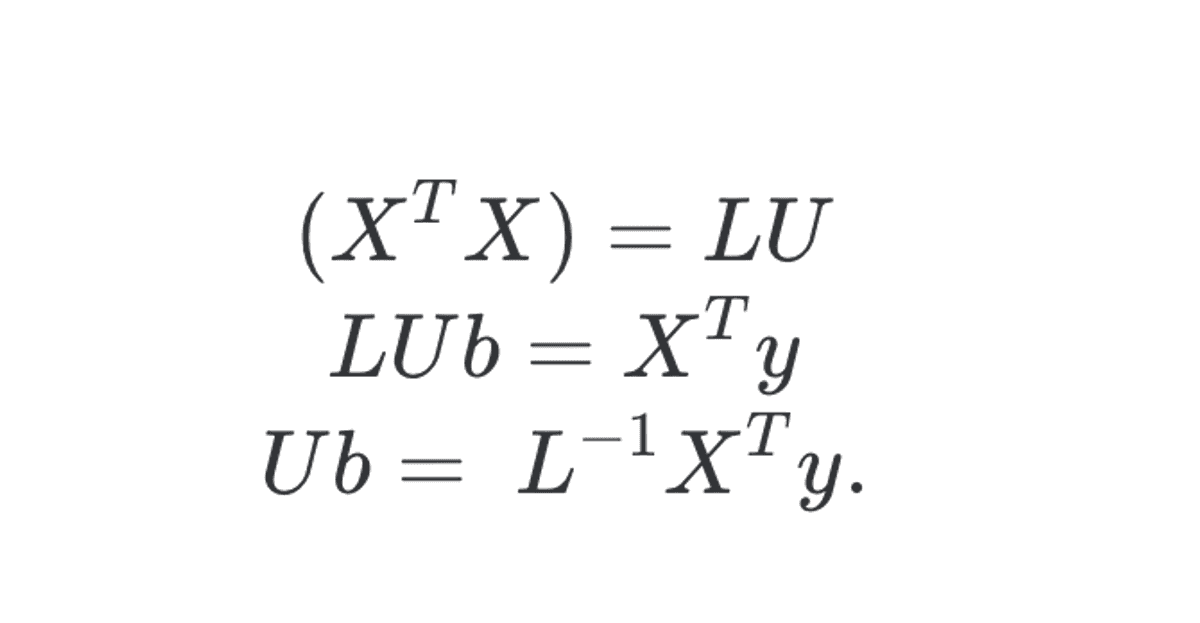Уменьшение размерности, этот термин оставляет очень мало места для воображения: методы, которые могут уменьшить размерность данных. Почему это полезно? Мы живем в трехмерном мире, и нам очень трудно рассуждать о многомерных отношениях. Соотношение между ростом и весом человека не так уж сложно представить, оно использует только 2 измерения. Включите возраст в эти отношения, и мы начнем бороться намного больше. Точно так же компьютеры могут бороться с многомерными данными: вычисления и модели становятся намного менее эффективными.
💡
пример из психологии
В области психологии уменьшение размерности часто используется при работе с многомерными данными. Обычно это делается для вывода или измерения скрытых/ненаблюдаемых признаков. В качестве примера: психологи давно пытались охарактеризовать, что такое эмоция. Одна из первых идей, и она закрепилась, заключается в том, что эмоция должна иметь как минимум два свойства: валентность и возбуждение. Валентность эмоции определяет, насколько она приятна или неприятна. Вы можете думать об этом в спектре от самого счастливого человека, который когда-либо мог быть, до самого печального человека, который когда-либо мог быть. Второе свойство, возбуждение, возможно, немного менее прямолинейно. Вы можете думать об этом как о том, насколько эмоция активирует вас. Если вы очень злы или счастливы, вы находитесь в состоянии сильного возбуждения, в то время как скука или чувство непринужденности будут состоянием низкого возбуждения. Следующим интуитивным шагом может быть представление о любой эмоции как о комбинации некоторого возбуждения и валентности на 2D-плоскости.
остановитесь на мгновение и подумайте о том, что вы чувствуете прямо сейчас.
