
Ван Цинкан (Ли Фань) и Чжан Кай
Предисловие
Обладая многолетним опытом поддержки продуктов и клиентов Kubernetes, команда Alibaba Cloud Container Service for Kubernetes значительно оптимизировала и расширила Kube-scheduler для стабильного и эффективного планирования различных сложных рабочих нагрузок в различных сценариях. Эта серия статей под названием Расцветающая система планирования Kubernetes предоставляет пользователям и разработчикам Kubernetes исчерпывающий обзор нашего опыта, технического мышления и конкретных методов реализации. Мы надеемся, что статьи помогут вам лучше понять мощные возможности и будущие тенденции системы планирования Kubernetes.
Предисловие
Во-первых, давайте взглянем на определения совместного планирования и группового планирования. Согласно Википедии, совместное планирование — это планирование связанных процессов для одновременного запуска на разных процессорах в параллельных системах. В сценариях совместного планирования основной принцип заключается в том, чтобы гарантировать, что все связанные процессы могут быть запущены в одно и то же время. Это предотвращает блокировку всей группы процессов исключениями в некоторых процессах. Аномальный процесс, блокирующий группу, называется фрагментом.
Во время реализации совместное планирование можно разделить на явное совместное планирование, локальное совместное планирование и неявное совместное планирование в зависимости от того, разрешены ли фрагменты. Среди них явное совместное планирование известно как групповое планирование. Групповое планирование не допускает фрагментов, что означает все или ничего.
Сопоставив предыдущие концепции с Kubernetes, вы сможете понять, почему система планирования Kubernetes поддерживает совместное планирование для пакетных заданий. Пакетное задание (эквивалентно связанной группе процессов) содержит N модулей (эквивалентно процессам). Планировщик Kubernetes планирует одновременный запуск этих N модулей на M узлах (эквивалентно процессорам). Предположим, что это пакетное задание может выполняться до тех пор, пока количество подов запускается одновременно. Мы определяем минимальное количество подов, которое нам нужно запустить одновременно, как минимально доступное. Когда min-available равно N, пакетное задание должно соответствовать требованиям группового планирования.
Почему система планирования Kubernetes требует совместного планирования?
Kubernetes широко используется для оркестровки онлайн-сервисов. Чтобы улучшить использование и эффективность работы кластеров, мы надеемся использовать Kubernetes в качестве единой платформы управления для управления онлайн-сервисами и автономными заданиями. Планировщик по умолчанию планирует модули последовательно, не учитывая отношения между модулями. Однако для многих автономных заданий, связанных с вычислением данных, требуется комбинированное планирование. Комбинированное планирование означает, что все задачи должны быть созданы до того, как общее задание сможет работать должным образом. Если некоторые задачи запущены, а другие нет, запущенные задачи ждут, пока планировщик запланирует оставшиеся задачи. Это сценарий группового планирования.
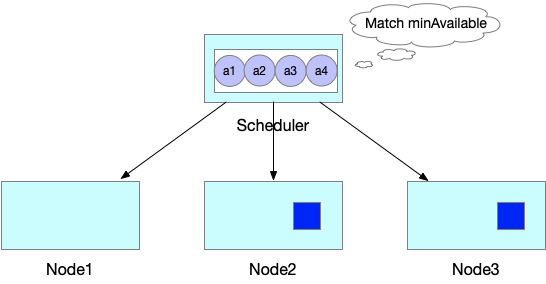
Как показано на следующем рисунке, JobA может работать правильно только при одновременном запуске четырех модулей. Kube-scheduler последовательно планирует и создает три модуля. Однако ресурсов кластера недостаточно, чтобы Kube-scheduler запланировал четвертый pod. В результате первые три модуля для JobA остаются в состоянии ожидания и продолжают занимать ресурсы. Если четвертый модуль не может быть запущен вовремя, весь JobA не может быть запущен, и, что еще хуже, занятые ресурсы кластера тратятся впустую.
