Добро пожаловать в NeeshAi!
Нам доставляет огромное удовольствие написать эту статью. Когда мы начинали несколько недель назад, я и представить себе не мог, что мы зайдем так далеко. Вы можете подумать, что это не так уж и важно; это может быть правдой, но все, что я хочу сказать, это то, что нет предела тому, что мы можем исследовать.
Итак, не теряя времени, приступим. Мы уже рассмотрели основную интуицию, лежащую в основе рекуррентных нейронных сетей, в предыдущем учебнике. В этом уроке мы собираемся реализовать сеть на простом задании-генерации предложений.
Вкратце:
Мы видели, что рекуррентные нейронные сети отличаются от простых сетей тем, что они дополнительно имеют соединения, которые либо соединяются напрямую с тем же уровнем, либо даже с более низкими уровнями (теми, которые ближе к входам). Эти непрямые соединения называются рекуррентными соединениями. Рекуррентные соединения имеют временную задержку (обычно 1 временной шаг при использовании дискретного времени), что позволяет модели узнать о своих предыдущих входных данных.
В традиционной нейронной сети предполагается, что все входы (и выходы) независимы друг от друга. Но если мы хотим предсказать следующее слово в предложении, нам лучше знать, какие слова стояли перед ним. RNN называются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, а результат зависит от предыдущих вычислений. Мы можем предположить, что RNN являются нейронными сетями, имеющими «память», которая фиксирует информацию о том, что было рассчитано до сих пор.
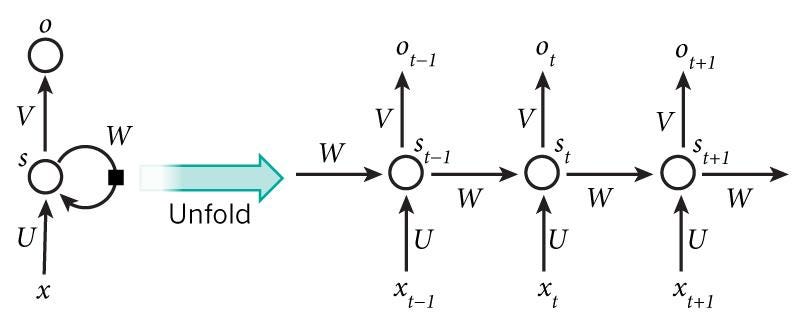
Я надеюсь, что вы в состоянии вспомнить вещи, которые мы обсуждали.
Есть 2 примера RNN, которые были объяснены с помощью примеров. Первый случай с базовым уровнем RNN был включен в репозиторий Github как Recurrent_Neural_Network_Basic_Case.ipynb и оставлен для понимания пользователем. Второй случай, относящийся к тексту, был опубликован в том же репозитории только как RNN_Detailed_Case.ipynb.
Приступаем к реализации:
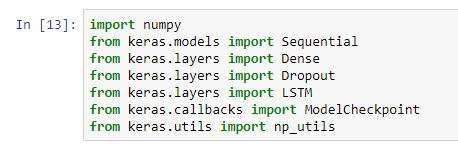
Как обычно импортируйте все необходимые модули.
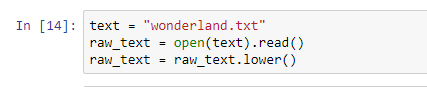
Следующее, что мы собираемся сделать, это прочитать текстовый файл и преобразовать все символы в нижний регистр. Этот процесс гарантирует, что все символы будут только в нижнем регистре, а символы верхнего и нижнего регистра будут рассматриваться как равные.
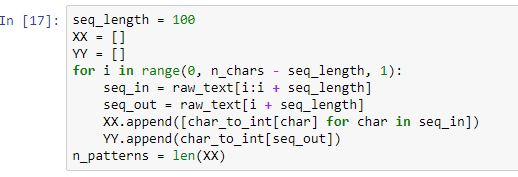
Теперь мы возьмем уникальные символы из всего текста (который по сути является набором всех изначально присутствующих символов), а затем преобразуем их все в целочисленный формат (идея преобразования их в целочисленный вид заключается в более быстром и удобном процессе обучения).

Теперь у нас есть 50 уникальных символов в целочисленном формате. Следующее, что мы хотим сделать, это создать входные данные для нашей модели. Входными данными для нашей модели является последовательность символов. На данный момент мы принимаем длину последовательности равной 100, т.е. у нас будет набор данных size= (количество исходных символов-длина последовательности). Для каждых входных данных (последовательность из 100 символов) следующий символ будет нашим выходом.
Теперь у нас есть набор данных, но всегда полезно их стандартизировать. Мы собираемся преобразовать нашу целевую переменную в один формат горячего кодирования (предположим, у вас есть функция «Имя», которая может принимать значения «Рам», «Шьям» и «Мохан». Одно горячее кодирование преобразует функцию «Имя» в три функции, «is_Ram», «is_Shyam» и «is_Mohan», которые являются двоичными). Мы также собираемся изменить и нормализовать нашу входную переменную (Нормализация относится к процессу создания чего-то «стандартного», он обеспечивает избыточность данных и повышает целостность данных).