Счастливый 1–2–3–4–5
Грустный 1–2–3–4–5
Скучный 1–2–3–4–5
Несчастный 1–2–3 –4–5
Количество эмоций, которые человек должен оценить, может варьироваться, но обычно составляет не менее 10 пунктов. Затем к собранным данным применяется модель матричной факторизации. Уменьшение размерности данных только до двух измерений будет отражать лежащие в основе уровни валентности и возбуждения.
По этой причине уменьшение размерности используется в машинном обучении, чтобы объединить набор переменных в меньший набор и использовать этот меньший набор в качестве признаков для модели. Это может быть полезно при работе с огромным количеством функций, поскольку уменьшает пространство, в котором модель должна находить решения. Тем не менее, есть недостатки в этом. Во-первых, вы выбрасываете информацию. Хотя в идеале отбрасывается только статистический шум, все эти методы делают некоторые предположения о структуре данных. Если эти предположения не содержат полезной информации, она может быть исключена из модели. Во-вторых, объединение нескольких функций в одну отрицательно сказывается на объяснимости модели. Гораздо сложнее интерпретировать коэффициент регрессии для признака, который является комбинацией 10 других признаков, чем сравнивать эти коэффициенты по отдельности. Другими словами, следует тщательно взвесить все преимущества и недостатки при применении уменьшения размерности. Тщательно изучите алгоритм или модель, которую вы хотите использовать, принимая во внимание конкретный вопрос или проблему, которую вы хотите решить.
Введя и изучив основные идеи, лежащие в основе уменьшения размерности, мы затем сравним и сопоставим два разных метода: анализ основных компонентов (PCA) и факторный анализ (FA). PCA — очень популярный метод, используемый как в машинном обучении, так и в статистике. FA — менее популярная техника, берущая свое начало в психологии/психометрии. Почему тогда ФА? Как мы увидим, эти методы очень похожи и служат для иллюстрации того, как небольшие изменения в модели могут сделать ее более или менее подходящей для конкретной задачи. Кроме того, автор этого блога — психометрист, который без колебаний выбирает своего любимого ребенка.
ППШ и ФА
Давайте сначала посмотрим, как определяется FA, чтобы мы могли сравнить его с PCA и понять различия. Факторный анализ как модель наших данных может быть определен как:
$$ X = \Xi \Lambda’ + \Delta, $$
где \(X\) - наши наблюдаемые данные, с \(n\) наблюдениями и \(p\) переменными. \( \Xi \) — матрица факторов с размерностями \( n \) и \( m \), где \( m \)≤\( p \). \( \Lambda’ \) — это \( m \)x\( p \) матрица факторных нагрузок или весов. Наконец, \( \Delta \) — это \( n \)×\( p \) матрица ошибок.
Теперь давайте освежим нашу память о PCA, который обычно определяется следующим образом:
$$ X = Z_s D^{1/2}U’. $$
\( X \) снова наши наблюдаемые данные, \( Z_s \) стандартизированные главные компоненты, \( D^{1/2} \) диагональная матрица стандартных отклонений главных компонентов, и \( U' \ )матрица собственных векторов. Здесь мы делаем сингулярное разложение матрицы наблюдаемых данных.
Если мы применим эти методы к ковариационной матрице, разница станет более ясной. Назовем эту ковариационную матрицу,
$$ R = \frac{1}{(n-1)}X’X $$
который мы рассчитали, используя некоторые данные об эмоциях, упомянутые в предыдущем примере [1].
Если мы теперь подставим формулы для PCA и EFA вместо X, мы получим следующие результаты.
PCA FA $$ R = \frac{1}{(n-1)}(Z_sD^{1/2}U')'(Z_sD^{1/2}U') \\ = (UD^{1/ 2})(UD^{1/2})' \\ =FF' \\ \ приблизительно F_cF'_c $$ $$ R = \frac{1}{(n-1)}(\Xi\Lambda'_m + \Delta)' (\Xi\Lambda'_m + \Delta) \\ =\Lambda\Lambda' + \Psi \\ \приблизительно \Lambda_c\Lambda'_c + \Psi $$
Не обращая внимания на различия в обозначениях, \(F\) и \(\Lambda\) функционально одинаковы — есть некоторое сходство. Нижний индекс \(c\) служит для обозначения того, что мы восстанавливаем ковариационную матрицу, используя приближение более низкого ранга, используя только первые \(c\) компоненты или факторы для восстановления ковариационной матрицы. Для модели FA добавленный параметр \( \Psi \) служит для улучшения оценок дисперсии конкретных элементов по сравнению с тем, что возможно в PCA. Это объясняет, почему говорят, что FA восстанавливает общую дисперсию (ковариацию), а PCA объясняет общую дисперсию.