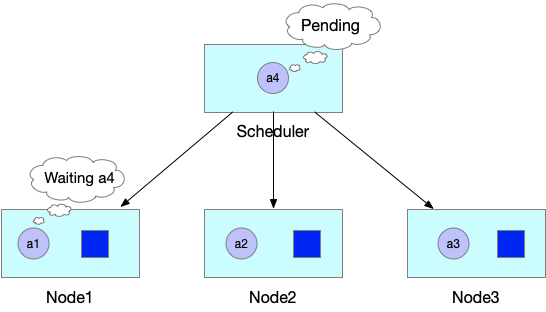
В худшем случае, как показано на следующем рисунке, другие ресурсы кластера заняты первыми тремя модулями JobB, и Kube-scheduler также ожидает создания четвертого модуля для JobB. В результате возникает взаимоблокировка, выводящая из строя весь кластер.
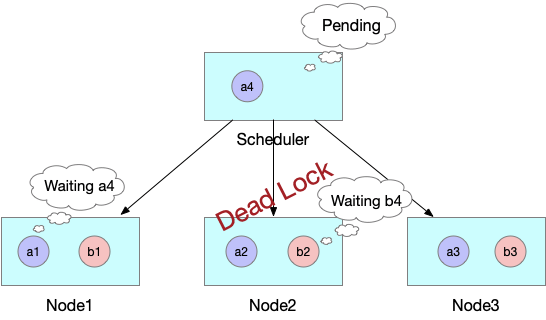
Решения, предоставляемые сообществом
Чтобы преодолеть предыдущие болевые точки, сообщество предоставляет проект Kube-batch и проект Volcano, производный от проекта Kube-batch. В частности, сообщество разработало новый планировщик для планирования PodGroups вместо модулей во время планирования. Другими словами, планировщик планирует модули по группам. В этих проектах новый планировщик планирует модули, для которых требуется функция совместного планирования, а Kube-scheduler — другие модули, например те, которые запускают онлайн-сервисы.
Эти проекты могут решить проблемы совместного планирования, но создают новые проблемы. Как мы все знаем, планировщику необходимо централизовать ресурсы в одном кластере. Однако, если в одном кластере сосуществуют два планировщика, могут возникнуть конфликты решений. Например, одна единица ресурсов может быть отдельно выделена двум разным подам. В результате модуль, запланированный для узла, может не создаться из-за нехватки ресурсов. Единственным решением является принудительное разделение узлов с помощью меток или развертывание нескольких кластеров. В этом случае и онлайн-сервисы, и автономные задания выполняются в одном и том же кластере Kubernetes, что неизбежно приводит к трате ресурсов кластера и увеличению затрат на эксплуатацию и техническое обслуживание. Кроме того, для запуска проекта Volcano необходимо запустить пользовательские файлы MutatingAdmissionWebhook и ValidatingAdmissionWebhook. Эти веб-перехватчики создают риск единой точки отказа. В случае сбоя любого веб-перехватчика все модули в кластере могут не быть созданы. Запуск дополнительного планировщика также увеличивает сложность обслуживания и ставит под угрозу совместимость с вышестоящим API Kube-scheduler.
Планирование решения на основе платформы
В первой статье этой серии мы представили архитектурные принципы и метод разработки Kubernetes Scheduling Framework. Исходя из этого, мы можем расширить и внедрить подключаемый модуль совместного планирования, чтобы позволить собственному планировщику Kubernetes планировать пакетные задания, избегая при этом проблем предыдущего решения. В предыдущей статье также было представлено подробное описание Scheduling Framework. Вы можете прочитать его для получения дополнительной информации.
Чтобы лучше управлять плагинами планирования в различных сценариях, команда sig-scheduling, отвечающая за Kube-scheduler в Kubernetes, создала проект под названием scheduler-plugins. Плагин совместного планирования, реализованный на основе Scheduling Framework, стал первым официальным плагином для этого проекта. В следующем разделе я подробно опишу реализацию и использование плагина совместного планирования.
Техническое решение
Общая архитектура
Группа подов
Мы определяем PodGroups с помощью меток. Поды с одинаковым ярлыком принадлежат к одной и той же группе подов. Кроме того, min-available используется для указания минимального количества реплик, которое требуется для правильной работы задания PodGroup.
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "2"Примечание. Поды в одной группе должны иметь одинаковый приоритет.
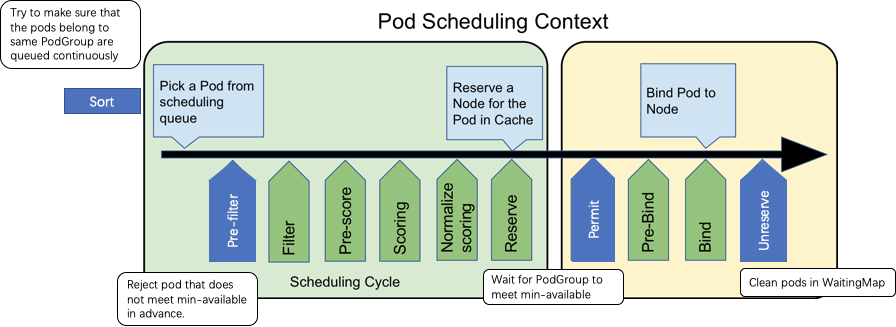
Разрешить
Подключаемый модуль Permit в Scheduling Framework предоставляет функцию отложенной привязки. В частности, для модуля, который входит в фазу разрешения, вы можете настроить условие, позволяющее модулю пройти фазу, запретить модулю проходить фазу или оставить модуль в ожидании. Когда вы держите модуль в ожидании, вы можете указать период ожидания для модуля. Функция отложенной привязки для фазы Permit позволяет модулям, принадлежащим к одной и той же группе PodGruop, ждать после того, как они будут запланированы для узла. Когда для узла запланировано необходимое количество модулей, планировщик может запустить все модули из одной и той же группы PodGroup для привязки и создания всех модулей.
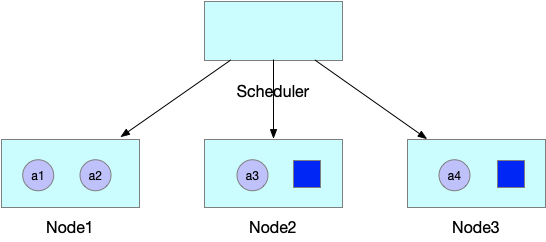
Предположим, что задание JobA может работать правильно, только если одновременно запущены четыре модуля для задания, но текущие ресурсы кластера позволяют создать только три модуля. В отличие от планировщика по умолчанию, который сначала планирует и создает три модуля, подключаемый модуль Permit в Scheduling Framework удерживает все модули в ожидании.
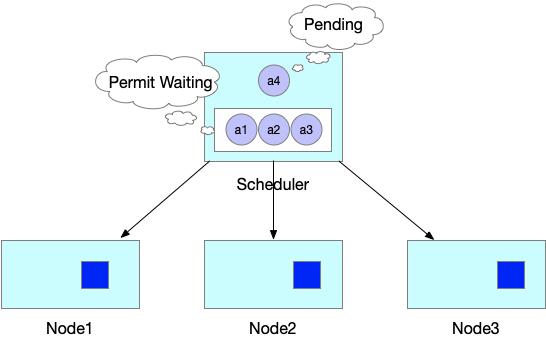
Затем, когда в кластере освобождаются простаивающие ресурсы и все ресурсы, необходимые модулям для JobA, доступны, планировщик планирует и создает все четыре модуля JobA и запускает JobA.
Сортировка по очереди
Очередь планировщика по умолчанию не воспринимает информацию PodGroup. Таким образом, поды в PodGroups не идут по порядку при удалении из очереди. Как показано на следующем рисунке, модули a и b относятся к разным группам модулей. Когда модули двух групп PodGroups входят в очередь, модули размещаются в очереди в шахматном порядке из-за поэтапного времени создания.

После того, как модуль создан и добавлен в очередь, он не является смежным с другими модулями той же группы PodGroup. Вместо этого он ставится в очередь с другими модулями в шахматном порядке.

В результате, если PodGroupA находится в состоянии ожидания на этапе Permit, модули PodGroupB остаются в состоянии ожидания после того, как будут запланированы модули PodGroupB. Ресурсы, занятые двумя группами, не позволяют планировать как PodGroupA, так и PodGroupA. В этом случае взаимоблокировка возникает на этапе Разрешения, а не на узле, и предыдущая проблема не решается.
