Все, что вам нужно знать об этой библиотеке для масштабируемой настройки гиперпараметров моделей машинного обучения

Оптимизация гиперпараметров модели (или настроек модели), пожалуй, самый важный шаг в обучении алгоритма машинного обучения, поскольку он приводит к поиску оптимальных параметров, которые минимизируют функцию потерь вашей модели. Этот шаг также важен для построения обобщающих моделей, не склонных к переоснащению.
Наиболее известными методами оптимизации гиперпараметров модели являются исчерпывающий поиск по сетке и его стохастический аналог: случайный поиск по сетке. В первом методе пространство поиска определяется как сетка по области каждого из гиперпараметров модели. Оптимальные гиперпараметры получаются путем обучения модели в каждой точке сетки. Хотя поиск по сетке очень прост в реализации, он требует значительных вычислительных ресурсов, особенно когда число оптимизируемых переменных велико. С другой стороны, поиск по сетке andom — более быстрый метод оптимизации, дающий лучшие результаты. При поиске по случайной сетке наилучшие гиперпараметры получаются путем обучения модели только на случайной выборке точек из пространства сетки.

Долгое время оба алгоритма поиска по сетке широко использовались учеными для поиска оптимальных гиперпараметров модели. Однако эти подходы обычно находят гиперпараметры модели, для которых функция потерь далека от глобального минимума.
История изменилась в 2013 году, когда Джеймс Бергстра и его сотрудники опубликовали статью, в которой они исследовали метод байесовской оптимизации, чтобы найти лучшие гиперпараметры нейронной сети классификации изображений. Они сравнили результаты с результатами, полученными при случайном поиске по сетке. Было ясно, что байесовский метод превзошел поиск по случайной сетке:
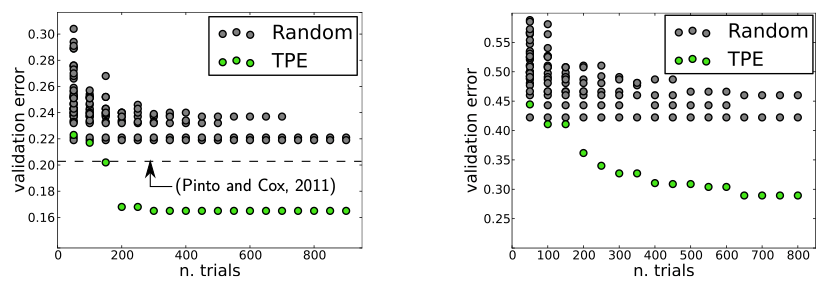
Но почему байесовская оптимизация лучше любого из алгоритмов поиска по сетке? Потому что это один из управляемых методов, который выполняет интеллектуальный поиск гиперпараметров модели, а не методом проб и ошибок.
В этом блоге мы рассмотрим байесовский метод оптимизации и рассмотрим одну из его реализаций с помощью относительно нового пакета Python под названием Mango.
Коротко о байесовской оптимизации
Прежде чем объяснять, что делает Mango, нам нужно понять, как работает байесовская оптимизация. Если вы хорошо понимаете этот алгоритм, можете смело пропустить этот раздел.
Байесовская оптимизация состоит из 4 компонентов:
- Целевая функция. Это истинная функция, которую вы хотите минимизировать или максимизировать. Это может быть, например, среднеквадратическая ошибка (RMSE) в задаче регрессии или логарифмическая потеря в классификации. При оптимизации моделей машинного обучения целевая функция зависит от гиперпараметров модели. Вот почему целевая функция также известна как функция черного ящика, потому что ее форма неизвестна.
- Домен поиска или область поиска: это соответствует возможным значениям, которые может иметь каждый гиперпараметр модели. Как пользователь, вам необходимо указать пространство поиска вашей модели. Например, область поиска модели регрессора Random Forest может быть:
param_space = {'max_depth': range(3, 10),
'min_samples_split': range(20, 2000),
'min_samples_leaf': range(2, 20),
'max_features': ["sqrt", "log2", "auto"],
'n_estimators': range(100, 500)
}
Байесовская оптимизация использует определенное пространство поиска для выборки точек, которые оцениваются в целевой функции.