Почему это так важно?
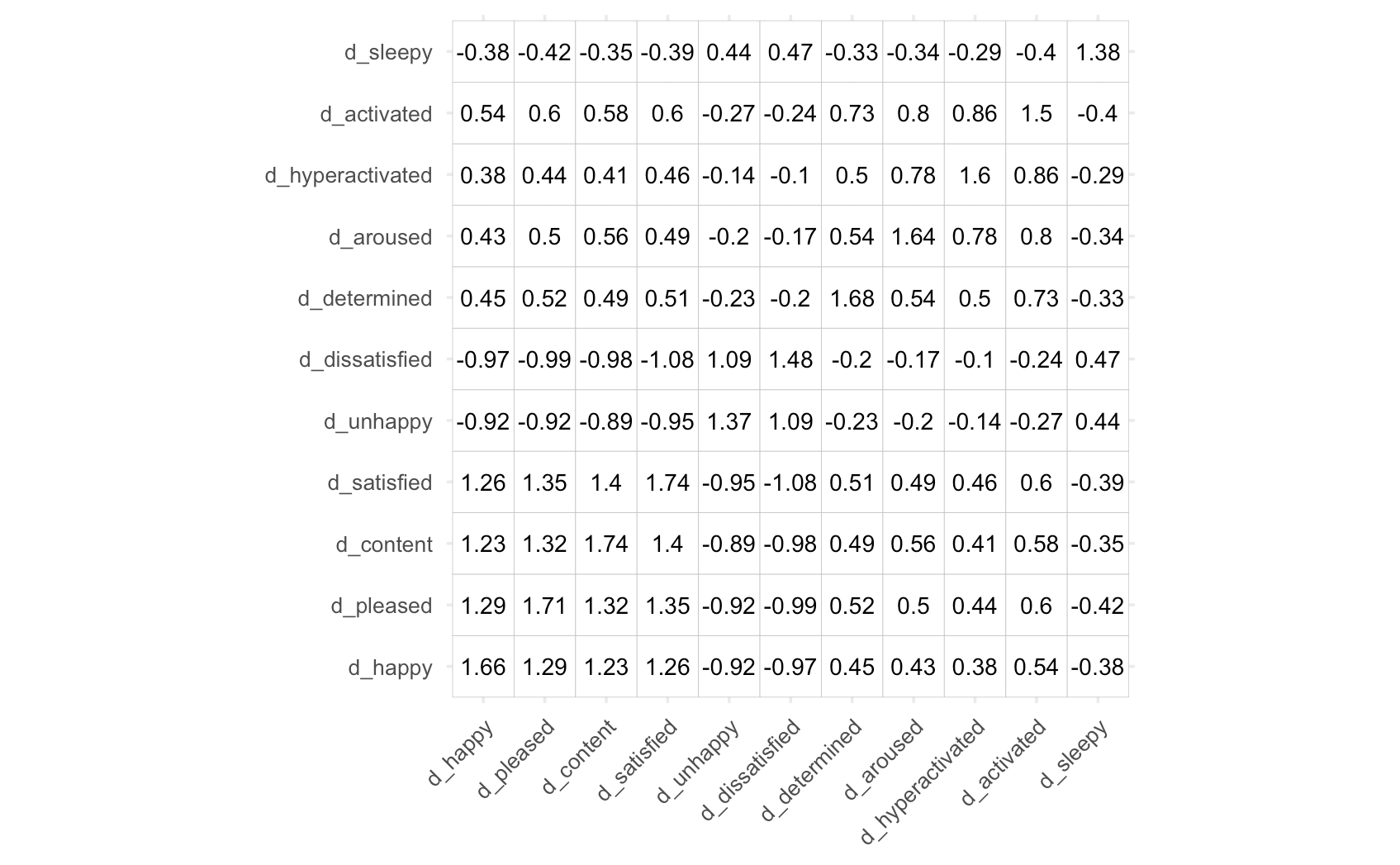
Используя теорему Эккарта-Юнга, мы можем доказать, что PCA оптимально восстанавливает всю ковариационную матрицу. В качестве примера давайте снова посмотрим на ковариационную матрицу элементов эмоций, которые использовались ранее. Я провел и PCA, и FA, указав решение с двумя компонентами/факторами. Затем мы можем восстановить матрицу более низкого ранга \(R_{rec} \) и вычесть эту новую матрицу из \(R\), чтобы получить матрицу остатков, \(R_{res} \) :
$$ R_{res} = R — R_{rec}. $$
Взяв норму Фробениуса \( \| R_{res} \|_F \), мы получим хорошее представление о том, насколько хорошо была восстановлена наблюдаемая ковариационная матрица:
СПС ФА $$ | R_{res} |_F^{PCA} = 2,3205 $$ $$ | R_{res} |_F^{FA} = 3,5561 $$
Действительно, мы видим, что PCA предлагает лучшее ранговое \( 2 \) приближение ковариационной матрицы. Так зачем нам вообще беспокоиться о методах, которые предлагают более низкую производительность?
Напомним, что для FA нас действительно интересуют только ковариации. Вместо того, чтобы воспроизводить всю ковариационную матрицу, мы больше заботимся о воспроизведении недиагональных элементов ковариационной матрицы. Для этой реконструкции PCA не обязательно является самой оптимальной процедурой. Если мы установим все диагональные элементы \( R_{res} \) равными нулю и возьмем норму Фробениуса полученной матрицы, мы получим оценку ошибки воспроизведения для недиагональных элементов. В то время как PCA может оптимально восстановить общую ковариационную матрицу, FA лучше оценивает недиагональные элементы ковариационной матрицы.
СПС ФА $$ | R_{off} |_F^{PCA} = 6,5712 $$ $$ | R_{off} |_F^{FA} = 5,9352 $$
Конечно, все статистические процедуры или модели делают некоторые предположения. Давайте обсудим, что следует иметь в виду при использовании PCA или факторного анализа.
Предположения
Все наблюдения должны быть полными, а значительные выбросы могут привести к искажению результатов. Это связано с тем, что оба метода на каком-то уровне предполагают многомерную нормальность данных. Давайте рассмотрим некоторые из наиболее существенных предположений.
