В последние годы модели на основе глубокого обучения отлично справляются с такими задачами, как обнаружение объектов и распознавание изображений. В сложных наборах данных классификации изображений, таких как ImageNet, которые содержат 1000 различных классификаций объектов, некоторые из этих моделей способны работать на человеческом уровне. Эти модели, однако, основаны на парадигме контролируемого обучения, и доступность помеченных обучающих данных оказывает существенное влияние на то, насколько хорошо они функционируют. Кроме того, классы, которые могут обнаруживать модели, ограничены теми, на которых они обучались.
Из-за того, что изображений с тегами для всех классов во время обучения может не хватить, эти модели менее полезны в реальных условиях. Кроме того, мы хотим, чтобы наша модель могла распознавать изображения из классов, которым она не подвергалась во время обучения, потому что практически невозможно тренироваться на фотографиях всех потенциальных объектов. Проблема обучения на нескольких примерах называется обучение с помощью нескольких попыток.
Что такое обучение Few-Shot?
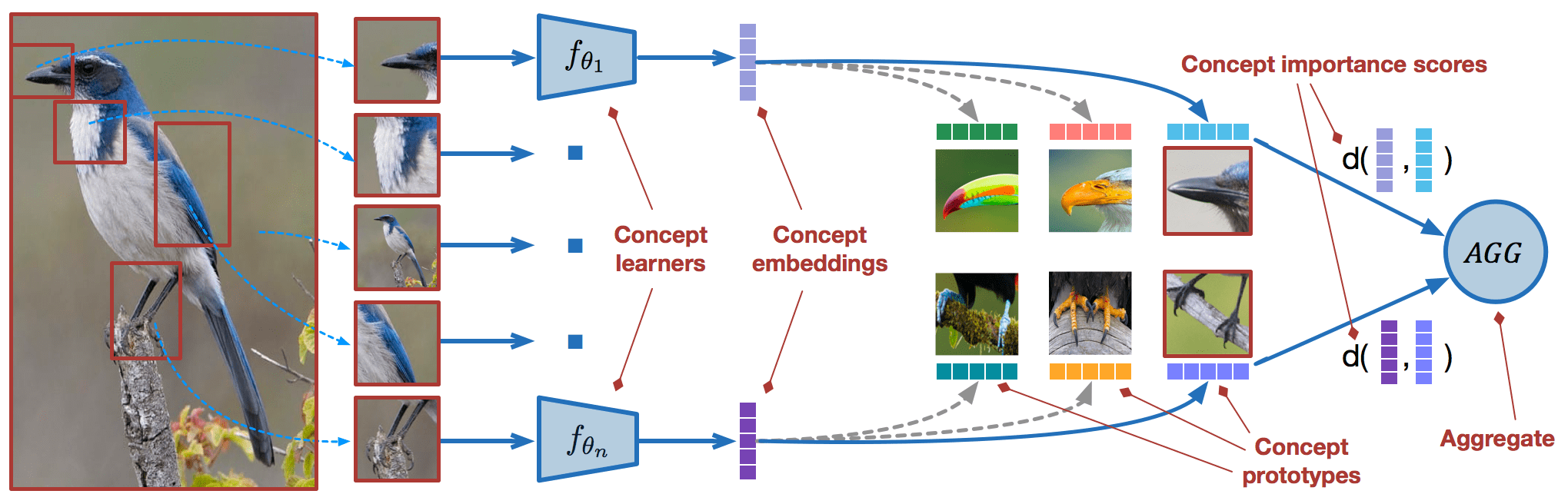
Несколько выстрелов – это часть машинного обучения. Он включает в себя категоризацию новых данных, когда имеется всего несколько обучающих выборок с контролируемыми данными. При небольшом количестве обучающих примеров модель компьютерного зрения может работать достаточно хорошо.
Рассмотрим следующий сценарий. Мы работаем в области медицины и у нас возникают проблемы с классификацией заболеваний костей по рентгеновским снимкам. Для включения некоторых необычных заболеваний в обучающую выборку может не хватить фотографий. Создание классификатора обучения с несколькими выстрелами — идеальное решение для подобного сценария.
Вариации обучения за несколько выстрелов
В целом исследователи выделяют четыре типа:
- Обучение N-Shot (NSL)
- Небольшое обучение (FSL)
- Одноразовое обучение (OSL)
- Меньше одного или Zero-Shot Learning (ZSL)
Когда мы говорим о FSL, мы обычно имеем в виду классификацию N-way-K-Shot. Nобозначает количество классов, а K — количество образцов из каждого класса для обучения.
Обучение N-Shot рассматривается как более широкое понятие, чем все остальные. Это означает, что Few-Shot, One-Shot и Zero-Shot Learning являются подполями NSL. Zero-Shot Learning направлен на классификацию невидимых классов без каких-либо обучающих примеров.
В One-Shot Learning у нас есть только один образец каждого класса. Few-Shot имеет от двух до пяти образцов на класс, что делает его просто более гибкой версией OSL.
Подходы к обучению с несколькими выстрелами
Как правило, при решении задач Few Shot Learning следует учитывать два подхода:
- Подход на уровне данных (DLA)
- Подход на уровне параметров (PLA)
Подход на уровне данных
Эта стратегия довольно проста. Он основан на идее, что вы должны просто добавить больше данных, если у вас уже недостаточно данных для создания твердотельной модели и предотвращения недообучения и переобучения. Из-за этого многие проблемы FSL решаются за счет использования большего количества данных из значительного базового набора данных. Отличительной чертой базового набора данных является то, что в нем отсутствуют классы, составляющие наш вспомогательный набор для задачи Few-Shot. Базовый набор данных может содержать изображения множества других птиц, если, например, мы хотим классифицировать определенный вид птиц.
Подход на уровне параметров
Образцы для обучения с использованием алгоритма Few-Shot Learning относительно легко поддаются переоснащению с точки зрения уровня параметров, поскольку они часто имеют большие многомерные пространства. Ограничение пространства параметров, использование регуляризации и использование соответствующих функций потерь помогут решить эту проблему. Небольшое количество обучающих выборок будет обобщено моделью.
С другой стороны, направляя модель в обширное пространство параметров, мы можем улучшить производительность. Из-за отсутствия обучающих данных обычный подход к оптимизации может не дать точных результатов.
По этой причине мы обучаем нашу модель находить наилучший путь через пространство параметров, чтобы получить наилучшие возможные результаты прогнозирования. Этот метод известен как метаобучение.
Алгоритмы классификации изображений с несколькими кадрами
Алгоритмы Meta-Learning, которые можно использовать для решения задач классификации изображений с помощью метода Few-Shot Learning.
- Независимое от модели метаобучение (MAML)
- Подходящие сети
- Прототипы сетей
- Сеть отношений
Независимое от модели метаобучение
Принцип метаобучения на основе градиента (GBML) лежит в основе MAML. В GBML участник метаобучения приобретает предшествующий опыт посредством обучения базовой модели и изучения общих характеристик всех представлений задач. Каждый раз, когда появляется новая задача для изучения, мета-обучаемый будет немного подстраиваться, используя свой существующий опыт и минимальное количество новых обучающих данных, предоставляемых новой задачей.
Однако мы не хотим инициализировать параметры случайным образом. Если мы пойдем по этому пути, после нескольких обновлений наш алгоритм не сойдется к хорошей производительности. MAML пытается решить эту проблему. Всего за несколько шагов градиента и без переобучения MAML предлагает надежную инициализацию обучающихся с метапараметрами для достижения оптимального быстрого обучения новой задаче.
Шаги:
- Мета-обучаемый создает свою копию © в начале каждого эпизода,
- C обучается на эпизоде (как мы уже обсуждали ранее, с помощью базовой модели),
- C делает прогнозы по набору запросов,
- Потери, вычисленные на основе этих прогнозов, используются для обновления C,
- Это продолжается до тех пор, пока вы не потренируетесь на всех эпизодах.