Теперь у нас есть набор данных в стандартном формате. Здесь наступает самая важная часть процесса, то есть определение модели. Мы собираемся использовать 1 скрытый слой сети LSTM с 256 скрытыми единицами и вероятностью отсева 0,2.
Dropout – это метод регуляризации, при котором при обновлении слоев нейронной сети вы случайным образом не обновляете или "отбрасываете" некоторые слои. То есть при обновлении слоя нейронной сети вы обновляете каждый узел с вероятностью «1-выпадение» и оставляете его без изменений с вероятностью «выпадения».
Мы также используем «categorical_crossentropy» в качестве функции потерь, «adam» в качестве оптимизатора и «softmax» в качестве функции активации.
Вы можете поиграть со всеми этими вещами, чтобы лучше понять, как работает сеть LSTM.

Мы собираемся обучать нашу модель с 20 эпохами и размером пакета 128. Вы всегда можете увеличить количество эпох, пока модель продолжает улучшаться. Также мы собираемся создать контрольные точки, чтобы в дальнейшем модель можно было извлечь и использовать. Идея создания контрольной точки состоит в том, чтобы сохранить вес модели во время тренировки, чтобы позже вам не пришлось повторять тот же процесс снова.

Теперь у нас есть файл веса, сохраненный в нужном месте. Мы собираемся повторно использовать его в прогнозировании. Мы выберем случайную последовательность символов в качестве первого ввода и будем изменять ее до тех пор, пока не получим желаемое количество выходных символов.
В нашем случае мы собираемся записать последовательность из 100 символов в качестве входных данных и сгенерируем следующие 100 символов в качестве выходных данных.
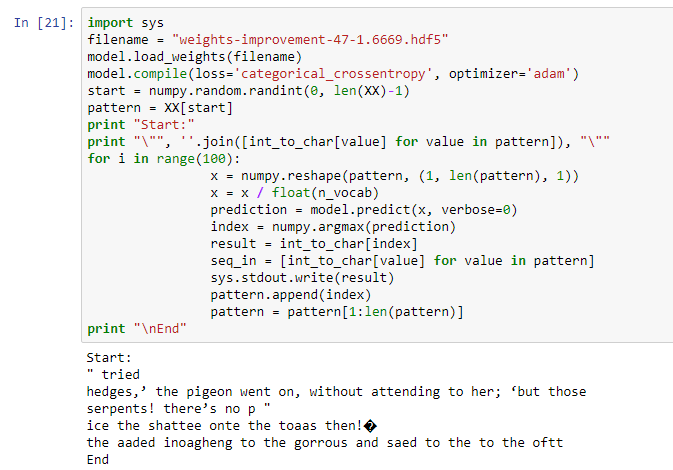
Полученный результат не совсем удовлетворяет. Но здесь есть две вещи, на которые стоит обратить внимание: во-первых, он смог изучить шаблон количества символов в одной строке, и поэтому он продолжает менять строку после среднего количества символов (выводятся последние три строки). . Второй касается шаблона правильного слова, например, «лед», «тот», «добавлено» и «тогда» — это настоящие слова. Но многие другие слова не имеют смысла. Это ограничение можно преодолеть, построив сеть LSTM с более чем одним уровнем, увеличив количество эпох и увеличив длину набора данных.
Обучение большого набора данных с использованием ЦП занимает слишком много времени. Вот почему использование графического процессора было почти неизбежным, что очень важно для быстрого обучения моделей глубокого обучения.
Обучение рекуррентной нейронной сети — увлекательное занятие. Тот же алгоритм может быть расширен для многих других упражнений, таких как генерация музыки, генерация речи и т. д. Его также можно эффективно расширить для реальных приложений, таких как «видео субтитры» и «языковой перевод».
Вот и все, что касается генерации текста с использованием рекуррентной нейронной сети. Надеюсь, вам понравилась эта статья, и вы готовы создать свою собственную систему генерации текста. Создание музыкальных текстов будет забавным упражнением, если вы подумываете об этом.
Подпишитесь на NeeshAi, чтобы узнать больше о науке о данных, управлении продуктами и многом другом в области технологий!
Ссылки: