Как выйти из тупика разработки программного обеспечения

Фундаментальная проблема, которую необходимо решить при создании программного обеспечения, заключается в том, что оно по своей сути слишком сложно, чтобы уместиться в наших головах. Наш мозг может сосредоточиться только на очень большом количестве деталей в любой момент времени — и именно нам в конечном итоге приходится создавать программное обеспечение. Чтобы выйти из тупика, нам нужно преодолеть сложность.
Наш человеческий мозг эволюционировал не для того, чтобы писать компьютерные программы. Они гораздо лучше подходят для других видов деятельности. Наши в остальном безупречные интеллектуальные возможности не были оптимизированы для существенной сложности разработки программных систем, и, несмотря на некоторые оптимистичные заявления об искусственном интеллекте,компьютеры не особенно хорошо подходят для написания программного обеспечения. для них самих.
«Многие классические проблемы разработки программных продуктов проистекают из этой существенной сложности и ее нелинейного увеличения с размером […] Из сложности возникает сложность перечисления, а тем более понимания всех возможных состояний программы»
— Д-рФредерик П. Брукс-младший, N Серебряная пуля
Перспективным подходом к решению этой головоломки является оптимизация разделения труда между людьми и компьютерами. Позвольте людям делать то, что могут делать только они, автоматизируя действия, которые лучше выполняются компьютерами. Но как мы это делаем?
Вопрос:Как вы едите слона?
Ответ:по кусочку за раз.
Сначала мы должны разбить сложность, присущую программным системам, на маленькие кусочки, которые наш человеческий мозг сможет легче усвоить, при этом не создавая дополнительных сложностей.
Оптимизация фокуса
Поведенческие и когнитивные исследования предоставляют убедительные доказательства того, что мы способны лучше всего сосредоточиться на наборе вещей, которые находятся непосредственно перед нами. Многие из когнитивных функций нашего мозга, по-видимому, эволюционировали, чтобы игнорировать вещи, которые не находятся перед нами, чтобы максимально сосредоточиться на том, что в данный момент было наиболее важным для нашего выживания.
На самом деле, если нам приходится гоняться за частями головоломки, которые не находятся прямо перед нами, например, гоняться за логикой и определениями данных в нескольких классах Java в нескольких пакетах, мы быстро теряем фокус, и количество ошибок возрастает. в то время как наше понимание и производительность снижаются.
Мы можем начать с поиска компонентных и коммуникационных моделей, а также инструментов разработки, которые помогут нам изолировать и сосредоточиться на чем-то одном за раз. Это может значительно повысить наше понимание и продуктивность, одновременно снизив скорость, с которой мы делаем ошибки — а мы все, независимо от того, насколько совершенны, делаем ошибки.
Ограничения многоуровневой архитектуры
Большинство из нас знакомы с многоуровневым архитектурным шаблоном. Вероятно, это шаблон, наиболее часто используемый сегодня при создании приложений. Многие приложения, которые называются монолитами, хотя, возможно, развернуты в больших монолитных исполняемых файлах, на самом деле являются многоуровневыми, как и большинство популярных сегодня фреймворков.
Каждый уровень шаблона многоуровневой архитектуры имеет определенную роль и ответственность в приложении. Например, уровень представления будет отвечать за обработку всего пользовательского интерфейса и логики взаимодействия с браузером, тогда как бизнес-уровень будет отвечать за выполнение определенных бизнес-правил, связанных с запросом. Каждый уровень в архитектуре формирует абстракцию работы, которую необходимо выполнить для удовлетворения конкретного бизнес-запроса. —Шаблоны архитектуры программного обеспечения, Марк Ричардс, O’Reilly.
Многоуровневый шаблон стремится разбить вещи на понятные и управляемые части. Он популярен, потому что действительно помогает в этом.
