Классификатор евклидовых расстояний — это тип контролируемого алгоритма машинного обучения, который можно использовать для классификации данных по различным категориям. Он использует евклидову меру расстояния для классификации точек данных путем вычисления расстояния между ними и заданной опорной точкой. Измеряя расстояние между заданной точкой данных и опорной точкой, алгоритм присваивает метку на основе ближайшей опорной точки к точке данных. Этот тип классификации используется в различных приложениях, таких как обработка естественного языка, распознавание изображений и распознавание речи.

Проблема модели классификации
1. Мы разрабатываем евклидову классификационную модель для предсказания типа подводной лодки, проходящей через статическую подводную сенсорную систему.
2. Данные для модели предоставлены проектом DARPA, известным как REDSUB, который использует статические подводные датчики для определения длины, ширины, осадки и возмущений в толще воды, вызванных подводной лодкой.
3. Наша модель сможет точно различать дизель-электрическую подводную лодку класса «Юань» и атомную подводную лодку с баллистическими ракетами класса «Ся».
ПРОБЛЕМА С ДАННЫМИ
- Оцените текущий размер набора данных, чтобы определить, достаточно ли его для построения точного классификатора.
- Если набор данных слишком мал, изучите методы создания синтетических данных.
- Установите правила, определяющие, как должны выглядеть синтетические данные.
- Оцените доступные методы генерации синтетических данных и выберите лучший для задачи.
- Задокументируйте выбор метода и правила, используемые для создания синтетических данных, чтобы объяснить основу для классификатора.
- Используйте синтетические данные для создания надежного классификатора.
ДАННЫЕ

Введение
Классификация — это процесс присвоения точек данных заранее определенным категориям на основе некоторой метрики сходства. Одним из наиболее распространенных подходов к классификации является евклидова классификационная модель. В этой модели используется евклидово расстояние между двумя точками в пространстве признаков для определения категории, к которой принадлежит точка. В этом сообщении блога мы обсудим, как построить точную модель евклидовой классификации в Python.
ЗАДАНИЯ
Импортируйте необходимые библиотеки
import random as R import math import numpy as np from dataclasses import dataclass from matplotlib import pyplot as plt
Задача 1. Генерация синтетических данных
При построении модели классификации важно количество и качество доступных данных. Если набор данных слишком мал, он может не предоставить достаточно информации для создания надежного классификатора. В таких случаях необходимо генерировать синтетические данные. Это включает в себя использование правил для определения того, как должны выглядеть синтетические данные, а затем использование доступных методов для создания данных.
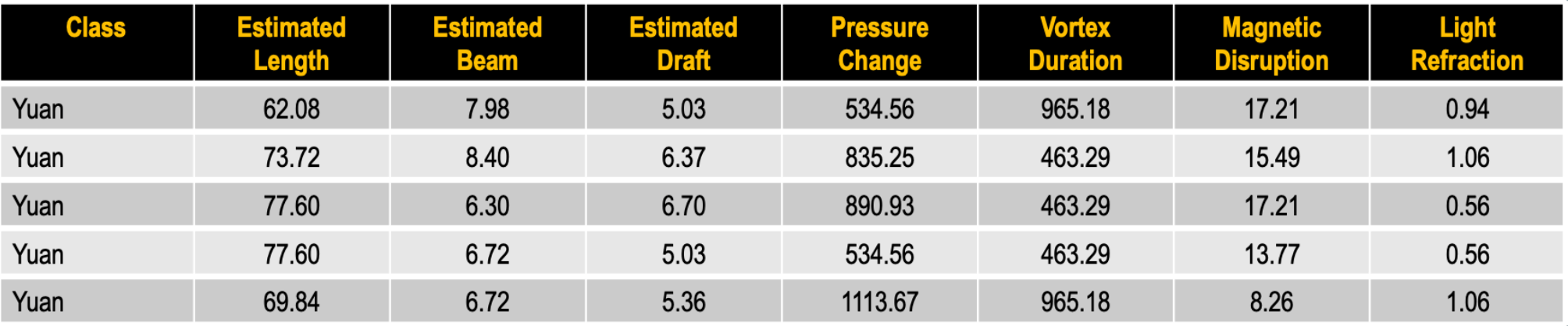
Yuan_data=np.array([
[62.08,7.98,5.03,534.56,965.18,17.21,0.94],
[73.72,8.40,6.37,835.25,463.29,15.49,1.06],
[77.60,6.30,6.70,890.93,463.29,17.21,0.56],
[77.60,6.72,5.03,534.56,463.29,13.77,0.56],
[69.84,6.72,5.36,1113.67,965.18,8.26,1.06]
])
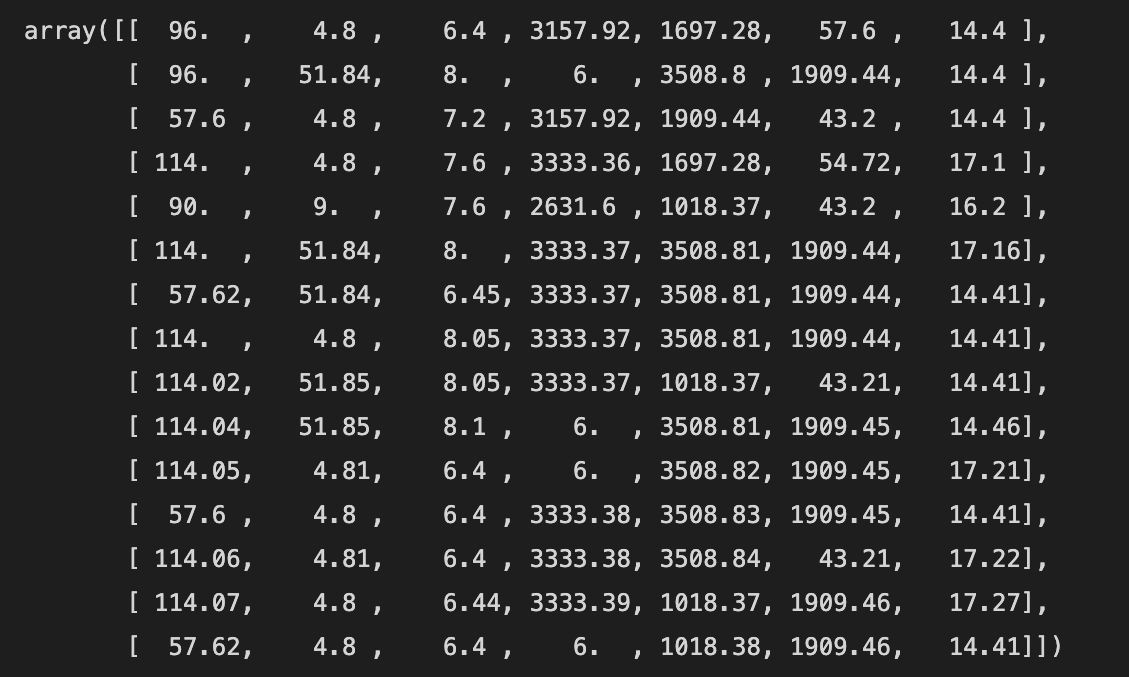
Xia_data=np.array([
[96.00,4.80,6.40,3157.92,1697.28,57.60,14.40],
[96.00,51.84,8.00,6.00,3508.80,1909.44,14.40],
[57.60,4.80,7.20,3157.92,1909.44,43.20,14.40],
[114.00,4.80,7.60,3333.36,1697.28,54.72,17.10],
[90.00,9.00,7.60,2631.60,1018.37,43.20,16.20]
])
Yuan_data
Xia_data
R.choice([Yuan_data[:,0].max(),Yuan_data[:,0].min()])+(Yuan_data[:,0].mean()/(Yuan_data[:,0].max()-Yuan_data[:,0].min()))*R.choice([0.01,0.001])
R.choice([Xia_data[:,0].max(),Xia_data[:,0].min()])+(Xia_data[:,0].mean()/(Xia_data[:,0].max()-Xia_data[:,0].min()))*R.choice([0.01,0.001])
@dataclass
class Yuan:
SampleNumber:int
Length:float
Bean:float
Draft:float
Pressure:float
Vortex:float
Magnetic:float
Light:float
Class:str
def __init__(self):
pass
def generate(self):
#generate data with two decimal places
global Yuan_data
self.SampleNumber=len(Yuan_data)+1
self.Length=R.choice([Yuan_data[:,0].max(),Yuan_data[:,0].min()])+(Yuan_data[:,0].mean()/(Yuan_data[:,0].max()-Yuan_data[:,0].min()))*R.choice([0.01,0.001])
self.Beam=R.choice([Yuan_data[:,1].max(),Yuan_data[:,1].min()])+(Yuan_data[:,1].mean()/(Yuan_data[:,1].max()-Yuan_data[:,1].min()))*R.choice([0.01,0.001])
self.Draft=R.choice([Yuan_data[:,2].max(),Yuan_data[:,2].min()])+(Yuan_data[:,2].mean()/(Yuan_data[:,2].max()-Yuan_data[:,2].min()))*R.choice([0.01,0.001])
self.Pressure=R.choice([Yuan_data[:,3].max(),Yuan_data[:,3].min()])+(Yuan_data[:,3].mean()/(Yuan_data[:,3].max()-Yuan_data[:,3].min()))*R.choice([0.01,0.001])
