
Это третий пост из пяти частей, в которых я стремлюсь демистифицировать обработку естественного языка (НЛП) с помощью ключевого обучающего инструмента, который я бы назвал набором инструментов НЛП. Вы можете получить доступ к предыдущей статье здесь.
Краткий обзор:
- Набор инструментов НЛП — это структура, предназначенная для достижения тонкого баланса между тем, чтобы потратить время на глубокое изучение явления и быстрым беглым просмотром соответствующей работы.
- В процессе исследования есть 4 этапа, на которых мы можем применить набор инструментов НЛП: Определение проблемы, Исследование данных, Разработка функций и Подбор и оценка модели
- Учитывайте боль, доступность, конкретность, Интерес и Местоположение и население при создании задачи НЛП
- Рассмотрите технические области данных реального мира и НЛП, чтобы определить, стоит ли исследовать интересующую вас проблему.
- Составьте аннотацию (у меня было около 120 слов), которая отражает реальные и технические аспекты проблемы и предлагаемое решение, чтобы дать общую картину.
Не забывайте использовать молоток в качестве инструмента для всего!
Не все проблемы могут или должны быть решены с помощью НЛП.
Исследование данных
Данные НЛП — это, по существу, данные невизуальной коммуникации.
- Звуковые волны
- Текстовые файлы
Прежде чем приступить к изучению всех технических способов изучения этих типов данных, мы сначала возьмем из набора инструментов НЛП приведенный ниже инструмент:

- Язык. Аудио- или текстовый файл должен быть помечен тегом, определяющим язык(и), на котором был написан текст или произнесен голос (записанный в аудио).
- Идеи: представляют собой темы или темы, на которых был основан текст или аудио, и/или повторяются в тексте/аудио.
- Персонажи: это люди и/или организации, связанные с данным звуком или текстом.
На основе этой структуры необходимо ответить на следующие вопросы:

Основываясь на проблеме, над которой я работал в своей преподавательской группе Delta Analytics, анализ набора данных #KOT Twitter с использованием LIP дал следующие результаты:
Язык
75,8% твитов #KOT были помечены Twitter как англоязычные.
Некоторые твиты были многоязычными, например. «Я не знаю, если у вас есть этот друг mwenye huwa mnachat na yeye IG, FB na watsapp в то же время na kwa hzo base zote mnaongea история другая #KOT» (английский, суахили, шэн-сленг)
Идеи
Темы обычно представлены в Твиттере хэштегами. Наиболее популярными хэштегами, используемыми вместе с #KOT, были:
1. #kenya (использовано 3074 раза) — патриотический хэштег.
2. #loyals (использовано 3050 раз) — специальный хэштег Twitter, приглашающий людей подписываться друг на друга.
3. #nairobi (использовано 1196 раз) — хэштег города
4. #ikokazike (используется 1016 раз) — карьерный хэштег, используемый HR и соискателями в Кении (в переводе с английского означает «Есть работа KE (Кения)»).
5. #bbinonsense (использован 989 раз) — политический хэштег, используемый кенийцами, выступающими против BBI (Инициатива по наведению мостов).
Персонажи
10 самых упоминаемых «лиц» за последний год в Твиттере были
- политические институты, такие как
@statehousekenya(упоминается 278 раз),@dcikenya(упоминается 150 раз) и@nassemblyke(упоминается 139 раз),
- букмекерская контора,
@safebetske(упоминается 233 раза),
- такие политики, как
@railaodinga(лидер оппозиционных партий Кении, упоминается 205 раз) и@williamsruto(действующий заместитель вице-президента, упоминается 144 раза), а также
- СМИ, такие как
@citizentvkenya(упоминается 203 раза),@ntvkenya(упоминается 162 раза) и@classic105kenya(упоминается 154 раза) и
- учетная запись для вдохновения,
@dodzweit(преподобный, который публикует вдохновляющие и временами христианские материалы, упоминается 197 раз)
Возможное объяснение этого явления состоит в том, что 2022 год будет годом выборов, и два политических лидера баллотируются друг против друга и ведут предвыборную кампанию в Интернете.