Чтобы решить предыдущую проблему, мы внедрили подключаемый модуль QueueSort, чтобы гарантировать, что модули одной и той же группы PodGroup находятся рядом друг с другом в очереди. Мы определяем метод Less для плагина QueueSort, чтобы определить порядок модулей в очереди:
func Less(podA *PodInfo, podB *PodInfo) boolВо-первых, подключаемый модуль наследует метод сравнения на основе приоритета по умолчанию, гарантируя, что модули с более высоким приоритетом предшествуют модулям с более низким приоритетом.
Затем мы определяем новую логику организации очереди для поддержки сортировки модулей в группе модулей в случае, когда модули имеют одинаковый приоритет.
- Если оба модуля являются обычными модулями, за первым созданным модулем следует другой модуль в очереди.
- Если один из подов является обычным подом, а другой — pgPod, что указывает на принадлежность пода к определенной группе подов, подключаемый модуль QueueSort сравнивает время создания обычного пода со временем создания подгруппы, к которой принадлежит pgPod. За модулем с более ранним временем создания следует другой модуль в очереди.
- Если оба модуля являются pgPod, подключаемый модуль QueueSort сравнивает время создания двух групп PodGroups, которым принадлежат pgPod. За модулем с более ранним временем создания следует другой модуль в очереди. Кроме того, когда обе PodGroup создаются одновременно, мы вводим автоматически увеличивающиеся идентификаторы, чтобы за модулем с более низким идентификатором PodGroup следовал другой модуль в очереди. Идентификаторы используются для различения разных PodGroups.
При использовании предыдущих политик очередей мы разрешаем модулям в одной и той же группе PodGroup располагаться рядом друг с другом в очереди.

После того, как модуль создан и добавлен в очередь, он будет находиться рядом с другими модулями, принадлежащими к той же группе PodGroup.

Предварительный фильтр
Чтобы уменьшить количество неэффективных операций планирования и повысить производительность планирования, мы добавляем условие фильтрации на этапе предварительной фильтрации. Перед планированием модуля планировщик вычисляет сумму модулей, включая запущенные модули, в той же группе модулей, что и модуль. Если сумма меньше минимально доступной, требование минимальной доступной не выполняется. Затем планировщик отклоняет модуль на этапе предварительной фильтрации, и модуль не вступает в основной процесс планирования.
Отменить резервирование
Если время ожидания модуля истекло в фазе разрешения, модуль переходит в фазу отмены резервирования. Планировщик отклоняет все модули в той же группе PodGroup, что и модуль на этапе UnReserve, чтобы предотвратить длительное ожидание оставшихся модулей.
Попробуйте совместное планирование
Установка и развертывание
Вы можете попробовать совместное планирование в кластере Kubernetes самостоятельной сборки или любой выделенной службе Kubernetes, предоставляемой общедоступным облаком. Примечание. Версия кластера должна быть 1.16 или выше, и у вас должно быть разрешение на обновление основных узлов кластера.
В этой статье для тестирования функции совместного планирования используется кластер Kubernetes, предоставленный Alibaba Cloud Container Service for Kubernetes (ACK).
Прежде чем начать
- Убедитесь, что вы используете Kubernetes 1.16 или более позднюю версию.
- Создать выделенный кластер, предоставляемый ACK
- Убедитесь, что узлы кластера могут получить доступ к общедоступной сети
- Убедитесь, что версия Helm, установленная на первичных узлах по умолчанию, является версией V3. Если установлен Helm V2, обновите его до Helm V3. Дополнительные сведения об установке Helm V3 см. в разделе Установка Helm V3](https://helm.sh/docs/intro/install/).
Развертывание совместного планирования
Мы уже встроили код подключаемого модуля coscheduling и собственного планировщика в новые образы контейнеров и предоставили пакет Helm Chart с именем ack-coscheduling для автоматической установки. Пакет запускает задание для автоматической замены собственного планировщика, установленного в кластере, планировщиком совместного планирования и изменения файла конфигурации, связанного с планировщиком, чтобы платформа планирования могла загрузить подключаемый модуль совместного планирования. После пробного периода вы можете восстановить планировщик по умолчанию и связанные с ним конфигурации кластера, используя функцию удаления, описанную в следующем разделе.