- Суррогатная модель: оценка целевой функции очень затратна, поэтому на практике мы знаем истинное значение целевой функции только в нескольких местах, однако нам нужно знать значения в других местах. Вот когда он входит в суррогатную модель, которая является инструментом моделирования целевой функции. Обычно в качестве суррогатной модели выбирают так называемые гауссовские процессы (ГП) из-за ее способности давать оценки неопределенности. Объяснение гауссовских процессов выходит за рамки этого сообщения в блоге, но я рекомендую вам прочитать эту выдающуюся статью, в которой много визуальных материалов, которые помогут вам интуитивно понять этот вероятностный метод.
В начале байесовской оптимизации суррогатная модель начинается с априорной функции, которая распределена с равномерной неопределенностью по пространству поиска:
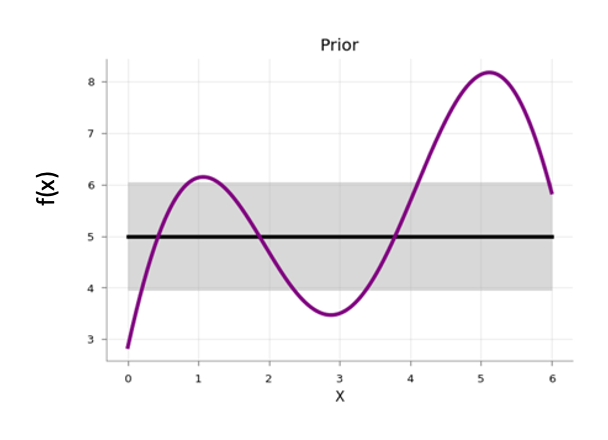
Каждый раз, когда точка выборки из пространства поиска оценивается в целевой функции, неопределенность суррогатной модели в этой точке становится равной нулю. После многих итераций суррогатная модель будет напоминать целевую функцию:

Однако целью байесовской оптимизации является не моделирование целевой функции. Вместо этого нужно найти наилучшие гиперпараметры модели за наименьшее количество возможных итераций. Для этого необходимо использовать функцию сбора данных.
- Функция сбора данных. Эта функция введена в байесовской оптимизации для управления поиском. Функция получения используется для оценки того, желательно ли оценивать точку на основе существующей суррогатной модели. Простая функция сбора данных состоит в том, чтобы выбрать точку, в которой среднее значение суррогатной функции максимально.
Шаги кода байесовской оптимизации:
Select a surrogate model for modeling the objective function and define its prior
for i = 1, 2,..., number of iterations:
Given a set of evaluations in the objective, use Bayes
to obtain the posterior.
Use an acquisition function (which is a function of the
posterior) to decide the next sampling point.
Add newly sampled data to the set of observations.