self.Vortex=R.choice([Yuan_data[:,4].max(),Yuan_data[:,4].min()])+(Yuan_data[:,4].mean()/(Yuan_data[:,4].max()-Yuan_data[:,4].min()))*R.choice([0.01,0.001])
self.Magnetic=R.choice([Yuan_data[:,5].max(),Yuan_data[:,5].min()])+(Yuan_data[:,5].mean()/(Yuan_data[:,5].max()-Yuan_data[:,5].min()))*R.choice([0.01,0.001])
self.Light=R.choice([Yuan_data[:,6].max(),Yuan_data[:,6].min()])+(Yuan_data[:,6].mean()/(Yuan_data[:,6].max()-Yuan_data[:,6].min()))*R.choice([0.01,0.001])
self.Class='YUAN'
def toVector(self):
return np.array([self.Length,self.Beam,self.Draft,self.Pressure,self.Vortex,self.Magnetic,self.Light])
@dataclass
class Xia:
SampleNumber:int
Length:float
Bean:float
Draft:float
Pressure:float
Vortex:float
Magnetic:float
Light:float
Class:str
def __init__(self):
pass
def generate(self):
global Xia_data
self.SampleNumber=len(Xia_data)+1
self.Length=R.choice([Xia_data[:,0].max(),Xia_data[:,0].min()])+(Xia_data[:,0].mean()/(Xia_data[:,0].max()-Xia_data[:,0].min()))*R.choice([0.01,0.001])
self.Beam=R.choice([Xia_data[:,1].max(),Xia_data[:,1].min()])+(Xia_data[:,1].mean()/(Xia_data[:,1].max()-Xia_data[:,1].min()))*R.choice([0.01,0.001])
self.Draft=R.choice([Xia_data[:,2].max(),Xia_data[:,2].min()])+(Xia_data[:,2].mean()/(Xia_data[:,2].max()-Xia_data[:,2].min()))*R.choice([0.01,0.001])
self.Pressure=R.choice([Xia_data[:,3].max(),Xia_data[:,3].min()])+(Xia_data[:,3].mean()/(Xia_data[:,3].max()-Xia_data[:,3].min()))*R.choice([0.01,0.001])
self.Vortex=R.choice([Xia_data[:,4].max(),Xia_data[:,4].min()])+(Xia_data[:,4].mean()/(Xia_data[:,4].max()-Xia_data[:,4].min()))*R.choice([0.01,0.001])
self.Magnetic=R.choice([Xia_data[:,5].max(),Xia_data[:,5].min()])+(Xia_data[:,5].mean()/(Xia_data[:,5].max()-Xia_data[:,5].min()))*R.choice([0.01,0.001])
self.Light=R.choice([Xia_data[:,6].max(),Xia_data[:,6].min()])+(Xia_data[:,6].mean()/(Xia_data[:,6].max()-Xia_data[:,6].min()))*R.choice([0.01,0.001])
self.Class='XIA'
def toVector(self):
return np.array([self.Length,self.Beam,self.Draft,self.Pressure,self.Vortex,self.Magnetic,self.Light])

Задача 2. Формирование данных
После создания набора данных его необходимо преобразовать в формат, который может использоваться моделью. Это включает в себя организацию данных по функциям, меткам и другим категориям.