Самое большое преимущество этого метода заключается в том, что он задуман как независимый от выбора алгоритма мета-обучения. Таким образом, метод MAML широко используется со многими алгоритмами машинного обучения, требующими быстрой адаптации, особенно с глубокими нейронными сетями.
Соответствующие сети
Первым методом Metric-Learning, созданным для решения проблем FSL, были Matching Networks (MN).
При использовании подхода Matching Networks для решения задачи обучения в несколько шагов требуется большой базовый набор данных. Этот набор данных разбит на эпизоды, как уже упоминалось.
После этого для каждого эпизода Matching Networks применяют следующую процедуру:
- Каждое изображение из поддержки и набора запросов передается в CNN, которая выводит для них вложения,
- Каждое изображение запроса классифицируется с использованием softmax косинусного расстояния от его вложений до вложений набора поддержки,
- Кросс-энтропийная потеря в результирующей классификации передается обратно через CNN.
Matching Networks может научиться создавать встраивания изображений таким образом. MN может классифицировать фотографии с помощью этого метода без каких-либо специальных предварительных знаний о классах. Для всего используется простое сравнение нескольких экземпляров классов.
Поскольку классы варьируются от эпизода к эпизоду, Matching Networks вычисляет атрибуты изображения, которые важны для различения классов. Напротив, при использовании стандартной классификации алгоритм выбирает характеристики, уникальные для каждого класса.
Прототипы сетей
Подобными сетям сопоставления являются прототипные сети (PN). Тем не менее, есть небольшие вариации, которые служат для повышения производительности алгоритма. На самом деле ПП дает лучшие результаты, чем МН. Процедура PN по существу такая же, за исключением того, что сравниваются некоторые вложения изображения запроса из набора поддержки. Вместо этого прототипные сети предлагают другую стратегию.
Вы должны создать прототипы классов в PN. По сути, это вложения классов, которые были созданы путем усреднения вложений изображений в этом классе. Затем только эти прототипы классов используются для сравнения вложений изображений запроса. Важно отметить, что этот метод сравним с Matching Networks при использовании для задач One-Shot Learning.
Сеть отношений
Реляционная сеть была создана в результате всех исследований, проведенных для создания соответствующих и прототипных сетей (RN). RN был основан на идее PN, но включал значительные алгоритмические усовершенствования.
Метод изучил функцию расстояния, а не определил ее заранее. Это делается с помощью собственного модуля отношений RN. Общая структура выглядит следующим образом. Модуль отношения помещается поверх модуля встраивания, который является частью, которая вычисляет вложения и прототипы классов из входных изображений.
В модуль отношения подается конкатенация вложенного изображения запроса с каждым прототипом класса, и он выводит оценку отношения для каждой пары. Применяя Softmax к показателям отношений, мы получаем прогноз.

