Авторы: Алекс Саблайроллес, Ашкан Юсефпур, Картик Прасад, Петр Ромов, Давиде Тестуджин, Игорь Шилов, Илья Миронов.
Введение
В предыдущем сообщении в блоге мы рассказали, как в Opacus выполняются векторизованные вычисления для повышения производительности и почему Opacus может вычислять градиенты для каждой выборки намного быстрее, чем микропакетная обработка. Мы также ввели векторизованные вычисления для nn.linear слоев. В этом сообщении блога мы подробнее объясним, как градиенты для выборки эффективны для других типов слоев: сверток, RNN, LSTM, нормализации, встраивания и внимания с несколькими головками.
Резюме
В предыдущем сообщении в блоге мы рассмотрели следующее:
- Одной из особенностей Opacus является «векторное вычисление», поскольку он может вычислять градиенты для каждой выборки намного быстрее, чем микропакетная обработка. Для этого мы выводим формулу градиента для каждой выборки и реализуем ее векторизованную версию.
- Формула градиента для выборки
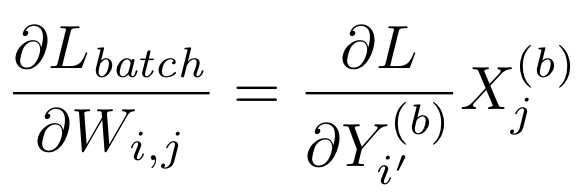
- Мы называем градиенты относительно активаций «градиентами шоссе», а градиенты относительно весов — «градиентами выхода».
- Градиенты шоссе сохраняют информацию для каждого образца, а градиенты на выходе — нет.
- einsum упрощает векторизованные вычисления.
Мы приглашаем вас ознакомиться с предыдущим постом в блоге для деталей; вкратце, Opacus вычисляет градиенты для каждой выборки с помощью хуков PyTorch — доступ к значениям активации с помощью прямых хуков и градиентов магистрали для расчета градиентов для каждой выборки с помощью обратных хуков. Некоторая линейная алгебра поверх этих захваченных значений дает нам конечный результат.
Основные понятия для других типов модулей (кроме nn.linear) остаются прежними; что меняется, так это линейная алгебра, которую мы делаем с einsum по активациям и градиентам шоссе. Это то, что мы исследуем в этом посте.
Распространение идеи на другие модули
Теперь, когда мы увидели, как эффективно вычислять градиенты для каждой выборки для линейных слоев (строительных блоков многослойных персептронов (MLP)), мы можем применить базовые методы и к другим слоям. Прежде всего, обратите внимание, что это должно быть возможно. Почему? Давайте объясним. Все, что делает линейный слой, — это матричное умножение (matmul) между входными данными и параметрами. Все остальные виды слоев, вероятно, тоже делают что-то подобное! Единственное отличие состоит в том, что они имеют дополнительные ограничения, такие как разделение веса в свертке или последовательное накопление при обратном проходе в LSTM. Вот как мы это делаем для сверток, LSTM, многоголового внимания, нормализации, GRU и слоев встраивания.