На следующем рисунке показана байесовская оптимизация для простой одномерной функции:
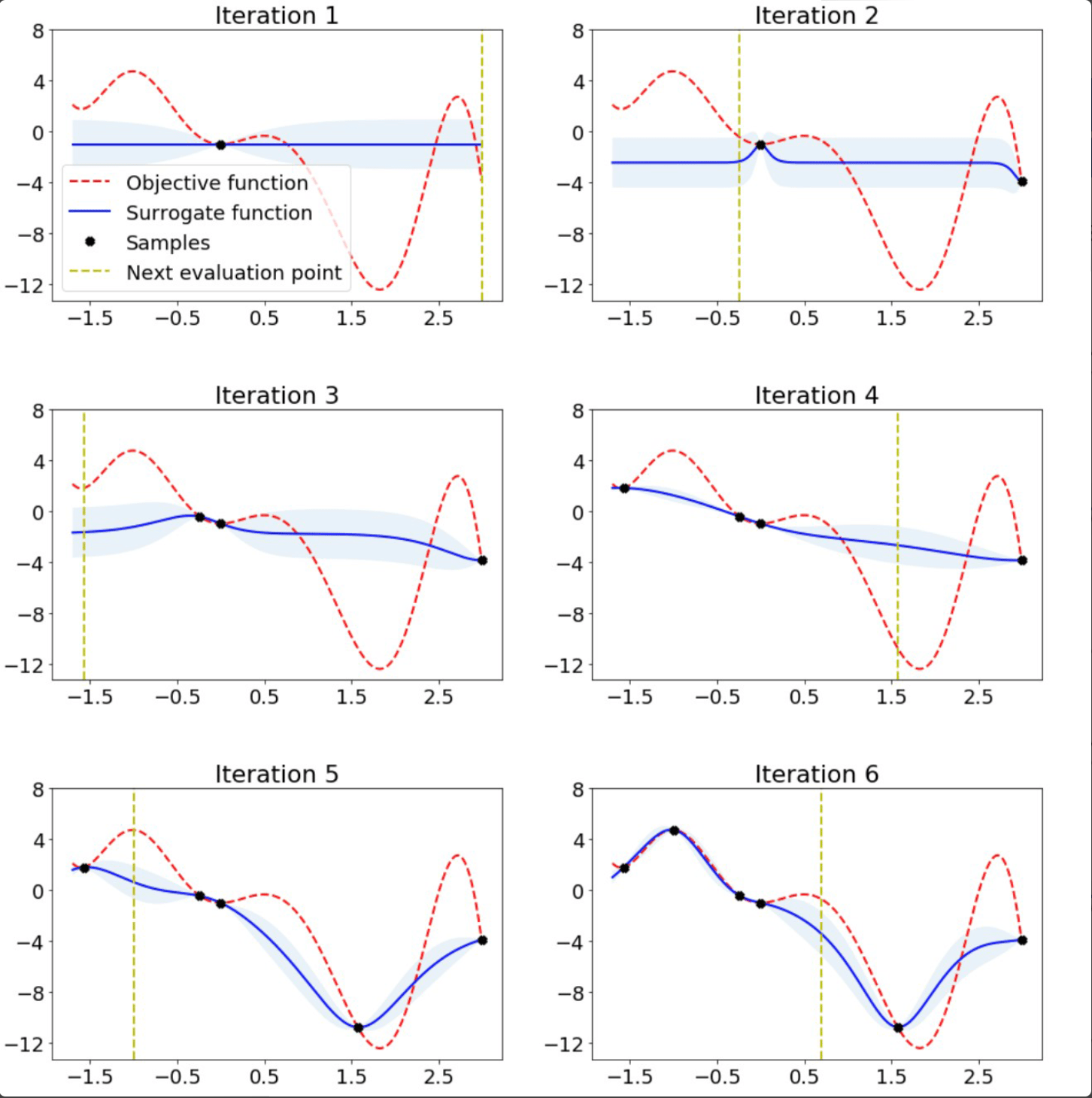
Если вам интересно узнать больше о байесовской оптимизации, я рекомендую вам прочитать эту замечательную статью:
Несколько пакетов Python используют байесовскую оптимизацию для получения наилучших гиперпараметров вашей модели машинного обучения. Некоторые примеры: Гиперопт; Оптуна; Байесовская оптимизация; Scikit-оптимизировать (скопт); GPyOpt; pyGPGO и Mango. Список обширен, и я не упоминаю другие библиотеки. Для хорошего обзора других пакетов вы можете прочитать этот пост в блоге:
Теперь давайте погрузимся в Mango!
Манго: почему оно такое особенное?
В последние годы объем данных значительно вырос. Это представляет собой проблему для специалистов по данным, которым нужна масштабируемость конвейеров машинного обучения. Распределенные вычисления могут решить эту проблему.
Распределенные вычисления относятся к набору компьютеров, которые работают над общей задачей, общаясь друг с другом. Это отличается от параллельных вычислений, когда задача делится на несколько подзадач, которые распределяются между разными процессорами в одной и той же компьютерной системе.