К сожалению, компромиссы многоуровневого шаблона становятся менее привлекательными, когда мы пытаемся внедрить современные методы гибкой разработки. Несмотря на высокие оценки по простоте разработки и возможности тестирования, у него низкие оценки по общей гибкости, простоте развертывания. , производительность и масштабируемость.
Многоуровневый шаблон реализует техническое разделение — уровни разбиты по используемым технологиям и техническим навыкам, необходимым для их реализации. Эта стратегия разделения предполагает, что технология является сложной частью создания программного обеспечения. Тем не менее, большинство приложений, как правило, больше связаны с функциональностью, чем с технологиями. Особенно сегодня, когда технологическая часть часто поставляется для нас в виде библиотек с открытым исходным кодом с четко определенными API.
Давайте посмотрим, как мы можем воспользоваться преимуществами многоуровневого шаблона, преодолевая присущие ему недостатки.
Вертикальный срез
Мы можем начать с просмотра нашего многоуровневого шаблона с точки зрения вертикальных срезов, где мы можем реализовать разделение доменаg, чтобы мы могли разбить вещи с точки зрения знаний о предметной области и контекстов, ограниченных предметной областью. Мы не будем игнорировать технологии, но будем использовать их для удовлетворения требований приложений, а не наоборот.

Вертикальный срез — это шаблон, который повторяется в большинстве функций приложения и проходит через слои, от внешних данных до постоянных данных.
- Внешние данные поступают из пользовательского интерфейса, электронного устройства или другого приложения.
- Эти данные проверяются, а затем при необходимости выполняются вычисления и преобразования.
- Результаты преобразований сохраняются и/или возвращаются в пользовательский интерфейс, устройство или внешнюю систему.
- Пользовательский интерфейс, электронное устройство или внешнее приложение могут извлекать данные из постоянного хранилища по мере необходимости.
Вертикальный срез представляет собой логическое,но не обязательно физическое разделение отдельного поведения приложения и связи между этими уровнями. Он обеспечивает разумную отправную точку для разложения функции приложения на исполняемые компоненты и средства связи, необходимые для их соединения.
Вертикальные срезы часто объединяются для реализации более крупных возможностей и функций приложения, в то время как каждый срез продолжает сохранять свою индивидуальную направленность и разделение задач.
Вертикальный срез — это полезная перспектива для реализации новых функций приложения, а также для изменения или перепроектирования существующих функций. Это также синергетично с современными методами разработки, такими как "разработка через тестирование", "проектирование с учетом предметной области" и "разработка с учетом поведения".
Ограниченный доменом контекст
Первая задача в сервис-дизайне — провести границы вокруг каждого отдельного сервисного компонента. Именно здесь очень полезно понимание концепции Domain-Driven Design» ограниченного контекста.
На простом английском языке слово контекст относится к правилам и условиям, в рамках которых что-то происходит или существует. Мы используем ограниченный контекст, чтобы согласовать функциональность отдельного сервиса с функциональными границами приложения, правилами и владением данными. Таким образом, служба может быть разработана, протестирована, развернута и изменена ее разработчиками с минимальным вмешательством других групп разработчиков. Мы используем его для достижения высокого уровня детализации и разделения задач, что сохраняет автономию службы и независимую возможность развертывания.
Итак, как мы используем эту магию? Как вы увидите, мы работаем, используя способность акторной модели соблюдать границы и правила реальных распределенных приложений — и превращая контекст в первоклассный исполняемый компонент в своем собственном верно.
С этой точки зрения ограниченный контекст не должен быть универсальным для нескольких функций приложения, а должен быть ограничен конкретной изолируемой функцией приложения и требуемым доступом к данным. Более крупный ограниченный контекст может использовать эти меньшие контексты в качестве строительных блоков для реализации более сложных наборов функций.
Модель актера
модель актора в информатике — это математическая модель параллельных вычислений, в которой актор рассматривается как универсальный примитив параллельного программирования. Актеры могут изменять свое собственное частное состояние, но могут влиять друг на друга только косвенно через обмен сообщениями (что устраняет необходимость в синхронизации на основе блокировки).
