Введение
В предыдущей статье мы обсудили проблемы, с которыми сталкивается машинный перевод, и представили механизм внимания, предложенный в Нейронный машинный перевод путем совместного обучения выравниванию и переводу.
В этой статье мы сосредоточимся на представлении Scaled Dot-Product Attention, лежащем в основе Transformer, и подробно объясним его вычислительную логику и принципы проектирования.
В конце статьи мы также приведем пример использования Attention, надеясь дать читателям более полное представление о Attention после прочтения.
Масштабированное скалярное произведение внимания
Теперь мы изучили прототип механизма внимания, однако он не решает проблему медленной обработки ввода. Чтобы повысить скорость вычислений и использовать возможности параллельных вычислений, необходимо отказаться от традиционного подхода по одному символу за раз.
В статье Внимание — это все, что вам нужно для преодоления этой проблемы было представлено масштабированное скалярное произведение внимания. Формула выглядит следующим образом:

Формула может показаться сложной, но ее можно разбить на более простые шаги. Давайте рассмотрим каждый шаг, чтобы понять принцип, лежащий в его основе.
1. QKᵀ
На этом этапе мы работаем с двумя матрицами: Q (Запрос) и K (Ключ). Предположим, что у Q есть три части данных, а у K — четыре части данных. Размеры двух матриц равны 3 * dₖ и 4 * dₖ соответственно.
Важно отметить, что две матрицы должны иметь одинаковое количество столбцов. Интерпретация такова:
- Q имеет три фрагмента данных, и каждый фрагмент данных представлен вектором длины dₖ.
- K имеет четыре фрагмента данных, и каждый фрагмент данных представлен вектором длины dₖ.
Если размерность входных последовательностей, используемых для представления Q и K, не совпадает, или если вы хотите указать специальное dₖ, вы можете использовать Linear(input_q_dim, dₖ) и Linear(input_k_dim, dₖ) для линейного преобразования исходных измерений Query и Key в dₖ.
Назначение этих двух слоев — преобразовать две последовательности в одно и то же векторное пространство.

Теперь, когда у нас есть матрицы Q и K (при условии, что dₖ = 4), давайте подробнее рассмотрим, что делает QKᵀ.
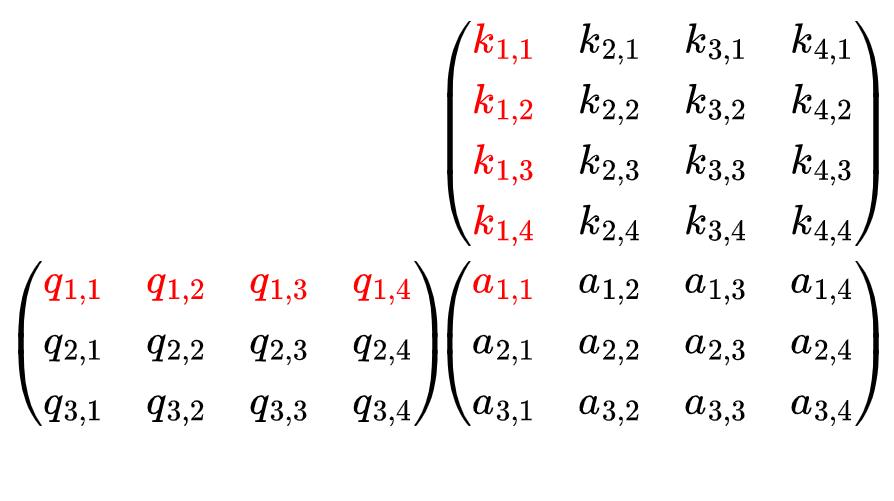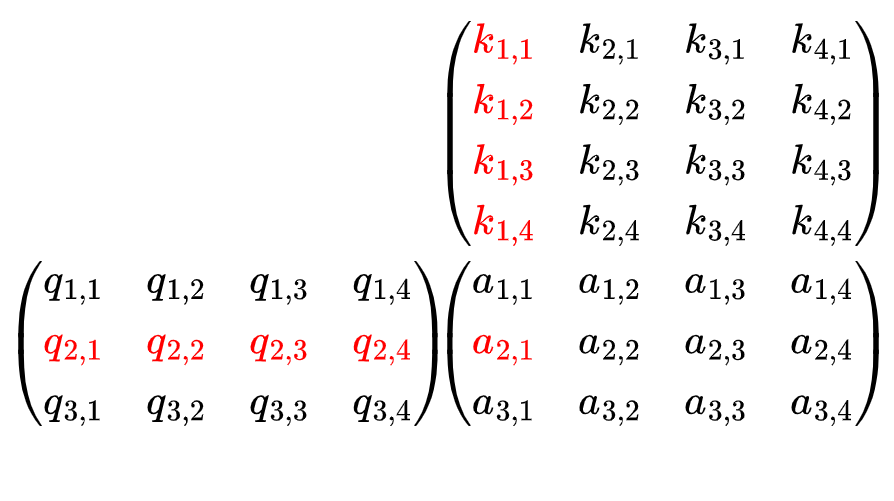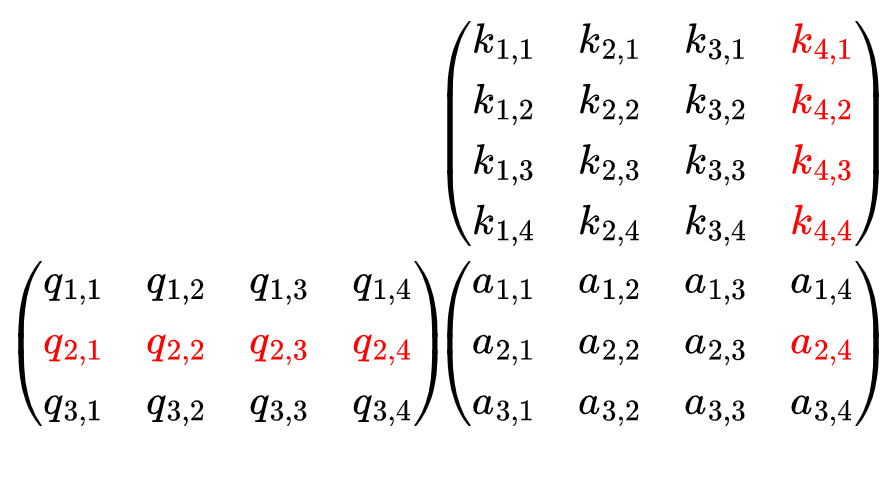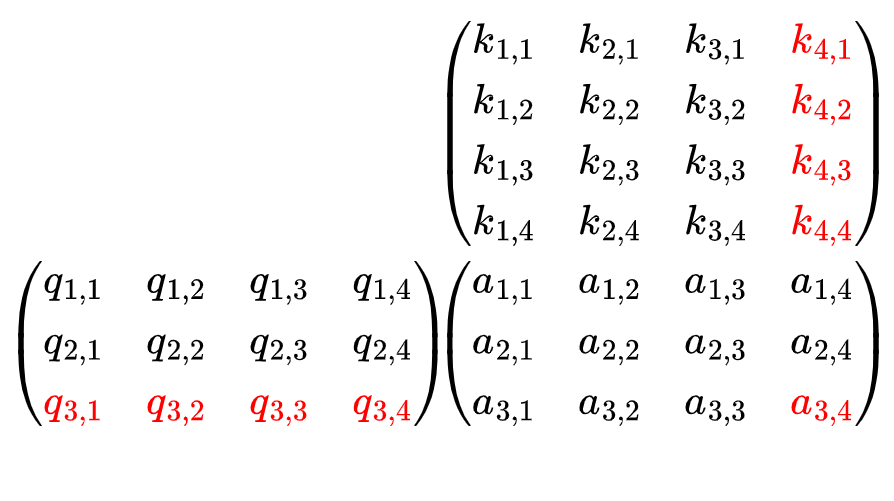
Анимация показывает, что произведение матрицы запроса и ключа, QKᵀ, дает матрицу 3x4.
Этот этап соответствует операции скалярного произведения, поскольку элемент (i, j) результирующей матрицы является скалярным произведением строки i в Q и строки j в K , что также представляет важность Kⱼ для Qᵢ.
Таким образом, до сих пор механизм Scaled Dot-Product Attention выполнял следующие шаги:
- Он отображает входные запросы и ключи в одно и то же векторное пространство, где их внутренний продукт приводит к более высоким значениям для более релевантных пар (это преобразование изучается моделью).
- Он вычисляет таблицу внимания A, взяв внутреннее произведение матрицы запроса и ключа.