Загрузите пакет Helm Chart и выполните следующую команду, чтобы установить Helm Chart:
$ wget http://kubeflow.oss-cn-beijing.aliyuncs.com/ack-coscheduling.tar.gz
$ tar zxvf ack-coscheduling.tar.gz
$ helm install ack-coscheduling -n kube-system ./ack-coscheduling
NAME: ack-coscheduling
LAST DEPLOYED: Mon Apr 13 16:03:57 2020
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: NoneПодтвердить совместное планирование
На основном узле выполните следующую команду helm, чтобы убедиться, что подключаемый модуль совместного планирования установлен:
$ helm get manifest ack-coscheduling -n kube-system | kubectl get -n kube-system -f -
NAME COMPLETIONS DURATION AGE
scheduler-update-clusterrole 1/1 8s 35s
scheduler-update 3/1 of 3 8s 35sУдалить совместное планирование
Выполните следующую команду helm, чтобы удалить подключаемый модуль coscheduling, чтобы откатить версию и конфигурации kube-scheduler до состояния по умолчанию в кластере.
$ helm uninstall ack-coscheduling -n kube-systemИнструкции
Чтобы использовать совместное планирование, вам нужно всего лишь настроить следующие метки в файле YAML, который вы используете для создания задания: pod-group.scheduling.sigs.k8s.io/name и pod-group.scheduling.sigs.k8s.io/min-available.
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "3"pod-group.scheduling.sigs.k8s.io/name: имя группы подов.
pod-group.scheduling.sigs.k8s.io/min-available: указывает, что задание может быть запланировано целиком только тогда, когда ресурсы текущего кластера достаточны для запуска минимально доступных модулей.
Примечание. Поды в одной группе должны иметь одинаковый приоритет.
Демо
В следующем разделе мы продемонстрируем результаты совместного планирования, запустив распределенное обучающее задание TensorFlow (TFJob). Тестовый кластер имеет четыре графических процессора (GPU).
1. Разверните среду выполнения для TFJob в существующем кластере Kubernetes, используя Arena Kubeflow.
Arena — это один из подпроектов Kubeflow, сообщества с открытым исходным кодом для систем машинного обучения на основе Kubernetes. Arena позволяет управлять заданиями машинного обучения с помощью командной строки и SDK на следующих этапах жизненного цикла: установка среды, подготовка данных, разработка модели, обучение модели и прогнозирование модели. Arena эффективно повышает продуктивность специалистов по данным.
git clone https://github.com/kubeflow/arena.git
kubectl create ns arena-system
kubectl create -f arena/kubernetes-artifacts/jobmon/jobmon-role.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-crd.yaml
kubectl create -f arena/kubernetes-artifacts/tf-operator/tf-operator.yamlПроверьте, развернута ли среда выполнения.
$ kubectl get pods -n arena-system
NAME READY STATUS RESTARTS AGE
tf-job-dashboard-56cf48874f-gwlhv 1/1 Running 0 54s
tf-job-operator-66494d88fd-snm9m 1/1 Running 0 54s2. Попросите пользователя отправить TFJob в кластер. В следующем примере TFJob включает в себя один модуль сервера параметров и четыре рабочих модуля, и каждому рабочему процессу требуется два графических процессора. После настройки PodGroup задание можно запустить, только если запущено не менее пяти модулей PodGroup.
