Маркетинговые бюджеты в большинстве компаний составляют значительную часть их расходов. Поэтому очень важно донести правильное сообщение до нужных людей. Это позволяет с одной стороны сократить расходы, а с другой — увеличить доходы.
Мы постараемся понять, может ли большой объем данных о поведении наших клиентов помочь нам выбрать правильные акции. Для этого мы будем использовать модели машинного обучения. Мы будем использовать данные, предоставленные Starbucks.
О данных.
Набор данных содержит смоделированные данные, которые имитируют поведение клиентов в мобильном приложении Starbucks Rewards. Starbucks отправляет своим пользователям предложение каждые несколько дней. Это либо информационное предложение со скидкой, либо тип «Купи один и получи один бесплатно» (BOGO). Данные не показывают, какие товары были куплены, только информацию о стоимости каждого заказа.
У нас есть 3 набора данных:
1 .portfolio — содержит идентификаторы предложений и метаданные о каждом предложении
2 .profile — демографические данные для каждого клиента
3. расшифровка — записи о транзакциях, полученных предложениях, просмотренных предложениях и выполненных предложениях
Давайте поближе познакомимся с каждым из них.
Дата портфолио

В данной коллекции всего 10 различных акционных предложений. Давайте проверим количество предложений каждого типа, какие вознаграждения дает каждое предложение и сколько вам нужно потратить, чтобы воспользоваться этим предложением.


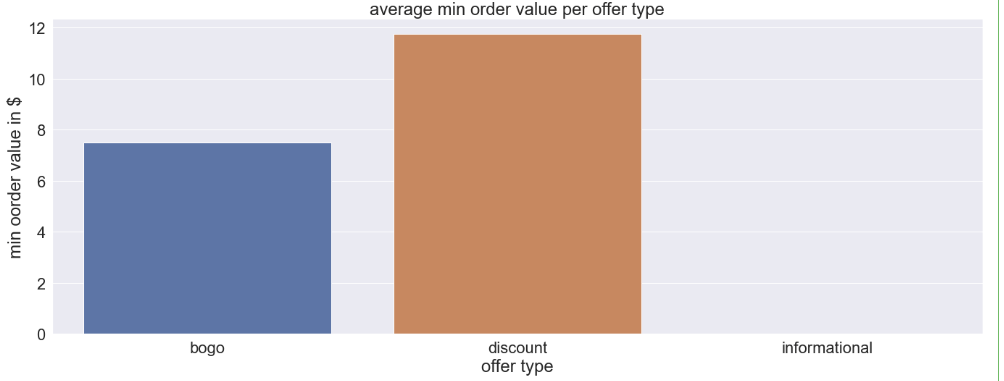
Как мы видим, тип bogo выглядит как лучшее предложение, потому что в среднем вы можете получить лучшее вознаграждение, и вам нужно потратить меньше денег, чтобы использовать предложение. Информационное предложение касается информации, и покупатель не получает никакой скидки.
Набор данных профиля
Этот набор данных содержит данные о наших клиентах. После некоторой очистки данных мы можем проанализировать особенности наших клиентов.



Основываясь на нашем анализе, мы видим, что в нашей клиентской группе немного больше мужчин (более 8000), чем женщин (около 6000). Самая большая группа доходов состоит из клиентов с распределением от 40 𝑘 до 70 000. Самая многочисленная возрастная группа – от 50 до 70 лет.
Набор данных расшифровки
Последний, но не менее важный набор данных для анализа — это стенограмма.

После некоторой очистки мы проанализируем его.
Во-первых, давайте посмотрим, как представлено распределение типов событий в наборе данных.

Как видите, почти 140 000 сделок и менее 40 000 офферов, что вызывает вопросы о том, есть ли группы пользователей, которые заключают сделки независимо от того, получают они акции или нет.
Теперь мы посмотрим, сколько составляет распределение расходов на транзакцию и сколько вознаграждение в полученных акциях.


Как видите, более 50 000 транзакций были совершены менее чем за 5 долларов США, необходимых для получения поощрения, остальные транзакции довольно равномерно распределялись между 5 и 30 долларов США.
Наибольшее вознаграждение получают суммы в 3 и 5 долларов.
Предварительная обработка данных
После очистки и анализа предоставленных наборов данных пришло время объединить их в один набор и добавить некоторые дополнительные функции, например, использовалась ли транзакция по акции и видел ли ее пользователь, воспользовавшийся акцией, или использовал ее, потому что она была просто доступна.
Все необходимые расчеты доступны в предоставленной тетради. После нескольких операций с базой данных мы определили, что транзакция, в которой использовалось предложение, составляла чуть более 30 000 из более чем 150 000 транзакций. Как легко сосчитать, только в 1 из 5 транзакций клиенты Starbucks использовали купон.
С другой стороны, количество использованных ранее предложений составило более 23,5 тыс. из 35 тыс. использованных предложений. То есть около 1/3 предложений было использовано несмотря на то, что заказчик ранее этого не видел.
Наконец, у нас есть один кадр данных со всеми данными, которые нам нужны для наших моделей.
Моделирование данных
Первая проблема, которую мы хотим решить, состоит в том, чтобы увидеть, можем ли мы, имея данные о клиентах и типе предложения, решить, воспользуется ли им данный клиент, увидев предложение. Если модель покажет удовлетворительные результаты, мы сможем перестать отправлять предложения людям, которые в них не заинтересованы.
Для такого типа задач лучше всего подходит модель логистической регрессии.
Для начала выберем функции, которые покажутся здесь полезными. Нашей задачей будет спрогнозировать, воспользуется ли им клиент, увидев акцию. Таким образом, функция, которую мы хотим предсказать, называется «просмотрено_соответствует», а информация о типе предложения и нашем покупателе будет использоваться для соответствия нашей модели.

После подготовки наших данных мы можем разделить данные обучения и тестирования, затем подобрать нашу модель и оценить ее с помощью показателей точности.
column=’viewed_complated’ X,y=df.drop(columns=[column]),df[column] x_train, x_test, y_train, y_test = train_test_split(X,y, test_size=0.30, random_state=42) logisticRegr = LogisticRegression() logisticRegr.fit(x_train, y_train) predictions = logisticRegr.predict(x_test) score = logisticRegr.score(x_test, y_test)
Точность этой модели составляет 80%, что очень приятно.
Последние мысли
Как оказалось, предоставленные данные, а также небольшая инженерия признаков позволяют удовлетворительно определить, стоит ли отправлять то или иное предложение конкретному клиенту. Демографические данные наряду с датой использования приложения также сами по себе имеют большую информативную ценность.
Все подробные расчеты рассматриваемой коллекции можно найти в этой тетради.