Модель акторов возникла в 1973 году. Она использовалась как основа для теоретического понимания вычислений и как теоретическая основа для практической реализации параллельных систем.
Службы модели субъектов не имеют состояния и являются реактивными, обрабатывая входные сообщения, отправляя выходные сообщения и публикуя события. Все сообщения и события могут быть пропущены через проверку предусловия и постусловия субъекта, гарантируя, что подтверждения требуемой целостности данных всегда выполняются.
Актеры близки к идеальной компонентной модели для сервисов, потому что:
- Экземпляры субъектов являются реактивными и выполняют правила, логику и преобразования данных только при реагировании на сообщение.
- Экземпляры субъектов абсолютно реентерабельны и не имеют состояния. Они реагируют на одно сообщение за раз и не запоминают предыдущие обработанные сообщения. Все данные, необходимые для реагирования на сообщение, должны находиться в самом сообщении или в постоянном хранилище данных. Это означает, что любой экземпляр субъекта определенного типа может мгновенно заменить любой другой экземпляр того же типа, что позволяет реализовать плавный переход на другой ресурс, масштабирование и балансировку нагрузки.
- Экземпляры актора передают сообщения другим экземплярам актора, когда им нужно что-то сделать.
- Экземпляры субъектов публикуют события, когда им нужно сообщить о чем-то заинтересованным подписчикам.
- Экземпляр субъекта, ограниченный одним контекстом, может передавать сообщения или публиковать события для экземпляров субъекта, ограниченного другим контекстом, что позволяет ему использовать службы, разработанные, развернутые и поддерживаемые другие команды.
Обмен сообщениями
Такие шаблоны, как акторная модель, взаимодействуют посредством передачи сообщений. Запрашивающая сторона отправляет сообщение в службу или публикует событие и полагается на принимающую службу и ее поддерживающую инфраструктуру, чтобы затем выбрать и выполнить соответствующую логику.
Можно реализовать как асинхронный обмен сообщениями события, так и синхронный обмен сообщениями запрос-ответ, что дает разработчикам приложений возможность оптимизировать обмен данными для конкретных случаев использования и целей производительности — и все это в рамках общей унифицирующей структуры.
Веб-сокеты – это протокол на основе TCP, который обеспечивает полнодуплексные соединения между отправителями и получателями и может сделать обмен сообщениями запрос-ответ фактически асинхронным.
Есть преимущества в применении архитектурного стиля REST как к обмену сообщениями типа запрос-ответ, так и к обмену сообщениями о событиях. REST API ориентирован на передачу состояния, а не на отдельные функции приложения. Все правильные вызовы REST следуют одному и тому же набору шаблонов для получения состояния ресурса и управления им.
Все сообщения RESTful должны указывать целевой адрес. Запрос REST имеет адрес сервера и порт в качестве цели, а событие ECST нацелено на тему очереди. В остальном запросы и события идентичны. Без действительной цели сообщение RESTful — это просто мертвая буква.
Запрос просит что-то сделать, а событие сообщает, что что-то произошло. Получатель решает, что делать, основываясь на HTTP-методе сообщения и его полезной нагрузке.
В дополнение к цели сообщения RESTful имеют URI, который идентифицирует ресурс и версию реализации, состояние которой должно быть передано или изменено. К сожалению, URI также иногда используется для передачи функционального глагола, например «getUser». Это законное соглашение SOA, но оно не RESTful, где метод HTTP всегда передает намерение, как описано ниже:
- GETпредставление состояния указанного экземпляра или экземпляров ресурса.
- POST представление, чтобы создать новый экземпляр ресурса.
- PUT,или заменить состояние указанного экземпляра ресурса.
- ИСПРАВИТЬ или изменить состояние указанного экземпляра ресурса.
- УДАЛИТЬ указанный экземпляр ресурса.