Хотя существует довольно много библиотек Python, использующих байесовскую оптимизацию для настройки гиперпараметров модели, ни одна из них не написана для поддержки планирования в какой-либо среде распределенных вычислений. Мотивация авторов, разработавших Mango, заключалась в создании алгоритма оптимизации, способного работать в распределенной вычислительной среде, сохраняя при этом возможности байесовской оптимизации.
В чем секрет архитектуры Mango, благодаря которой он хорошо работает в распределенной вычислительной среде? Mango имеет модульную структуру, в которой оптимизатор отделен от планировщика. Такая конструкция позволяет легко масштабировать конвейеры машинного обучения, использующие большие объемы данных. Однако эта архитектура сопряжена с проблемами в методе оптимизации, поскольку традиционный байесовский алгоритм оптимизации является последовательным, а это означает, что функция сбора данных предоставляет только одну следующую точку для оценки при поиске.
Mango использует два метода для распараллеливания байесовской оптимизации: метод, называемый пакетным гауссовским процессом бандитов, и метод кластеризации методом k-средних. В этом блоге мы не будем объяснять пакетный гауссовский процесс. Если вам интересно узнать больше об этом подходе, вы можете прочитать эту статью.
Что касается кластерного подхода, то использование кластеризации k-средних для горизонтального масштабирования процесса байесовской оптимизации было предложено группой исследователей IBM в 2018 году (см. эту статью для получения технических подробностей). Этот подход состоит из кластеризации точек, выбранных из области поиска, которые генерируют высокие значения в функции сбора (см. рисунок ниже). Вначале эти кластеры находятся далеко друг от друга в пространстве поиска параметров. По мере обнаружения оптимальных областей в суррогатной функции расстояние в пространстве параметров уменьшается. Метод кластеризации k-средних горизонтально масштабирует оптимизацию, поскольку каждый кластер используется для запуска байесовской оптимизации как отдельного процесса. Такое распараллеливание приводит к более быстрому нахождению оптимальных гиперпараметров модели.

Помимо возможности работать с распределенными вычислительными платформами, Mango также совместим с API scikit-learn. Это означает, что вы можете определить пространство поиска гиперпараметров как словарь Python, где ключами являются имена параметров модели, и каждый элемент может быть определен с любым из более чем 70 распределений, реализованных в scipy.stats. Все эти уникальные характеристики делают Mango отличной альтернативой для специалистов по обработке и анализу данных, которые хотят масштабно использовать решения на основе данных.
Если вам интересно узнать больше о внутренней работе Mango, вы можете прочитать оригинальную статью или посетить этот замечательный блог, написанный авторами библиотеки:
Простой пример
Давайте теперь проиллюстрируем, как Mango работает в задаче оптимизации. Сначала вам нужно создать среду Python, а затем установить Mango с помощью следующей команды:
pip install arm-mangoДля этого примера мы используем набор данных по жилью в Калифорнии, который можно загрузить прямо из Scikit-learn (подробнее по этой ссылке):
Этот набор данных содержит 20 640 образцов. Каждый образец имеет 8 характеристик, включая возраст дома и среднее количество спален. Набор данных о жилье в Калифорнии также включает стоимость дома для каждой выборки в единицах по 100 000 единиц. Распределение цен на жилье показано на следующем рисунке:

Обратите внимание, что распределение цен на жилье немного смещено влево. Это означает, что в цели требуется некоторая предварительная обработка. Например, мы можем преобразовать целевое распределение в нормальную форму с помощью логарифмического преобразования или преобразования Бокса-Кокса. Эта предварительная обработка может повысить эффективность прогнозирования модели за счет уменьшения целевой дисперсии. Мы сделаем этот шаг во время оптимизации и моделирования гиперпараметров. Давайте теперь разделим набор данных на обучающие, проверочные и тестовые наборы:
Мы готовы использовать Mango для оптимизации модели машинного обучения. Во-первых, мы определяем область поиска, из которой Mango получает значения. В этом примере мы используем алгоритм под названием Экстремальные рандомизированные деревья, который представляет собой метод ансамбля, очень похожий на случайный лес, за исключением способа выбора оптимального разделения, которое выполняется случайным образом. Этот алгоритм обычно уменьшает дисперсию за счет небольшого увеличения смещения. Если вам интересно узнать больше о экстремально рандомизированных деревьях, вы можете посетить эту документацию по Scikit-learn.