Однако,
-
@dodzweitупоминался только пасторами церкви,@cotchurchhq, в основном в кратких резюме его/ее выступлений.
-
@safebetskeупоминался только форекс-трейдером@theforexguyke, в основном в ретвитах.
Мы должны помнить об этих вопросах даже тогда, когда мы переходим к более техническим способам изучения текстовых и аудиоданных.
Исследовательский анализ данных для текста
Существуют различные методы, используемые для разбивки текста и его анализа. Большое количество методов, популярных в науке о данных, как правило, применяются к высокоресурсным языкам (языкам, которые есть во многих свободно доступных текстах). Чтобы избежать этой ловушки, мы будем упрощать и применять их максимально интуитивно понятным образом на любом языке.
Чтобы компьютер «понимал» текст, он должен быть представлен в виде чисел. Процесс представления текста в виде чисел называется кодированием.
Текст в основном представлен в числовых формах как категориальные данные. Предположим, мы хотим получить значение английского предложения Hello Mary!
Что, если мы хотим идентифицировать Hello?
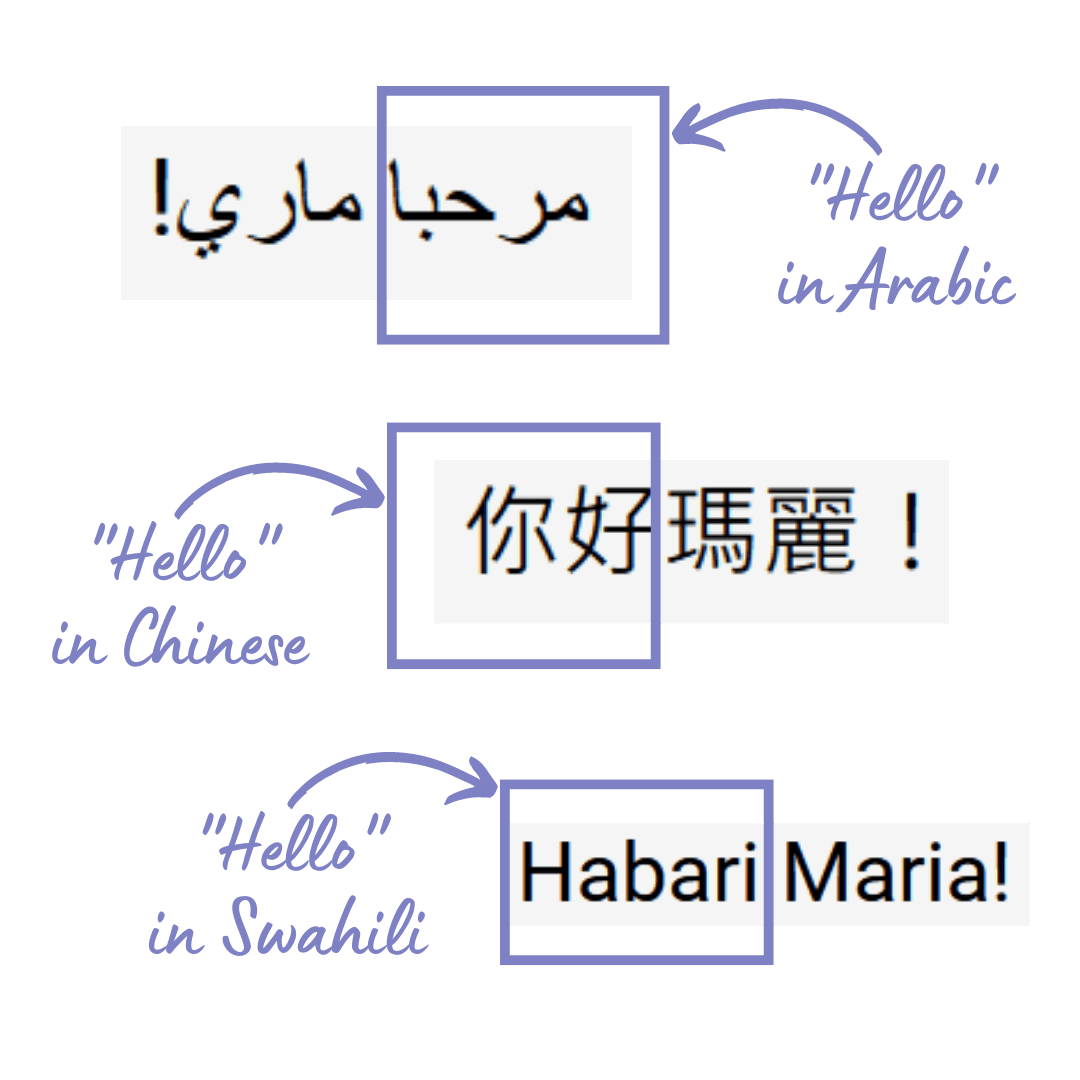
Как видите, эти 3 языка очень сильно отличаются друг от друга с точки зрения письменности; "Здравствуйте" – это первое слово, когда оно пишется на китайском и суахили, и последнее слово на арабском языке.
Если мы представим эту информацию в виде матрицы бинарных категорий, мы получим

со всеми тремя матрицами, представляющими одну и ту же информацию, "Здравствуйте, Мария"; поскольку “!” не несет сообщения (он только подчеркивает тон), он был исключен из матриц.
Это основа для большей части анализа данных и визуализации текста.
- Текст можно разбить на x документов.