Оба метода также предполагают, что переменные коррелированы, по крайней мере, в некоторой степени. Если бы все переменные были независимы друг от друга, мы бы не достигли идентифицируемых решений ни для PCA, ни для FA. Поскольку корреляция является линейной мерой связи, если переменные связаны только нелинейным образом, выходные данные обеих моделей будут смещены. Конечно, обе модели достаточно устойчивы к небольшим отклонениям, особенно когда переменные все еще монотонно связаны. Решения для борьбы с нелинейностью существуют как для PCA, так и для FA, но это выходит за рамки этого блога.
Наконец, решающее различие между PCA и FA заключается в том, что, поскольку PCA пытается смоделировать дисперсию данных, он очень чувствителен к различиям в этой дисперсии. Более конкретно, если одна переменная имеет дисперсию 1000, а другие переменные имеют дисперсию только 10, большая часть дисперсии приходится на первую переменную. В результате в главных компонентах будет доминировать первая переменная. По этой причине всегда лучше работать со стандартизированными переменными. Хотя это не является строго необходимым при проведении факторного анализа, поскольку он не зависит от масштаба.
Когда и как использовать PCA или FA?
Допустим, вы хотите применить любой из методов для решения какой-либо проблемы, которая у вас возникла. Какой метод подходит?
СПС
PCA можно использовать как метод уменьшения размерности, предполагая, что предположения, обсужденные ранее, не нарушаются. Одним из важных соображений является количество основных компонентов, которые необходимо поддерживать. Как правило, следует сохранять только компоненты с собственным значением больше единицы. Это связано с тем, что компоненты с меньшими собственными значениями не объясняют дополнительную дисперсию по сравнению с тем, что можно было бы объяснить, используя только одну из исходных функций. Это правило, как правило, дает очень хорошее представление о том, сколько компонентов нужно использовать. При необходимости существуют дополнительные численные методы, такие как процедура Хорна, которые учитывают выборочную дисперсию собственных значений.
