Использование категориальных и числовых функций с помощью BERT для улучшения модели

Эффективное письмо всегда было ключом к обеспечению эффективной передачи идей, критического мышления и убеждения. Писательство как навык необходим для успеха в современном мире. Однако, в то время как глобальный уровень грамотности медленно растет, рост неодинаков среди стран и социально-демографических групп. Например, многочисленные исследования показали, что в США существуют примеры образовательного неравенства. Это явление может в конечном итоге привести к закручиванию порочного круга расширения коэффициента Джини.
Одним из решений проблемы было бы предоставление учащимся возможности оценить собственную эффективность письма. Разработав автоматизированное руководство, учащиеся могут оценить свою собственную письменную эффективность, что позволит им учиться быстрее, используя меньше ресурсов. Это решение может быть в форме веб-приложения, в котором учащиеся загружают свои аргументированные эссе, и результат будет предоставлен для оценки эффективности эссе.
Целью этого конкурса является классификация аргументационных элементов в студенческих письменных работах как «эффективных», «адекватных» или «неэффективных».
Набор данных
Набор данных был предоставлен Kaggle через Университет штата Джорджия. В этой статье не будет распространения данных. Данные можно найти на kaggle.
Исследование данных
На первый взгляд предоставленный набор данных содержит только один столбец текстового корпуса. Однако мы можем спроектировать несколько функций с помощью контекстных знаний, которые сделают нашу модель более эффективной.
Цитирование
Каждый студент колледжа знает, насколько важно цитирование для повышения эффективности вашего эссе. Поэтому мы создаем функцию, которая помечает True/False, если в теле текста обнаружен какой-либо «источник».

Очевидно, что в эффективных эссе присутствует «источник».
Орфографические ошибки
Использование библиотеки Python tqdm для выявления наиболее распространенных орфографических ошибок. Вместо того, чтобы сделать его двоичным (да/нет орфографической ошибки), я сделал его числовым с количеством орфографических ошибок.

Хотя средний балл примерно одинаков для всех целевых функций, очевидно, что существует более широкий разброс для неэффективного эссе.
Количество слов
Эффективные эссе имеют относительно высокое среднее количество слов по сравнению с другими классами.

Полярность и субъективность
Полярность и субъективность в значительной степени получены из пакета Python textblob, который предоставляет простой API НЛП. Полярность корпуса текстов оценивается от -1 до 1, где -1 представляет отрицательное настроение, а +1 представляет положительное настроение.

Субъективность корпуса текстов оценивается от 0 до 1, где 0 представляет объективность, а 1 представляет субъективность. Основываясь на наборе данных, эффективные эссе обычно имеют немного более высокую медиану по сравнению с другими классами.

Моделирование данных

Выделенные оранжевым цветом обрабатываются через мультимодальный инструментарий, набор инструментов. Фрагмент кода предварительной обработки данных можно найти ниже. Я использовал горячее кодирование для категориальных признаков и преобразование Йео-Джонсона для числовых признаков, так как некоторые данные в числовых признаках могут быть очень маленькими или отрицательными.
Определение показателей
Так как это мульти-класс, вопрос классификации. Результаты оценивались с использованием точности, оценки F1 и потерь при обучении. В результате было достигнуто незначительное увеличение точности (от 0,63 до 0,68), в то время как было достигнуто более высокое усиление F1 (от 0,46 до 0,59).

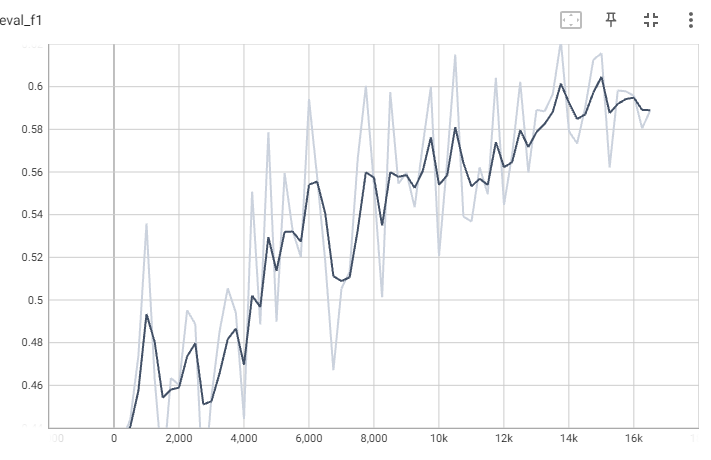
Функция потерь показывает, что существует сходимость, однако она достигает установившегося состояния после 10 000 шагов.

Заключение
В самом первом запуске этого конкурса я взял ванильную модель BERT и обучил ее на корпусе. Однако результаты не сошлись, и это привело к очень плохим результатам.

Во второй итерации я создал дополнительные функции, которые предоставили контекст для формулировки проблемы, очень похожие на критерии выставления оценок или контрольный список, которые учителя интуитивно используют при оценке эффективности эссе. Это привело к значительному улучшению производительности модели по всем показателям производительности. Результаты были бы более интерпретируемыми, если бы мы оценивали их с использованием логарифмических потерь мультикласса, поскольку он выводит вероятность каждого класса. Для получения дополнительной информации об оценке производительности обратитесь к моему репозиторию на github, куда я загрузил как EDA, так и блокнот для моделирования.
Еще одно ключевое улучшение, которое можно реализовать, — включить тип дискурса как часть анализа признаков. Без включения этой функции это было бы похоже на оценку начального абзаца так же, как и встречное опровержение.
Источники
[1] Датасет: https://www.kaggle.com/competitions/feedback-prize-efficientness.
[2] Моделирование: https://github.com/georgian-io/Multimodal-Toolkit