Сообщение GET может также содержать строку запроса HTTP, которая может повлиять на выбор экземпляра или экземпляров типа ресурса, представление которого должно быть передано.
POST, PUT и PATCH передают представление ресурса в теле запроса.
POST требует уникальный идентификатор ресурса или должен его создать. Если создается новый идентификатор ресурса, принято возвращать URL-адрес нового ресурса в заголовке HTTP-ответа «Местоположение».
PUT, PATCH и DELETE всегда требуют уникального идентификатора ресурса.
Ответственность за реализацию ресурса заключается в том, чтобы знать, как обрабатывать запрос — инкапсулировать дискретное поведение отдельного ресурса в одном месте — и минимизировать количество отдельных вызовов API, которые разработчик должен изучить и понять.
Передача сообщений реализует слабую связь, но также может реализовывать динамическую связь. Динамическая связь с использованием оркестраторов сообщений обеспечивает очень мощный механизм для реализации балансировки нагрузки, аварийного переключения и динамического масштабирования. Оркестраторы также могут быть важным механизмом реализации самоорганизующихся систем.
Оркестраторы сообщений
Оркестраторы — это проводники, которые соединяют отдельных субъектов, организуя обмен сообщениями между ними и действуя как автоматические выключатели для смягчения каскадных ошибок. Оркестраторы управляют отработкой отказа, масштабированием и возможностями самоорганизации модели актора.
Когда оркестратор запускается, он строит карту всех сервисных ресурсов, расположенных в его собственном пути к классу (используя аннотации сервлетов), и регистрирует свое присутствие во всех других доступных оркестраторах в сети, обмениваясь с ними картами. Оркестраторы объединены в сеть и обмениваются информацией о состоянии друг с другом. Оркестратор принимает сообщения, адресованные конкретной версии службы, и направляет их ближайшему экземпляру этой версии службы.