свертка
Чтобы напомнить, давайте посмотрим на прямой проход модуля свертки. Для простоты рассмотрим Conv2D с ядром 2x2, работающим на входе только с одним каналом (форма 1x3x3).
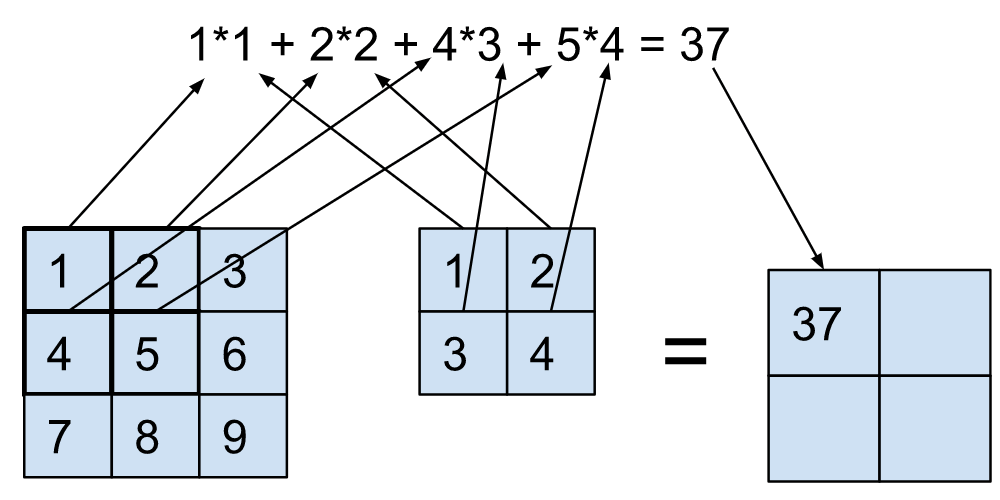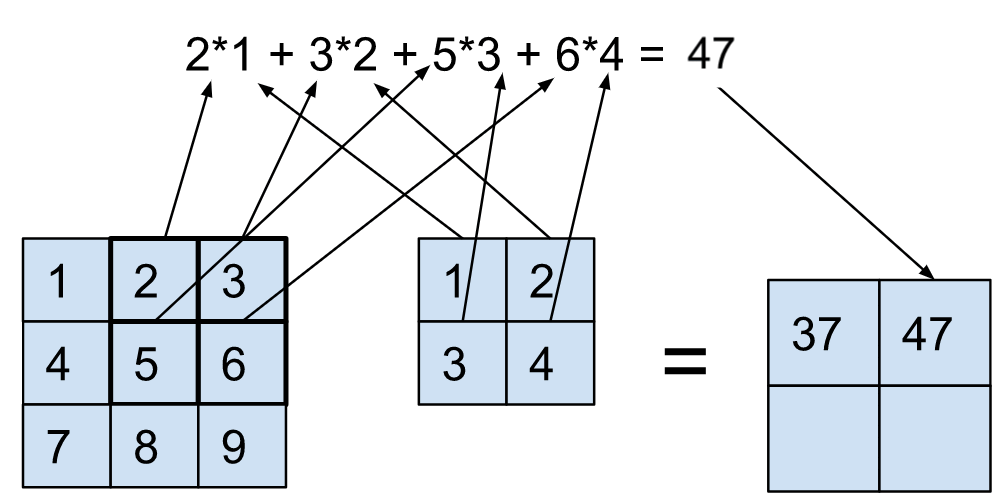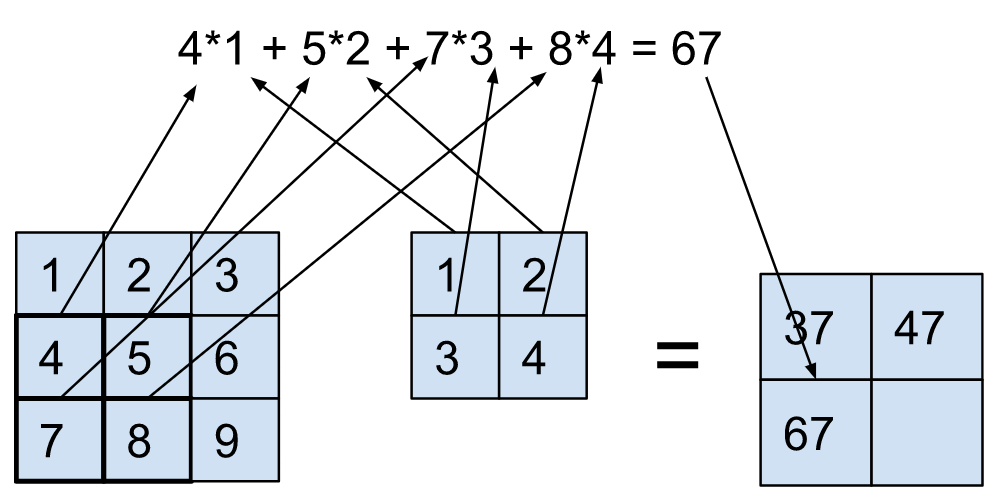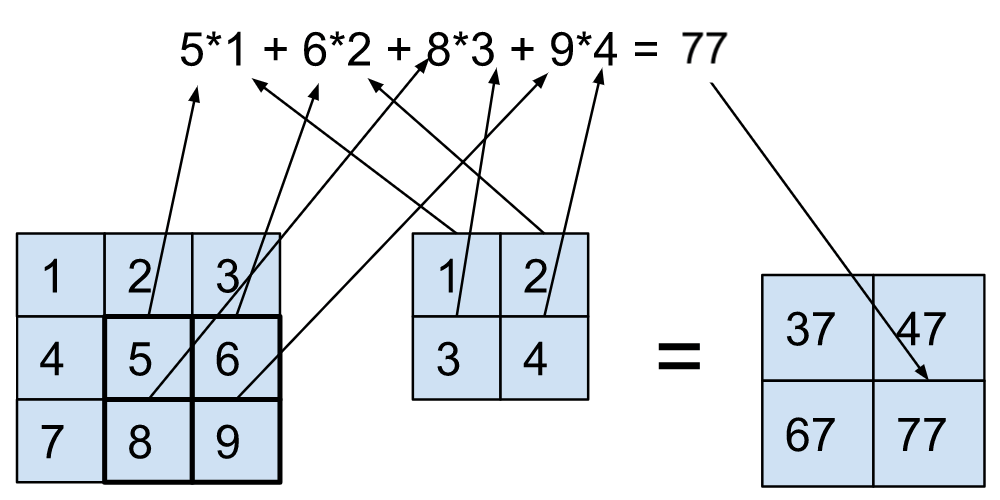
Очевидно, эта операция представляет собой нечто большее, чем простое умножение матриц, которое мы видим с модулем nn.linear. Однако, если бы мы развернули ввод (подробнее об этом здесь), мы получили бы те же результаты, выполнив простое умножение матриц (и некоторое изменение формы) следующим образом:

Теперь, когда мы переписали свертку, используя матричное умножение, мы можем реализовать эффективное матричное умножение, используя einsum, как мы делали раньше для линейных слоев. Opacus делает именно это: unfold, matmul, reshape. (код см. здесь)
Это единственный способ вычислить векторизованные градиенты для выборки для Conv слоев? Нет, это не так. Другой подход заключается в использовании того факта, что градиент свертки — это еще одна свертка. Используя этот подход, можно вычислять градиенты для каждой выборки с меньшим объемом памяти, но с более низкой скоростью на графических процессорах до Volta (см. здесь)
Повторяющиеся: RNN, GRU и LSTM
Немного фона. Рекуррентные нейронные сети улавливают временные эффекты, используя промежуточные скрытые состояния, связанные в последовательность. Подобно другим блокам нейронной сети, они отображают последовательность входных векторов в последовательность выходных векторов. Рекуррентную нейронную сеть можно представить в виде ряда последовательных плоских слоев, каждый из которых состоит из цепочки ячеек (направленных либо вперед, либо назад). Ячейка, базовый элемент рекуррентной нейронной сети, преобразует один входной токен или его промежуточное представление и обновляет вектор скрытого состояния ячейки. Параметры рекуррентного слоя в основном представлены параметрами нижележащих ячеек. Все ячейки в одном плоском подслое имеют одинаковый набор параметров, т. е. независимо от времени ввод и текущее скрытое состояние проходят одно и то же преобразование. Существуют разные подходы к обработке временных зависимостей и реализации рекуррентных нейронных сетей. RNN, GRU и LSTM — три самые популярные реализации. Они вводят различные типы ячеек, основанные на параметризованном линейном преобразовании, но базовая форма нейронной сети остается неизменной.
