Освойте эти библиотеки для более гладкой карьеры

Если вы хотите изучить Python для науки о данных, чтобы начать новую карьеру, я уверен, что вы изо всех сил пытаетесь узнать и освоить все эти вещи. Я знаю, что вы ошеломлены всеми этими новыми концепциями, включая всю математику, которую вы должны знать, и вам может казаться, что вы никогда не достигнете цели своей новой работы.
Я знаю: должностные инструкции в этом не помогут. Действительно кажется, что специалисты по данным должны быть инопланетянами; даже юниоры, иногда.
На мой взгляд, важным навыком, которым нужно овладеть, является научиться избавляться от страха «я должен знать все.» Поверьте: особенно в начале, если вы претендуете на младшую должность, вам совершенно не обязательно знать все. Ну, по правде говоря: даже пенсионеры толком не все знают.
Итак, если вы хотите начать карьеру в Data Science, в этой статье я покажу вам пять библиотек Python, которые вам обязательно нужно знать.
1. Анаконда
Как мы видим на их сайте, Анаконда это:
Самая популярная в мире платформа распространения Python с открытым исходным кодом
Anaconda — это дистрибутив Python, специально созданный для Data Science; так что это не совсем библиотека, но мы можем рассматривать ее как библиотеку, потому что в разработке программного обеспечения библиотека представляет собой набор связанных модулей; Итак, поскольку Anaconda предоставляет все необходимое для специалистов по данным, включая наиболее часто используемые пакеты, мы можем использовать ее в качестве библиотеки, а также обязательной для вас.
Первая важная вещь, предоставляемая Anaconda, — это Jupyter Notebook, который:
оригинальное веб-приложение для создания и обмена вычислительными документами. Он предлагает простой, оптимизированный, ориентированный на документы опыт.
Jupyter Notebook — это веб-приложение, которое запускается локально на вашем компьютере и создано специально для специалистов по данным. Основная важная характеристика, которая делает его привлекательным (и очень полезным) для специалистов по данным, заключается в том, что каждая ячейка работает независимо, что дает нам возможность:
- Проводите математические и программные эксперименты в независимых ячейках, не затрагивая весь код.
- При необходимости напишите текст в каждой ячейке; это делает Jupyter Notebooks идеальной средой для представления научных работ с вашим кодом (поэтому вы можете забыть о средах Latex, если хотите).
Для начала работы с Jupiter Notebooks советую прочитать это руководство здесь.
Затем, когда вы наберетесь опыта, вам могут понадобиться некоторые ярлыки, чтобы ускорить ваш опыт. Вы можете использовать это руководство здесь.
Кроме того, как было сказано ранее, Anaconda предоставляет нам все пакеты, необходимые для Data Science. Таким образом, нам не нужно их устанавливать. Например, вам нужны «панды»; без Anaconda вам нужно установить его, набрав $ pip install pandas в своем терминале. С Anaconda вам не нужно этого делать, потому что он устанавливает pandas для нас. Очень хорошее преимущество!
2. Панды
Pandas — это библиотека, которая позволяет импортировать, обрабатывать и анализировать данные. На своем сайте они говорят, что
pandas — это быстрый, мощный, гибкий и простой в использовании инструмент для анализа и обработки данных с открытым исходным кодом, построенный на основе языка программирования Python.
Если вы хотите работать с данными, вам обязательно нужно освоить Pandas, потому что в настоящее время он широко используется учеными и аналитиками данных.
Сила Pandas заключается в том, что эта библиотека заставляет нас работать с табличными данными. В статистике табличные данные относятся к данным, организованным в виде таблицы со строками и столбцами. Обычно мы называем табличные данные фреймами данных.
Это важно, потому что мы работаем с табличными данными во многих ситуациях; например:
- С файлами excel.
- С файлами CSV.
- С базами данных.
