем с основ, простой регрессионной модели (y=thetha0+thetha1x, y=mx+c), где количество атрибутов = 1. Я выделю основные шаги, которым нужно следовать, а также добавлю новое тестирование набора данных — эксцесс. и асимметрия. Мы создаем модель, которая будет прогнозировать акции Exxon по мере роста цен на нефть.
Шаг 1. Импортируйте библиотеки и загрузите набор данных
#importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error,r2_score,mean_absolute_error
%matplotlib inline
#loading the dataset
price_df = pd.read_excel('C:\\..\..\\Downloads\\oil_exxon.xlsx')
#making date column to be the index
price_df.index= pd.to_datetime(price_df['date'])
#dropping the old date column
price_df = price_df.drop(['date'],axis=1)
price_df.head()
Шаг 2. Очистка данных (удаление нулевых значений)
Этот шаг является важным, поскольку набор данных может содержать тысячи записей, и некоторые из них могут иметь значения NaN. Иногда набор данных требует от нас заполнить эти значения NaN, а иногда мы можем просто их отбросить. Мы также исключаем любые несоответствия в наборе данных, такие как проверка dtypes и переименование/замена значений по мере необходимости.
price_df.info() => finding the datatypes of the dataset display(price_df.isna().any()) price_df=price_df.dropna() display(price_df.isna().any()) exxon_price False oil_price False dtype: bool exxon_price False oil_price False dtype: bool
Шаг 3. Исследовательский анализ данных
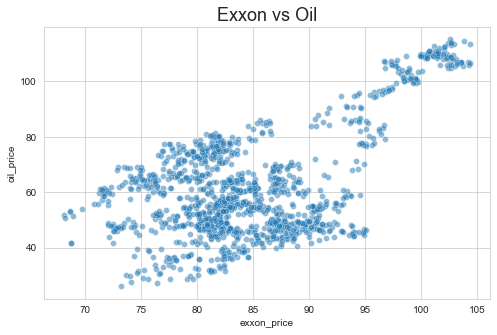
Мы делаем диаграмму рассеяния и пытаемся визуализировать набор данных, связаны ли значения друг с другом. Мы также делаем тепловую карту, чтобы увидеть корреляцию между oil_prices и exxon_prices.

Шаг 4. Проверка на выбросы и асимметрию
Асимметрия — это симметрия распределения, тогда как эксцесс — это точечность распределения. Нам не нужны выбросы, и мы хотим убедиться, что наши данные не имеют перекоса, потому что это может повлиять на результаты в определенных моделях. Сначала мы строим гистограмму как для цены на нефть, так и для цены Exxon, а затем делаем некоторые расчеты, чтобы проверить, верны ли визуализации.

Exxon kurtosis : 0.08839 Oil kurtosis : 0.5321 Exxon skewness : 0.66 Oil skeweness : 1.0
После расчета мы замечаем, что цена на нефть сильно искажена, но, поскольку эти данные включают только один атрибут, мы можем с этим работать.
Шаг 5. Создайте модель
Теперь самое интересное, мы собираем нашу собственную модель! Сначала нам нужно разделить набор данных на цель и переменную (переменные). Затем с помощью функции train_test_split мы создадим экземпляры для обучения и тестирования. После этого мы построим модель линейной регрессии и поместим в нее обучающие экземпляры.
Теперь мы узнаем коэффициент и перехват набора данных, а также найдем прогнозируемые значения, чтобы мы могли оценить нашу модель на следующем шаге.
The coefficient of our model is 0.23 The intercept of our model is 70.55 This means that a single unit increase in oil is associated with a 0.23 increase in the Exxon stock price. The predicted value is 88.09(for 76.43)
Шаг 6. Оценка модели
Мы оцениваем модель на основе фактических значений y (целевых) и значений y, предсказанных нашей моделью. sklearn.metrics предоставил массу методов оценки -
Средняя абсолютная ошибка (MAE). Среднее значение абсолютного значения ошибок. Среднеквадратическая ошибка (MSE): среднее значение квадратов ошибок. MSE более популярен, чем MAE, потому что MSE «наказывает» за более серьезные ошибки. КореньСреднеквадратическая ошибка (RMSE): квадратный корень из среднего квадрата ошибок. RMSE даже более предпочтителен, потому что он позволяет нам интерпретировать вывод в y-единицах. Метрика R в квадрате помогает измерить качество соответствия или то, насколько хорошо наши данные соответствуют модели. Чем выше значение R-квадрата, тем лучше данные соответствуют модели.
MSE = 38.75 MAE = 5.05 RMSE = 6.225 R2: 0.36 -> R2 depends on the domain of the dataset and we can say that for ours, it is a good value.
Шаг 7. Построение линии регрессии
Это последний шаг, и к настоящему времени мы создали нашу модель и оценили ее на основе прогнозируемых значений, теперь нам нужно построить линию регрессии. Для этого сначала нам нужно построить диаграмму рассеяния на основе наших данных тестирования, а затем построить линию на основе предсказанного значения y. Эта линия является наилучшей линией для данного набора данных.

Путь к обучению машинному обучению под руководством: @sigma coding(YT)