Пространство поиска экстремальных рандомизированных деревьев можно определить следующим образом:
Как только пространство параметров определено, мы указываем целевую функцию. Здесь мы используем наборы данных для обучения и проверки, созданные выше; однако, если вы хотите запустить стратегию перекрестной проверки k-fold, вам необходимо реализовать ее внутри целевой функции.
Важные примечания к приведенному выше коду:
· Целевая функция направлена на поиск лучших параметров модели, которые минимизируют среднеквадратичную ошибку (RMSE).
· Реализация экстремальных рандомизированных деревьев для задач регрессии в Scikit-learn называется ExtraTreesRegressor.
· Обратите внимание,что цены на жилье в наборе поездов были логарифмически преобразованы. Как следствие, прогнозы, сделанные на проверочном наборе, были преобразованы обратно в исходный масштаб.
Последним шагом, необходимым для оптимизации гиперпараметров модели, является создание экземпляра класса Tuner, отвечающего за запуск Mango:
Код выполнялся за 4,2 минуты на MacBook Pro с четырехъядерным процессором Intel Core i7 с тактовой частотой 2,3 ГГц.
Лучшие гиперпараметры и лучший RMSE соответственно:
best parameters: {‘max_depth’: 9, ‘max_features’: ‘auto’, ‘min_samples_leaf’: 85, ‘min_samples_split’: 729}
best accuracy (RMSE): 0.7418871882901833
При обучении модели на наборе поездов с лучшими параметрами модели RMSE на тестовом наборе:
rmse on test: 0.7395178741584788
Отказ от ответственности: вы можете получить другие результаты при выполнении этого кода.
Давайте кратко рассмотрим класс Tuner, используемый в приведенном выше коде. Этот классимеет много параметров конфигурации, но в этом примере мы попробовали только два из них:
num_iteration: это общее количество итераций, использованных Mango для поиска оптимального значения.initial_random: Эта переменная устанавливает количество проверенных случайных выборок. Важно: Mango возвращает все случайные выборки вместе. Это очень полезно, особенно в тех случаях, когда оптимизация должна выполняться параллельно.
Для получения дополнительной информации о других параметрах настройки Mango вы можете перейти по этой ссылке.
В примере, опубликованном в этом блоге, используется небольшой набор данных. Однако во многих реальных приложениях вы можете работать с большими файлами данных, требующими параллельной реализации Mango. Если вы перейдете в мой репозиторий GitHub, вы можете найти полный код, показанный здесь, вместе с реализацией для больших файлов данных.
Манго очень универсален. Вы можете использовать его в широком спектре машинных моделей и моделей глубокого обучения, которым требуется либо параллельная реализация, либо распределенная вычислительная среда для оптимизации их гиперпараметров. Поэтому я рекомендую вам посетить репозиторий Mango на GitHub. Там вы найдете множество записных книжек, демонстрирующих использование Mango в различных компьютерных условиях.
Принимать домашние сообщения
В этом блоге мы рассматриваем Mango: библиотеку Python для масштабируемой байесовской оптимизации. Этот пакет даст вам возможность:
- Масштабируйте оптимизацию гиперпараметров модели, вплоть до того, чтобы запустить ее в распределенной вычислительной среде.
- Легко интегрируйте модели scikit-learn с Mango для создания мощных конвейеров машинного обучения.
- Используйте любую из функций распределения вероятностей, реализованных в scipy.stats, чтобы объявить свое пространство поиска.
Все эти функции делают Mango уникальной библиотекой Python, которая расширит ваш набор инструментов для работы с данными.
Надеюсь, вы узнали что-то новое. Еще раз спасибо за чтение!