Обучение Zero Shot с клипом Open-AI
CLIP (Contrastive Language-Image Pre-Training) — это нейронная сеть, обученная на множестве пар (изображение, текст). На естественном языке ему можно дать указание предсказать наиболее релевантный фрагмент текста по изображению без прямой оптимизации для задачи, аналогично нулевым возможностям GPT-2 и 3.
CLIP соответствует производительности оригинального ResNet50 на ImageNet «zero-shot» без использования каких-либо исходных примеров с маркировкой 1,28M, преодолевая несколько основных проблем компьютерного зрения.
Установка библиотек
! pip install ftfy regex tqdm
! pip install git+https://github.com/openai/CLIP.git
import numpy as np
import torch
from pkg_resources import packaging
print("Torch version:", torch.__version__)
Загрузка модели
import clip
clip.available_models() # it will list the names of available CLIP models
model, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)
Предварительная обработка изображения
Настройка входных изображений и текстов
Мы собираемся передать модели 8 примеров изображений и их текстовые описания и сравнить сходство между соответствующими функциями.
Токенизатор нечувствителен к регистру, и мы можем свободно давать любые подходящие текстовые описания.
import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}
original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
plt.subplot(2, 4, len(images) + 1)
plt.imshow(image)
plt.title(f"{filename}\n{descriptions[name]}")
plt.xticks([])
plt.yticks([])
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
plt.tight_layout()
Это даст вам такой сюжет -

Особенности здания
Мы нормализуем изображения, токенизируем каждый ввод текста и запускаем прямой проход модели, чтобы получить функции изображения и текста.
image_input = torch.tensor(np.stack(images)).cuda()
text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda()
with torch.no_grad():
image_features = model.encode_image(image_input).float()
text_features = model.encode_text(text_tokens).float()
Вычисление сходства косинусов
Мы нормализуем функции и вычисляем скалярное произведение каждой пары.
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)

Классификация изображений Zero-Shot
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()

Рекомендации
- Изображение 1 — из исследовательской статьи КОНЦЕПЦИЯ УЧАЩИХСЯ ДЛЯ ОБУЧЕНИЯ ЗА НЕСКОЛЬКО ВЫПОЛНЕНИЙ
- Изображение 2 — из исследовательской статьи Независимое от модели метаобучение для быстрой адаптации глубоких сетей
- Изображение 3 — из исследовательской статьи Обучение сравнению: сеть отношений для обучения с небольшим количеством выстрелов
- Исследовательская работа — Обучение на нескольких примерах: краткое изложение подходов к обучению с использованием нескольких подходов
- Практическое одноразовое обучение с Python: научитесь внедрять быстрые и точные модели глубокого обучения с меньшим количеством обучающих примеров с помощью PyTorch
- https://github.com/openai/CLIP
- https://neptune.ai/blog/understanding-few-shot-learning-in-computer-vision
- https://deepai.org/publication/meta-learning-algorithms-for-few-shot-computer-vision#S2.SS3
- https://blog.floydhub.com/n-shot-learning/
- https://www.sicara.fr/blog-technique/2019-07-30-image-classification-few-shot-meta-learning