samples_to_generae=10
for i in range(samples_to_generae):
yuan=Yuan()
yuan.generate()
xia=Xia()
xia.generate()
Yuan_data=np.vstack((Yuan_data,yuan.toVector()))
Xia_data=np.vstack((Xia_data,xia.toVector()))
#format to 2 decinmal places
Yuan_data=np.around(Yuan_data,2)
Xia_data=np.around(Xia_data,2)
#add class label
Yuan_data=np.hstack((Yuan_data,np.array([['YUAN']]*Yuan_data.shape[0]).reshape(-1,1)))
Xia_data=np.hstack((Xia_data,np.array([['XIA']]*Xia_data.shape[0]).reshape(-1,1)))
#add sample number
Yuan_data=np.hstack((np.array(['YSN-{}'.format(i) for i in range(1,Yuan_data.shape[0]+1)]).reshape(-1,1),Yuan_data))
Xia_data=np.hstack((np.array(['XSN-{}'.format(i) for i in range(1,Xia_data.shape[0]+1)]).reshape(-1,1),Xia_data))
Сохраните текстовые файлы
np.savetxt('Yuan.txt',Yuan_data,fmt='%s',delimiter=' ')
np.savetxt('Xia.txt',Xia_data,fmt='%s',delimiter=' ')
#remove index and class label from the data
Yuan_data=Yuan_data[:,1:-1].astype(float)
Xia_data=Xia_data[:,1:-1].astype(float)
Задача 3. Нормализация данных
Нормализация данных важна для обеспечения того, чтобы каждый признак имел одинаковый диапазон значений. Это позволяет модели более точно сравнивать различные функции.
Разделите данные на обучающую и тестовую выборки в соотношении 70:30.
#split the data into training and testing sets in the ratio 70:30 Yuan_train=Yuan_data[:int(0.7*Yuan_data.shape[0])] Yuan_test=Yuan_data[int(0.7*Yuan_data.shape[0]):] Xia_train=Xia_data[:int(0.7*Xia_data.shape[0])] Xia_test=Xia_data[int(0.7*Xia_data.shape[0]):] #perform z-score normalization Yuan_train=(Yuan_train-Yuan_train.mean(axis=0))/Yuan_train.std(axis=0) Yuan_test=(Yuan_test-Yuan_test.mean(axis=0))/Yuan_test.std(axis=0) Xia_train=(Xia_train-Xia_train.mean(axis=0))/Xia_train.std(axis=0) Xia_test=(Xia_test-Xia_test.mean(axis=0))/Xia_test.std(axis=0)
Задача 4. Создание шаблона
Следующим шагом является создание шаблона для модели. Этот шаблон позволит модели сравнивать точки данных и определять, к какой категории они принадлежат.