После подбора PCA компоненты можно использовать в качестве входных данных для другой модели. Это может быть любая модель: регрессия, классификация или даже другой алгоритм обучения без учителя, такой как кластерный анализ.
FA
Факторный анализ был разработан для анализа данных анкет и оценки скрытых переменных, обусловливающих их. Обычно это делалось, чтобы получить более теоретическое понимание изучаемых концепций. Например, психологи определили 5 аспектов личности, которые постоянно встречаются у людей всех возрастов и профессий. Эти параметры были впервые определены с помощью факторного анализа. По этим причинам, возможно, наиболее простым применением факторного анализа в бизнесе будет анализ данных анкеты, которые имеют некоторую скрытую структуру, например удовлетворенность клиентов или сотрудников. С помощью FA вопросы, не дающие много информации, могут быть идентифицированы и изменены или полностью исключены.
Чтобы определить, сколько факторов необходимо извлечь, можно применить те же методы, что и в PCA. Однако, в отличие от PCA, факторное решение меняется в зависимости от того, сколько факторов было рассчитано моделью. Более конкретно, при расчете трехфакторного решения первые два фактора этого решения не идентичны двум факторам двухфакторного решения. Таким образом, после того, как было принято решение о том, сколько факторов использовать, лучше всего пересчитать модель и точно указать, сколько факторов следует сохранить.
Подводя итог, FA можно использовать для проверки того, можно ли найти действительную скрытую структуру и были ли вопросы интерпретированы одинаково в разных группах людей. Кроме того, факторные оценки можно рассчитать и использовать в качестве входных данных для модели машинного обучения, как и PCA. Но, поскольку FA является более сложной моделью (вспомните дополнительный параметр \( \Psi \) ), ее следует предпочесть PCA, когда переменные или признаки были измерены с любой степенью ошибки измерения. Прекрасная иллюстрация этого приведена в документации scikit-learn для факторного анализа.
Однако недостатком FA является то, что из-за этой дополнительной сложности решение не гарантируется. Это одновременно и благословение, и проклятие, потому что, когда решение не может быть найдено, это обычно означает, что модель очень плохо определена. В этот момент вы должны вернуться к чертежной доске и переосмыслить свою модель.
Заключение
Этот блог познакомил вас с PCA и факторным анализом, показав, насколько похожи модели, но также выделив важные различия. Факторный анализ и АКП имеют много общего, и оба являются отличными первыми попытками уменьшения размерности. Как и во всех методах, важно помнить, какие предположения сделаны, и выбирать правильный инструмент для работы.
Следите за новостями для нашего следующего блога в саге о статистике, интервал между этим блогом и следующим не должен быть слишком большим!
Благодарности
Спасибо Мишель Йик за то, что она позволила нам использовать данные исследования валентности/возбуждения в качестве примера!
Рекомендации
- Йик, М., Муес, К., Сзе, И.Н.Л., Куппенс, П., Тюрлинкс, Ф., Де Рувер, К., Квок, Ф.Х.К., Шварц, С.Х., … Рассел, Дж.А. (в печати). О взаимосвязи между валентностью и возбуждением в образцах по всему миру. Эмоция.
Вам также может понравиться
Тенденции в статистической визуализации — Lode Nachtergaele
«Инженеры по машинному обучению находятся на стыке программирования (информатики), математики/статистики/машинного обучения и предметных знаний/коммуникаций. Хотя в первых двух областях достигнут значительный прогресс, их достижения сдерживаются способностью передавать свои результаты бизнес…"
Статистическая сага 1: матричная факторизация — Чиэль Муес
«Это сообщение в блоге познакомит вас с идеей матричной факторизации, чрезвычайно полезной техники в статистике и машинном обучении. Матричная факторизацияМатричная факторизация — это метод разложения или факторизации матрицы в произведение более фундаментальных матриц. Если T…"