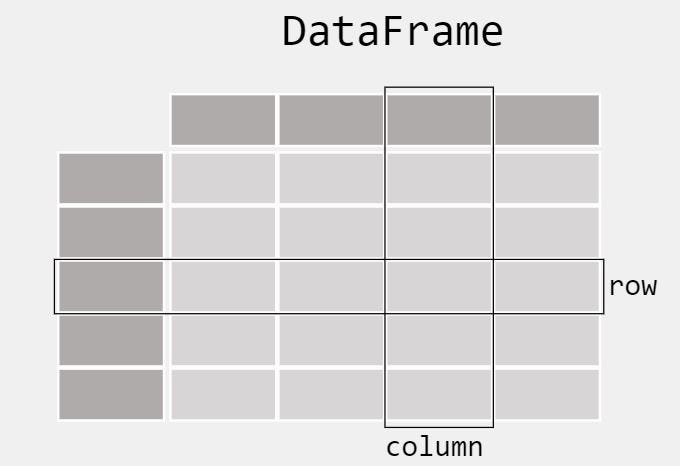
Реальность многих фирм такова, что, независимо от вашей роли, вам всегда придется иметь дело с данными в Excel/CSV и/или в базах данных; вот почему Pandas — это фундаментальный ресурс, который вам нужно освоить.
Кроме того, учтите, что вы даже можете получить доступ к данным из баз данных и получить их непосредственно в свои ноутбуки Jupyter для дальнейшего анализа в Pandas. Мы можем сделать это с помощью библиотеки под названием PyOdbc. Взгляните на это вот.
3. Матплотлиб
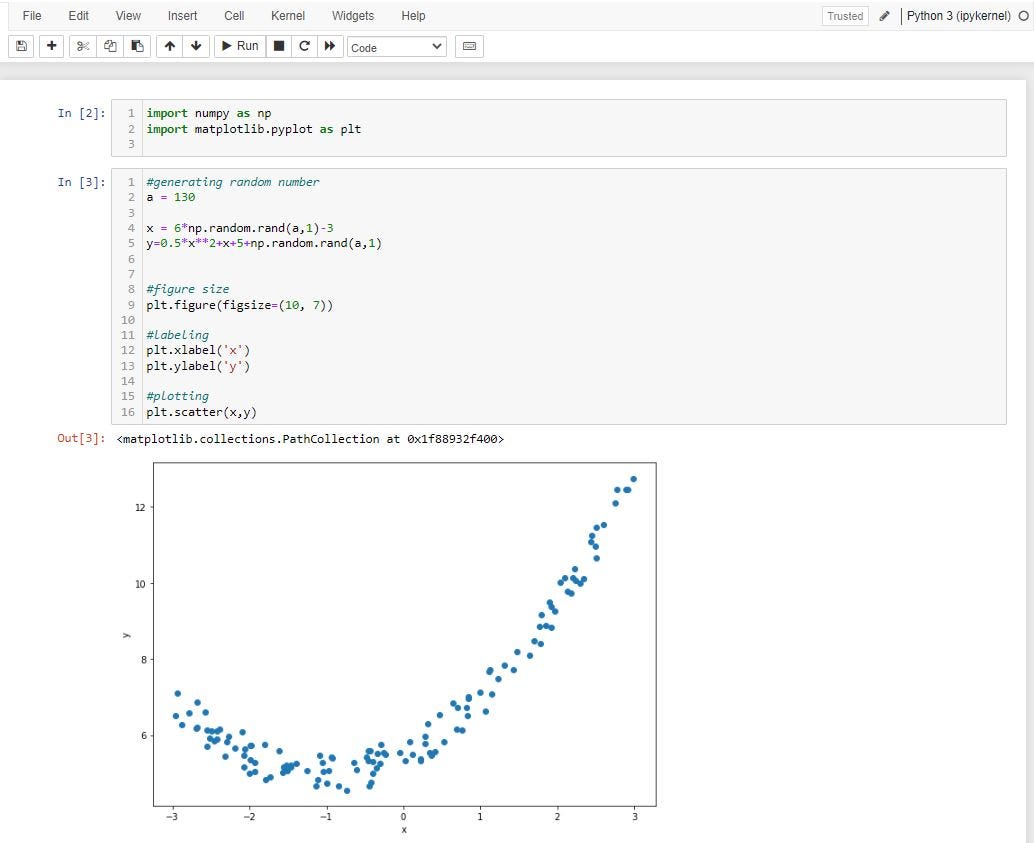
После обработки и анализа данных с помощью Pandas вы обычно хотите построить несколько графиков. Это можно сделать с помощью matplotlib, который:
обширная библиотека для создания статических, анимированных и интерактивных визуализаций на Python.