Когда службы размещаются на сервере Jakarta EE, таком как Jetty, оркестратор может быть реализован как фильтр предварительного сопоставления запросов. Когда запрос поступает на сервер, на котором нет экземпляра нужной службы и версии, оркестратор перенаправляет запрос на сервер, на котором они есть.
ПРИМЕЧАНИЕ. Службы также можно развертывать как контейнерные микрослужбы (см. Проектирование микрослужб).
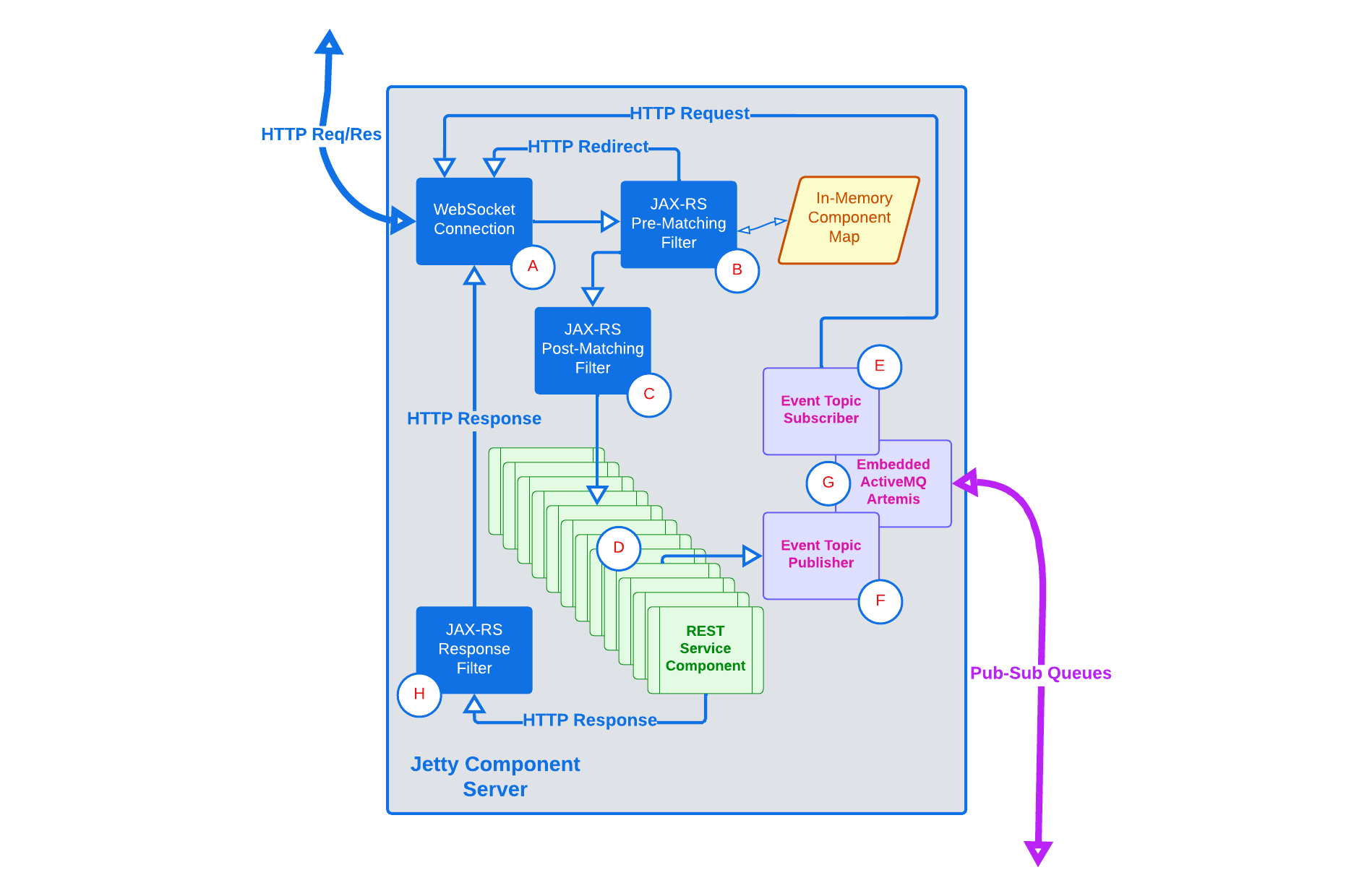
Сообщенияоркестраторыявляются ключевым компонентом, необходимым для развертывания компонентов приложения в сети без сложной нисходящей настройки. К карте всех серверов в сети и всех их установленных компонентов и версий можно получить доступ в любое время.
Если запрашивающая сторона имеет адрес любого сервера-компонента в сети, она может успешно отправить запрос или опубликовать событие любой цели в сети.
Самоорганизация
Сложность является основным ограничивающим фактором в успешной реализации больших прикладных систем. Это ахиллесова пята крупных сервисов и реализаций управления API.
По мере роста количества вещей (API, сервисов, ресурсов) и связей между ними сложность увеличивается нелинейным образом [ c = n(n-1)/2 ] . Иерархический контроль сверху вниз, реализованный в большинстве систем, плохо подходит для решения этой сложности. Требуется лучшее решение.
Многие рабочие машины такой сложности встречаются в природе. В поисках решения мы можем обратиться к самоорганизующимся системам, как природа справляется со сложностью. Самоорганизующиеся системы возникают в результате восходящих взаимодействий, в отличие от нисходящих иерархических систем, которые не являются самоорганизующимися.
Можно использовать оркестраторы сообщений для реализации динамической связи между федеративными службами (которые при запуске каталогизируются их домашним оркестратором). Таким образом, управление распределяется по целым системам, и все части вносят свой вклад в результирующую функциональность, в отличие от централизованных структур, которые часто зависят от одного координирующего субъекта.
Отдельной службе не нужно знать сетевые адреса любых других служб, с которыми она взаимодействует, за это отвечает сообщениеorchestrator, с которым она связана.