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "tf-smoke-gpu"
spec:
tfReplicaSpecs:
PS:
replicas: 1
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
cpu: '1'
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
Worker:
replicas: 4
template:
metadata:
creationTimestamp: null
labels:
pod-group.scheduling.sigs.k8s.io/name: tf-smoke-gpu
pod-group.scheduling.sigs.k8s.io/min-available: "5"
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: registry.cn-hangzhou.aliyuncs.com/kubeflow-images-public/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 2
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure3. Чтобы смоделировать выполнение задания без функции совместного планирования, выполните следующие действия:
Удалите метки pod-group.scheduling.sigs.k8s.io/name и pod-group.scheduling.sigs.k8s.io/min-available из YAML-файла TFJob. Этот шаг указывает, что в задании не используется совместное планирование. После создания задания ресурсы кластера позволяют запустить только двух рабочих процессов. Два других работника находятся в состоянии ожидания.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 1/1 Running 0 6m43s
tf-smoke-gpu-worker-0 1/1 Running 0 6m43s
tf-smoke-gpu-worker-1 1/1 Running 0 6m43s
tf-smoke-gpu-worker-2 0/1 Pending 0 6m43s
tf-smoke-gpu-worker-3 0/1 Pending 0 6m43sПроверьте журналы работающих воркеров. Вы обнаружите, что оба рабочих ждут начала работы двух других рабочих. В этом случае все четыре графических процессора заняты, но задание не выполняется.
$ kubectl logs -f tf-smoke-gpu-worker-0
INFO|2020-05-19T07:02:18|/opt/launcher.py|27| 2020-05-19 07:02:18.199696: I tensorflow/core/distributed_runtime/master.cc:221] CreateSession still waiting for response from worker: /job:worker/replica:0/task:3
INFO|2020-05-19T07:02:28|/opt/launcher.py|27| 2020-05-19 07:02:28.199798: I tensorflow/core/distributed_runtime/master.cc:221] CreateSession still waiting for response from worker: /job:worker/replica:0/task:24. Чтобы смоделировать выполнение задания с помощью функции совместного планирования, выполните следующие действия:
Добавьте метки, связанные с PodGroup, и создайте задание. Ресурсы кластера не могут соответствовать минимально доступным требованиям. В результате невозможно запланировать PodGroup, и все модули остаются в состоянии ожидания.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 0/1 Pending 0 43s
tf-smoke-gpu-worker-0 0/1 Pending 0 43s
tf-smoke-gpu-worker-1 0/1 Pending 0 43s
tf-smoke-gpu-worker-2 0/1 Pending 0 43s
tf-smoke-gpu-worker-3 0/1 Pending 0 43sТеперь, если вы масштабируете кластер, добавляя четыре графических процессора, ресурсы могут соответствовать минимально доступным требованиям, PodGroup можно запланировать, и все четыре рабочих процесса начнут работать.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
tf-smoke-gpu-ps-0 1/1 Running 0 3m16s
tf-smoke-gpu-worker-0 1/1 Running 0 3m16s
tf-smoke-gpu-worker-1 1/1 Running 0 3m16s
tf-smoke-gpu-worker-2 1/1 Running 0 3m16s
tf-smoke-gpu-worker-3 1/1 Running 0 3m16sПросмотрите журнал одного из рабочих. Вы обнаружите, что работа по обучению началась.
$ kubectl logs -f tf-smoke-gpu-worker-0
INFO|2020-05-19T07:15:24|/opt/launcher.py|27| Running warm up
INFO|2020-05-19T07:21:04|/opt/launcher.py|27| Done warm up
INFO|2020-05-19T07:21:04|/opt/launcher.py|27| Step Img/sec loss
INFO|2020-05-19T07:21:05|/opt/launcher.py|27| 1 images/sec: 31.6 +/- 0.0 (jitter = 0.0) 8.318
INFO|2020-05-19T07:21:15|/opt/launcher.py|27| 10 images/sec: 31.1 +/- 0.4 (jitter = 0.7) 8.343
INFO|2020-05-19T07:21:25|/opt/launcher.py|27| 20 images/sec: 31.5 +/- 0.3 (jitter = 0.7) 8.142Идти вперед
Совместное планирование реализовано на основе механизма Kubernetes Scheduling Framework. Он соответствует требованиям комбинированного планирования в пакетных заданиях искусственного интеллекта (ИИ) и вычислений данных, снижает потери ресурсов и улучшает общее использование ресурсов кластеров.
В последующих статьях этой серии мы предоставим дополнительные сведения о политиках планирования для пакетных заданий, включая планирование емкости и функции управления несколькими очередями. Мы также опишем разработку и реализацию политик планирования в Scheduling Framework. Оставайтесь с нами, чтобы узнать больше!