В сегодняшней статье мы поговорим о самом важном понятии машинного обучения: трех частях моделирования, также известных как три набора. Возможно, вы не ожидали этой темы, если вы не такой гик, как я, но после прочтения этого поста вы станете на один шаг ближе к моему уровню гика, так что…. поздравляю!
Прежде чем мы углубимся в удивительный мир трех наборов, позвольте мне объяснить важную концепцию: обобщение. Это относится к способности модели машинного обучения хорошо работать с данными, которых она раньше не видела. Вам может быть интересно, почему это важно. Что ж, позвольте мне объяснить вам:
- Представьте, что вы учитель в случайной школе, возможно, в Алабаме (поскольку мы любим тракторы). Но по ошибке вы отправляете экзамен, который должны сдать ваши ученики, до того, как они его сдадут. Как ты думаешь, что произойдет?
Да, ваши ученики получат самые высокие оценки, которые когда-либо видели их родители, но учились ли они на самом деле? Наверное, нет — они просто запомнили все ответы. После того, как они выкурят свои косяки с марихуаной после школы, они все забудут. И это именно то, чего мы хотим избежать с помощью машинного обучения. Нам не нужна машина, которая просто запоминает — мы хотим, чтобы она могла учиться сама. И тут на помощь приходят три комплекта.
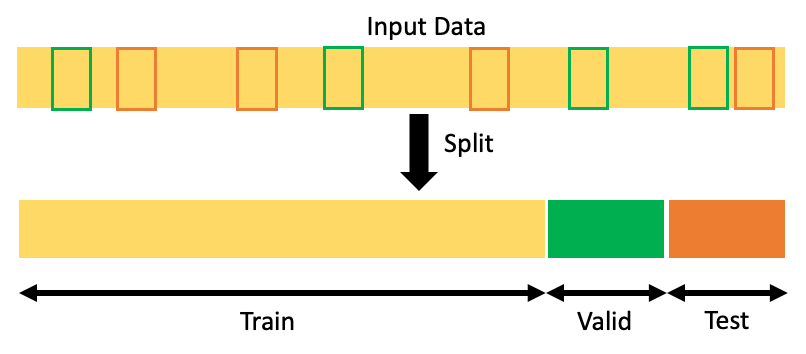
Обучение:
Это набор данных, который наша модель использует для изучения любых базовых закономерностей или взаимосвязей, которые впоследствии позволят делать прогнозы.
Учебный набор должен быть максимально репрезентативным для населения, которое мы пытаемся смоделировать. Кроме того, мы должны быть осторожны и убедиться, что он максимально беспристрастен, поскольку любое смещение на этом этапе может распространяться вниз по течению во время вывода.
Проверка:
В машинном обучении проверка относится к процессу оценки производительности обученной модели на новом наборе данных, который не использовался в процессе обучения. Это важный шаг в рабочем процессе машинного обучения, поскольку он позволяет оценить способность модели обобщать новые данные и оценить ее общую производительность.
Наиболее распространенная форма проверки в машинном обучении называется «перекрестная проверка». При перекрестной проверке доступные данные разбиваются на два или более подмножества: обучающий набор, который используется для обучения модели, и проверочный набор, который используется для оценки производительности модели. Этот процесс повторяется несколько раз с разными подмножествами данных, используемых для обучения и проверки, чтобы получить более точную оценку производительности модели.
Существует несколько различных способов выполнения перекрестной проверки, но одним из наиболее распространенных является перекрестная проверка в k-кратном порядке. При k-кратной перекрестной проверке данные делятся на k подмножеств одинакового размера или «складок». Затем модель обучается на k-1 сгибах и оценивается на оставшихся сгибах. Этот процесс повторяется k раз, при этом каждая складка используется в качестве набора проверки один раз. Затем результаты k оценок усредняются, чтобы получить единую оценку производительности модели.
Проверка — важный шаг в машинном обучении, потому что он позволяет вам проверить, соответствует ли ваша модель данным. Переобучение происходит, когда модель слишком сложна и запоминает обучающие данные, что приводит к плохой работе с новыми данными. Недообучение происходит, когда модель слишком проста и не может уловить основные закономерности в данных. Проверяя модель на новых данных, вы можете лучше оценить ее реальную производительность и избежать этих проблем.

Тест:
Набор тестовых данных — это набор данных, который используется для оценки производительности обученной модели после того, как она была полностью разработана и оптимизирована с использованием набора обучающих данных.
Набор тестовых данных обычно отделен от набора данных для обучения, что означает, что он содержит данные, которые модель ранее не видела во время обучения. Это важно, потому что дает объективный способ оценить способность модели обобщать новые, невидимые данные.
После того, как модель обучена с использованием обучающего набора данных, она тестируется с использованием тестового набора данных, и ее производительность оценивается на основе некоторых предопределенных показателей, таких как точность, воспроизводимость, оценка F1 или любой другой показатель производительности, подходящий для конкретной задачи. .
Стоит отметить, что тестовый набор данных следует использовать только для окончательной оценки после завершения разработки модели. Гиперпараметры модели не следует настраивать в зависимости от производительности тестового набора данных, так как это может привести к переоснащению тестового набора. Вместо этого гиперпараметры следует оптимизировать на основе производительности модели в отдельном проверочном наборе, который также отличается как от обучающего, так и от тестового наборов данных.
В целом, использование тестового набора данных является важным шагом в конвейере машинного обучения, поскольку он помогает гарантировать, что обученная модель будет хорошо работать с новыми, невидимыми данными, что является ключевой целью любой задачи машинного обучения.
Если вы визуальный ученик, загляните на эту страницу: https://mlu-explain.github.io/train-test-validation/
Надеюсь, вам понравился пост. Если вам это нравится, пожалуйста, поделитесь им. И кто знает, может быть, когда-нибудь вы сами будете водить трактор в Алабаме!»