#create the mean vector for each numeric feature
Yuan_mean_vector=Yuan_train.mean(axis=0)
Xia_mean_vector=Xia_train.mean(axis=0)
#calculate the square root of the sum of the squared differences between the mean vector and each sample
yuan_distances=np.sqrt(np.sum((Yuan_train-Yuan_mean_vector)**2,axis=1))
xia_distances=np.sqrt(np.sum((Xia_train-Xia_mean_vector)**2,axis=1))
#get minimum,maximum,range,mean,median,variance,standard deviation for each class
yuan_min=np.min(yuan_distances)
yuan_max=np.max(yuan_distances)
yuan_range=yuan_max-yuan_min
yuan_mean=np.mean(yuan_distances)
yuan_median=np.median(yuan_distances)
yuan_var=np.var(yuan_distances)
yuan_std=np.std(yuan_distances)
xia_min=np.min(xia_distances)
xia_max=np.max(xia_distances)
xia_range=xia_max-xia_min
xia_mean=np.mean(xia_distances)
xia_median=np.median(xia_distances)
xia_var=np.var(xia_distances)
xia_std=np.std(xia_distances)
#print the analysis
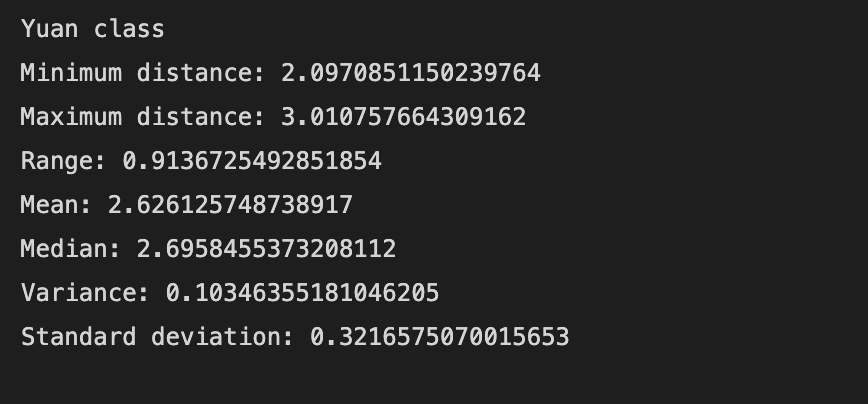
print('Yuan class')
print('Minimum distance: {}'.format(yuan_min))
print('Maximum distance: {}'.format(yuan_max))
print('Range: {}'.format(yuan_range))
print('Mean: {}'.format(yuan_mean))
print('Median: {}'.format(yuan_median))
print('Variance: {}'.format(yuan_var))
print('Standard deviation: {}'.format(yuan_std))
print("\n\n\n")
print('Xia class')
print('Minimum distance: {}'.format(xia_min))
print('Maximum distance: {}'.format(xia_max))
print('Range: {}'.format(xia_range))
print('Mean: {}'.format(xia_mean))
print('Median: {}'.format(xia_median))
print('Variance: {}'.format(xia_var))
print('Standard deviation: {}'.format(xia_std))

Преобразование данных в число с плавающей запятой
#convert the test data to float Yuan_test=Yuan_test.astype(float) Xia_test=Xia_test.astype(float)
Задание 5. Расчет расстояния
Модель будет использовать евклидово расстояние между двумя точками в пространстве признаков, чтобы определить категорию, к которой принадлежит точка. Для этого требуется вычислить расстояние между двумя точками в пространстве признаков.
#normalize the test data Yuan_test=(Yuan_test-Yuan_test.mean(axis=0))/Yuan_test.std(axis=0) Xia_test=(Xia_test-Xia_test.mean(axis=0))/Xia_test.std(axis=0) #euclidean distance between the each sample and the mean vector yuan_test_distances=np.sqrt(np.sum((Yuan_test-Yuan_mean_vector)**2,axis=1)) xia_test_distances=np.sqrt(np.sum((Xia_test-Xia_mean_vector)**2,axis=1))
Задача 6. Определение пороговых значений
Чтобы определить, к какой категории относится точка, необходимо установить пороги. Эти пороговые значения будут использоваться для определения категории, к которой следует отнести точку, исходя из расстояния между двумя точками.
#add sample number to distances
yuan_test_distances=np.hstack((np.array(['YSN-{}'.format(i) for i in range(1,yuan_test_distances.shape[0]+1)]).reshape(-1,1),yuan_test_distances.reshape(-1,1)))
xia_test_distances=np.hstack((np.array(['XSN-{}'.format(i) for i in range(1,xia_test_distances.shape[0]+1)]).reshape(-1,1),xia_test_distances.reshape(-1,1)))
Задача 7. Классифицировать
После установки пороговых значений модель можно использовать для классификации точек данных. Это включает в себя использование модели для сравнения точек данных и определения, к какой категории они принадлежат.