Хорошо, теперь давайте поговорим о том, как обрабатывать повторяющиеся слои в Opacus. Чтобы эффективно вычислять градиенты для каждой выборки для повторяющихся слоев, нам нужно преодолеть небольшое препятствие: повторяющиеся слои в PyTorch реализованы на уровне cuDNN, а это означает, что Opacus не может добавить хук к внутренним компонентам слоя. клетки.
Чтобы преодолеть это препятствие, мы повторно реализовали все три типа ячеек на основе слоя RNNLinear. По сути, мы клонируем nn.Linear, чтобы иметь отдельную функцию вычисления градиента для каждого образца, которая накапливает градиенты в цепочке, а не объединяет их. Проще говоря, использование RNNLinear сообщает Opacus, что несколько вхождений одной и той же ячейки в нейронной сети относятся не к разным обучающим примерам, а к разным токенам в одном примере. Это позволяет Opacus суммировать по временному измерению и экономить много памяти.
Последнее, что нужно добавить, — это набор совместимых замен исходных слоев: DPRNN, DPGRU, DPLSTM. Они реализуют ту же логику, что и исходные модули из torch.nn, но основаны на ячейках, совместимых с Opacus.
Многоголовое внимание
Еще раз о многоголовом внимании: многоголовое внимание — один из основных компонентов трансформера. Многоголовое внимание вычисляет запросы, ключи и значения, применяя три линейных слоя к последовательности входных векторов, и возвращает комбинацию значений, взвешенных вниманием. Само внимание получается через softmax на скалярном произведении между запросами и ключами. В Pytorch все эти компоненты объединены на уровне cuDNN, чтобы обеспечить более эффективные вычисления.
Мы реализовали многоголовое внимание в Opacus в два этапа:
- Мы переписали многоголовое внимание, в основе которого лежат три линейных слоя. Opacus автоматически подключается к этим линейным слоям для вычисления градиентов для выборки; эти линейные слои используют
einsumдля вычисления образцов градации, как обсуждалось в предыдущем сообщении в блоге. - Мы реализовали дополнительный слой
SequenceBias, который добавляет вектор смещения ко всей последовательности, дополненный расчетом градиента для каждой выборки. Обратите внимание, что основной частью реализации являетсяSequenceBias, довольно простой модуль.
Другими словами, внимание с несколькими головками — это, по сути, набор линейных слоев, каждый из которых использует einsum для вычисления градиентов для каждой выборки.