Эта децентрализованная структура, присущая самоорганизующимся системам, придает им устойчивость и надежность. Когда какой-либо элемент выходит из строя, его можно легко заменить аналогичным элементом. Успешная сервисная архитектура имитирует децентрализованную структуру органических живых систем, где сложные возможности могут возникать в результате взаимодействия относительно простых частей, в то же время сводя к минимуму сложности конфигурации и развертывания.
Тестирование
Тестирование программного обеспечения может быть трудным и трудоемким занятием даже при самых благоприятных обстоятельствах. Как протестировать сотни или даже тысячи исполняемых компонентов, которые могут взаимодействовать по сети? У модели акторов есть ответ — предварительные условия и постусловия, применяемые при отправке или получении сообщений.
Предварительные и последующие условия проверяют и фильтруют данные в сообщениях, которые получают и отправляют акторы. Они могут устанавливать предварительные условия для входящих сообщений и постусловия для исходящих сообщений.
При обнаружении недопустимого состояния они могут опубликовать событие ошибки, которое регистрируется распределенным регистратором, который, в свою очередь, вызывает обработчик ошибок, если он указан для типа ошибки. При вызове указанный обработчик ошибок может организовать необходимые действия по очистке или исправлению.
Предварительные и последующие условия являются декларативными. В конце концов, это утверждения. Их можно объявлять для элементов данных, структур данных и сообщений. Эти объявления можно использовать для создания исполняемого кода, а в системе с оркестрацией сообщений этот исполняемый код может автоматически вызываться оркестратором.
Когда сервисы размещаются на серверах Jakarta EE, предварительные условия могут быть реализованы как фильтры запросов с привязкой к имени, а постусловия могут быть реализованы как связанные с именем фильтры ответов, что является основной целью таких фильтров.
Этот подход гарантирует, что состояние сообщений и данных приложения соответствует заявленным правилам, и что участники всегда могут принимать чистые и достоверные входные данные, эффективно и непрерывно выполняя модульные тесты для всех компонентов, где бы они ни использовались.
Распределенные средства ведения журнала и обработчики ошибок гарантируют, что ошибки, возникающие в любом месте системы, могут быть зарегистрированы для регистрации, анализа и исправления.
Этот тип тестирования не является заменой тестирования поведенческих сценариев, проводимого такими вещами, как Огурец и корнишон. Он ориентирован только на обеспечение того, чтобы данные соответствовали объявленным ограничениям, а не на правильной реализации самих действий.
Ресурс RESTful
В архитектурном шаблоне REST выполняются запросы на передачу состояния ресурсамежду запросчиками и ответчиками. В этой модели все ресурсы реализованы как сервисы. Эти ресурсы реализуют логические уровни в вертикальном срезе. Некоторые из этих слоев могут быть:
- Постоянные данные, такие как экземпляры, находящиеся в виде строки или строк таблицы в базе данных SQL, документа в базе данных документов или записи файла с ключом или записей.
- Данные о состоянии электронного устройства или компьютерного процесса.
- Фасад, взаимодействующий с устаревшими или внешними API.
- Специально разработанное логическое представление, представляющее ограниченный контекст и использующее службы одного или нескольких из указанных выше типов ресурсов.
В качестве одного из архитектурных ограничений REST использует многоуровневую систему. Это означает, что инициатору запроса не нужно заботиться о том, где находится исполняемый файл версии ресурса. Ему не нужно знать, взаимодействует ли он напрямую с локальным ресурсом или с совокупностью ресурсов, разбросанных по сети. Он будет получать доступ ко всем из них точно таким же образом.
Это позволяет нам напрямую обращаться к строкам в таблице SQL, документам в базе данных документов, состоянию инструмента или процесса или сложному представлению нескольких типов ресурсов, созданному для реализации ограниченного контекста сложной бизнес-функции — все в так же.