- Документ можно разбить на y абзацев.
- Абзац можно разбить на z фраз.
- Фразу можно разбить на n слов.
В частотной статистике категориальные переменные должны быть представлены как
- ссылочная категория = 0
- категория2 = 1, если истина, 0, если ложь
- категория3 = 1, если истина, 0, если ложь
и т. д.
Это поможет провести следующие сравнения во время анализа:
- сравнение категории 2 с эталоном
- сравнение категории 3 с эталоном
и т. д.
Когда мы рассматриваем машинное обучение, этот принцип применяется путем создания фиктивных переменных (горячее кодирование) интересующих ключевых слов, где
- любое другое слово = 0
- ключевое слово 1 = 1, если ключевое слово 1 встречается в тексте, 0, если его нет
- ключевое слово 2 = 1, если ключевое слово 2 встречается в тексте, 0, если его нет
и т. д.
Этот подход предполагает, что положение слова во фразе или предложении не имеет особого значения, а имеет только само слово. Этот способ преобразования текста в числа называется моделью мешка слов (BOW).
BOW — очень распространенный способ анализа одноязычных данных, и если выбранные ключевые слова представляют языки в тексте, с помощью этого подхода можно анализировать даже многоязычные данные.
Однако недостатком этого подхода является то, что необходимо создать словарь слов-заполнителей (также называемых стоп-словами), чтобы очистить текст от этих слов; также краткие формы должны обрабатываться единообразно, чтобы сохранить значение корневого слова посредством образования корней и лемматизации. Текст также должен быть помечен вручную; поэтому этот подход плохо масштабируется при увеличении сложного словарного запаса и количества слов.