Слои нормализации
При дифференциальной конфиденциальности уровни нормализации пакетов запрещены, так как они смешивают информацию по образцам пакета. Тем не менее другие типы нормализации, такие как LayerNorm, InstanceNorm или GroupNorm, разрешены и поддерживаются, поскольку они не нормализуют пакетное измерение и, следовательно, не смешивают информацию.
LayerNorm нормализует по всем каналам определенного семпла, а InstanceNorm нормализует по одному каналу определенного семпла. Операция GroupNorm находится между операциями LayerNorm и InstanceNorm; он нормализуется по «группе» каналов определенного образца.
Эти слои нормализации проиллюстрированы на следующем изображении (позаимствовано с https://arxiv.org/abs/1803.08494)

Легко заметить, что эти слои нормализации можно разделить на линейный слой (вы уже поняли схему наших трюков? :) ) и непараметризованный слой (который выполняет нормализацию среднего/дисперсии — слой нормализации). Следовательно, реализации для вычисления градиентов для выборки также довольно просты и аналогичны реализации линейного слоя.
Встраивание
Слой встраивания можно (еще раз) рассматривать как частный случай линейного слоя, где ввод является горячим кодированием, как показано на этом рисунке.

Таким образом, градиент слоя является внешним произведением однократного ввода и градиента вывода: конкретно это означает, что градиент слоя представляет собой матрицу нулей, за исключением строки, соответствующей входному индексу, где значение равно градиент на выходе. В частности, градиент по отношению к слою встраивания очень разрежен (единственные обновленные вложения — это те, что взяты из текущей выборки данных). Следовательно, для реализации градиентов для выборки мы создаем нулевую матрицу для встраивающего градиента и добавляем градиент только к входным позициям.
Обсуждение
Таким образом, Opacus вычисляет градиенты для каждой выборки путем (1) захвата активаций и градиентов шоссе, а затем (2) эффективного выполнения умножения матриц.
Для модулей, которые не легко поддаются матричному умножению (например, Conv, нормализация), мы делаем некоторый цирк линейной алгебры, чтобы получить его в правильной форме. Для модулей, которые не позволяют нам прикреплять хуки (например, RNN, Multt Head Attention), мы переопределяем их с помощью nn.Linear и действуем как обычно.
Когда мы повторно реализуем модули, мы гарантируем, что их param_dict() полностью совместимы с их аналогами без DP. Таким образом, например, когда вы закончите обучение своего DPMultiHeadAttention, вы можете напрямую загрузить его веса в nn.MultiheadAttention и использовать его в производстве для вывода, даже не требуя, чтобы у вас был установлен Opacus!
Модуль может быть строительным блоком или составным:
- Строительный блок. Это атомарные обучаемые модули (то есть классы по умолчанию), которые имеют свои собственные крючки и могут использоваться напрямую, например,
nn.Linear,nn.Conv1d,nn.Conv2d,nn.Conv3dи слои нормализации (nn.LayerNorm,nn.GroupNorm,nn.InstanceNorm). См. пункты 1,2,3 здесь. - Композитный. Это модули, состоящие из стандартных блоков. Составные модули поддерживаются до тех пор, пока поддерживаются все обучаемые подмодули. Замороженные подмодули не должны поддерживаться;
nn.Moduleможно заморозить в PyTorch, отключивrequires_gradв каждом из его параметров.
Излишне говорить, что модули без обучаемых параметров (например, nn.ReLU и nn.Tanh) и замороженные модули не нуждаются в вычислении их градиентов для каждой выборки, и, следовательно, эти модули поддерживаются из коробки.
Вышеприведенное обсуждение поддерживаемых модулей для эффективного вычисления градиента резюмировано в этом README.
Это все люди! Именно так Opacus реализует другие слои и поддерживает пользовательские модули.
Заключение
В этом сообщении блога мы объяснили идею эффективного вычисления градиентов для каждой выборки в Opacus для других слоев: свертки, LSTM, многоголовые внимания, нормализации, GRU, RNN, LSTM и встраивания. Мы также объяснили, как в Opacus могут поддерживаться произвольные модули, если они состоят из стандартных блоков и составных модулей.
Кроме того, с выпуском Opacus v1.2, в котором основное внимание уделяется включению основных улучшений в расчет градиента на выборку, недавно добавленных в ядро PyTorch, а именно functorch и ExpandedWeights, Теперь Opacus стал еще более гибким в вычислении градиентов для выборки. С помощью functorch Opacus теперь может обрабатывать почти все модели ввода, снимая прежнее ограничение, когда мы могли обрабатывать только определенные стандартные слои. С ExpandedWeight вычисление градиента для выборки станет на 30 % быстрее для большинства самых популярных моделей, которые по-прежнему состоят из стандартных слоев.
Следите за новостями из этой серии и делитесь своими мыслями и отзывами.