Это дает серьезные преимущества в том, как мы можем синхронизировать постоянство связанных объектов данных в более широком контексте приложения и как мы можем реализовывать отдельные и многоуровневые компоненты графического интерфейса приложения.
Пользовательский интерфейс
Современный пользовательский веб-интерфейс состоит из таких элементов, как прокручиваемые таблицы, формы, изображения и кнопки, ссылки, полосы прокрутки и вкладки, которые помогают пользователю использовать и перемещаться по приложению, которое представляет пользовательский интерфейс. Современные фреймворки веб-интерфейса могут реализовывать модель программируемых компонентов с помощью JavaScript или TypeScript, HTML5 и CSS3.

Веб-компоненты представляют собой стандартную компонентную модель для Интернета, позволяющую инкапсулировать и взаимодействовать с отдельными элементами HTML. Веб-компоненты поддерживаются текущими версиями всех основных браузеров.
Google Lit — это простая библиотека с открытым исходным кодом для создания быстрых и легких веб-компонентов, совместимых с графическими веб-фреймворками, такими как Angular и React, или библиотеками, такими как jQuery, и может использоваться как с JavaScript, так и с TypeScript. .
С теговыми литералами шаблонов Lit браузер передает функции тега массив строк (статические части шаблона) и массив выражений (динамические части). Lit использует это для создания эффективного представления вашего шаблона, поэтому он может повторно отображать только те части шаблона, которые были изменены.
В этой модели каждый веб-компонент представляет собой микроинтерфейс и взаимодействует с сервером через контекстную службу. Эта служба реализует ограниченный контекст вертикального среза функциональности приложения в виде логического представления данных и выполняет как бизнес-логику, так и логику доступа к данным для веб-компонента. Служба контекста, в свою очередь, использует стандартные службы REST для доступа к постоянным данным. Контекстные службы возвращают данные и/или сообщения об ошибках через стандартный объект ответа HTTP.
Использование логически последовательной модели компонентов из пользовательского интерфейса через бизнес-логику приложения и вниз к постоянным данным может помочь справиться со сложностью, улучшая понимание и производительность разработчиков.
Фреймворки
Фреймворк по необходимости поставляется со всем необходимым для удовлетворения широкого круга проектов и вариантов использования. На практике разработка с использованием фреймворка будет сопровождаться функциями, функциями и кодом, которые вообще не будут использоваться в вашем проекте.
Большинство фреймворков построено на базовой концептуальной и архитектурной модели. Несмотря на постоянные усилия по их модернизации, большинство сегодняшних сервисных фреймворков реализуются с многоуровневой сервис-ориентированной архитектурой. Это может стать препятствием для внедрения систем с более современной компонентной архитектурой.
Облегченный фреймворк, который реализует минимальные дополнительные функции, может служить промежуточным звеном между стратегиями разработки без фреймворка и более старыми тяжеловесными многофункциональными фреймворками. Такая облегченная структура может быть реализована с помощью более новых библиотек Jakarta EE.
Выводы
Компонентные и коммуникационные модели, а также инструменты разработки, которые помогают нам изолировать и фокусироваться на чем-то одном, могут значительно повысить наше понимание и продуктивность, одновременно снизив скорость, с которой мы делаем ошибки. Это может помочь нам справиться с существенной сложностью, которая делает программные системы такими сложными в создании и рискованными в разработке.
Для реализации действительно распределенной функциональности приложения требуется доменно-разделенная архитектура с гибкими компонентами и коммуникационной моделью. Такая модель может распределять данные и функциональные возможности между несколькими серверами и устройствами в сети, обеспечивая при этом гибкость и избыточность, необходимые для устранения большинства единых точек отказа.
Для надежной работы в различных средах модель должна быть самоорганизующейся и самонастраивающейся как для больших, так и для малых установок. Для развертывания, настройки и эксплуатации требуется минимум технической поддержки. С современными технологиями это практически достижимая цель.
Спасибо!