Что касается показателей центральной тенденции, мы можем подсчитать, сколько раз данная категория появляется, и получить «режим». Использование библиотек Python, таких как Spacy и NLTK, и библиотек R, таких как wordcloud, rtweet и tidytext (среди прочего) мы можем получить частотность слов в заданном тексте и визуализировать их в виде облака слов, где чем чаще встречается слово, тем оно больше:
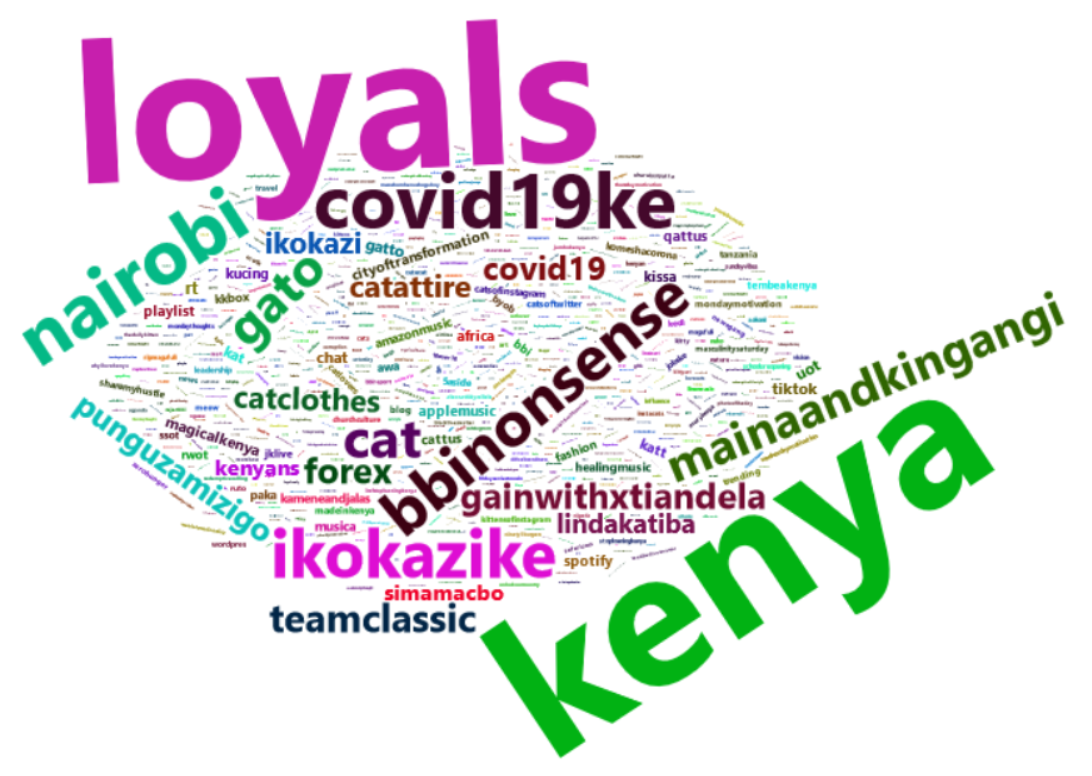
В частотной статистике, когда мы связываем две категории друг с другом, они образуют таблицу непредвиденных обстоятельств, которая может предоставить полезную информацию как есть. Проблема со словами в тексте заключается в том, что существует слишком много категорий для сравнения, что делает эту форму визуализации не очень полезной.
Чтобы компенсировать это, слова группируются в n-граммы и/или фразы соединяются специальной пунктуацией, уменьшая размерность. Затем мы можем получить частоту появления этих шаблонов и сообщить о результатах следующим образом:

или визуализировать данные следующим образом:

ПРОДОЛЖЕНИЕ СЛЕДУЕТ ЗДЕСЬ…
Дополнительные ресурсы
- Исследовательский анализ текстовых данных
- Руководство для начинающих по исследовательскому анализу данных (EDA) по текстовым данным (на примере Amazon)
- Исследовательский анализ текстовых данных: отзывы сотрудников
- Полный исследовательский анализ данных и визуализация текстовых данных
- Тесты Хи-квадрат (Χ²) | Типы, формулы и примеры
- Таблица непредвиденных обстоятельств: определение, примеры и интерпретация
- Мой маленький скребок