#classify the test data. If the distance is less than max distance of the training data, then it is classified as correct, otherwise it is classified as incorrect
Yuan_correct=0
Yuan_incorrect=0
Xia_correct=0
Xia_incorrect=0
for i in range(yuan_test_distances.shape[0]):
if float(yuan_test_distances[i,1])<=yuan_max:
Yuan_correct+=1
else:
Yuan_incorrect+=1
for i in range(xia_test_distances.shape[0]):
if float(xia_test_distances[i,1])<=xia_max:
Xia_correct+=1
else:
Xia_incorrect+=1
accuracy=(Yuan_correct+Xia_correct)/(Yuan_correct+Yuan_incorrect+Xia_correct+Xia_incorrect)
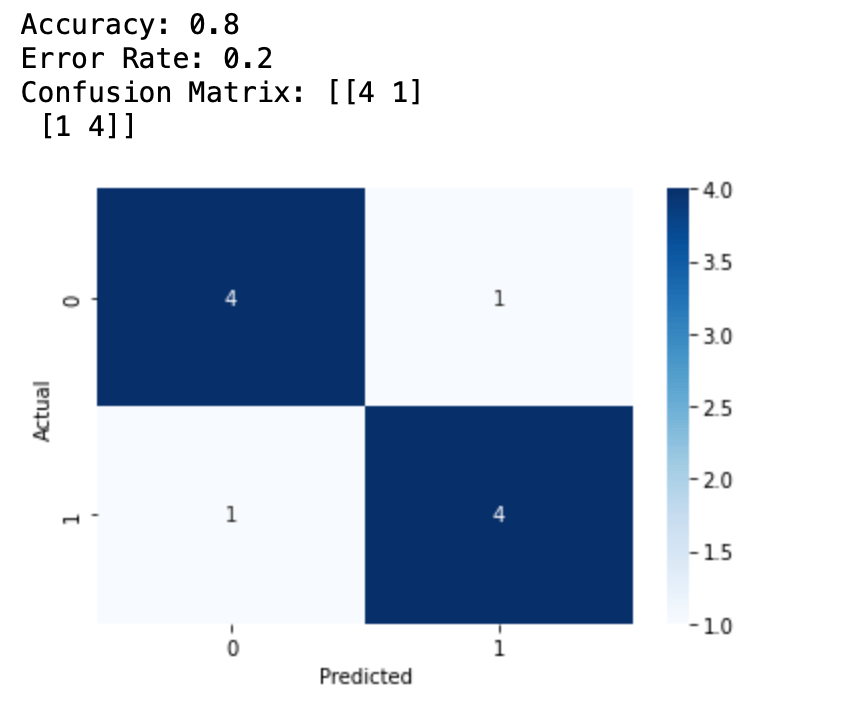
print("Accuracy: {}".format(accuracy))
Задание 8. Анализ классификатора
После того, как модель была использована для классификации точек данных, важно проанализировать точность модели. Это включает в себя определение того, как часто модель правильно классифицирует точки данных и как часто она неправильно классифицирует точки данных.
#calculate error rate which is number of incorrect classifications divided by total number of classifications
error_rate=(Yuan_incorrect+Xia_incorrect)/(Yuan_correct+Yuan_incorrect+Xia_correct+Xia_incorrect)
print("Error Rate: {}".format(error_rate))
Задача 9. Используйте классификатор
После определения точности модели ее можно использовать для классификации новых точек данных. Это предполагает использование модели для сравнения новой точки данных с существующими точками данных и определения категории, к которой она принадлежит.
Задача 10. Определите пригодность классификатора
Наконец, важно определить, подходит ли модель для поставленной задачи. Это включает в себя оценку точности модели и определение того, достаточно ли ее для поставленной задачи.
#calculate and plot confusion matrix
confusion_matrix=np.array([[Yuan_correct,Xia_incorrect],[Xia_incorrect,Xia_correct]])
print("Confusion Matrix: {}".format(confusion_matrix))
Вы также можете построить график точности модели, чтобы визуализировать модель.
#plot confusion matrix as a heatmap
import seaborn as sns
sns.heatmap(confusion_matrix,annot=True,fmt='d',cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
Заключение
В этом сообщении блога мы обсудили, как построить точную модель евклидовой классификации в Python. Мы обсудили различные задачи, связанные с построением модели, такие как создание синтетических данных, нормализация данных, создание шаблона, расчет расстояния между точками, установка пороговых значений, классификация точек данных, анализ точности модели и определение пригодности модели. модель. Следуя этим шагам, можно построить точную и надежную модель классификации.
Ману Бхардвадж