Matplotlib — первая библиотека для построения графиков, которую я вам советую использовать, потому что она широко используется и, на мой взгляд, помогает набраться опыта кодирования.
Matplotlib помогает нам построить наиболее важные графики, которые могут нам понадобиться:
- Статистические графики, такие как гистограммы или гистограммы.
- Диаграммы рассеяния.
- Боксплоты.
И многое другое. Вы можете начать работу с Matplotlib здесь, воспользовавшись их туториалами.
4. Сиборн
В какой-то момент, когда вы приобрели опыт анализа данных, вы можете быть не полностью удовлетворены Matplotlib; в основном (по моему опыту) это может быть связано с тем, что для выполнения расширенных графиков нам приходится писать много кода с помощью matplotlib. Вот почему Seaborn может вам помочь. Сиборн, по сути:
— это библиотека визуализации данных Python, основанная на matplotlib. Он предоставляет высокоуровневый интерфейс для рисования привлекательных и информативных статистических графиков.
Но что означает, что Seaborn в основном помогает нам с продвинутыми графиками, позволяя писать меньше кода, чем matplotlib? Например, предположим, что у вас есть данные о людях, дающих чаевые официантам. Мы хотим построить график общего счета и чаевых, но мы хотим даже показать, были ли люди курильщиками или нет, и были ли люди в ресторане на ужине или на запуске. Мы можем сделать так:
# Import seaborn
import seaborn as sns
# Apply the default theme
sns.set_theme()
# Load the dataset
tips = sns.load_dataset("tips")
# Create the visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
И мы получаем:

Итак, как мы видим, всего несколькими строчками кода мы можем добиться отличного результата благодаря Seaborn.
Итак, может возникнуть вопрос: «Должен ли я использовать Matplotlib или Seaborn?»
Мой совет — начать с Matplotlib, а затем перейти к Seaborn, когда вы приобретете некоторый опыт, потому что реальность такова, что большую часть времени мы используем и Matplotlib, и Seaborn (потому что помните: Seaborn основан на Matplotlib).
5. Научное обучение
Главное, что отличает Data Analyst от Data Scientist, — это способность использовать машинное обучение (ML). Машинное обучение — это область искусственного интеллекта, которая фокусируется на использовании данных и алгоритмов для классификации или прогнозирования.
В Python модели ML можно вызывать и обучать с помощью библиотеки под названием scikit-learn (иногда называемой sk-learn), которая представляет собой библиотеку:
Простые и эффективные инструменты для прогнозного анализа данных.
Как Data Scientist, вся работа, связанная с машинным обучением, выполняется в sk-learn, поэтому для вас крайне важно освоить хотя бы основы этой библиотеки.
Выводы
Библиотеки, которые мы представили, пронумерованы в порядке возрастания, и мой совет для вас — следовать этому порядку. Итак, прежде всего, установите Anaconda, чтобы настроить среду и получить опыт работы с Python, используя Jupiter Notebooks. Затем начните анализировать данные с помощью Pandas. Затем визуализируйте данные сначала с помощью Matplotlib, а затем с Seaborn. Наконец, используйте sk-learn для машинного обучения.
Подумайте о том, чтобы стать участником: вы можете поддержать меня без дополнительной платы. Нажмите здесь, чтобы стать участником менее чем за 5 долларов в месяц, чтобы вы могли разблокировать все истории и поддержать меня.