2. softmax(A/√dₖ)
Этап соответствует разделу Scaled в его названии. Чтобы понять этот шаг, важно сначала понять функцию softmax.

Для каждой строки в A функция softmax сопоставляет каждому элементу значение от 0 до 1, так что сумма значений в каждой строке равна 1.
Если мы зафиксируем конкретную координату zᵢ и изменяем только это значение, удерживая другие элементы в векторе постоянными, результирующая функция будет похожа на сигмовидную кривую:
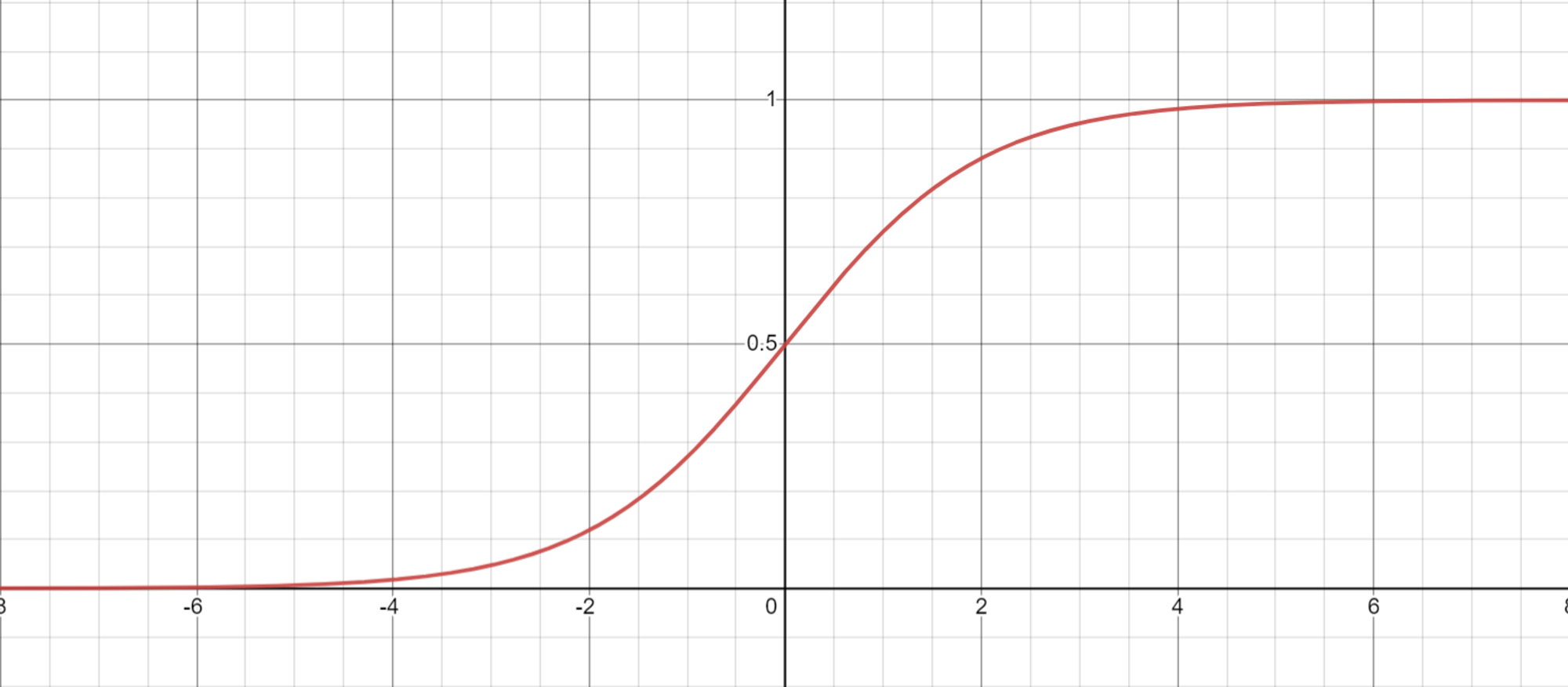
Примечательно, что градиент функции softmax почти равен нулю при экстремальных значениях, что затрудняет обновление соответствующих параметров во время обучения.
Если dₖ, размерность векторов ключа и значения, задана как большая, скалярное произведение в матрице внимания A с большей вероятностью попадет в эти области, поскольку существует dₖ членов, которые необходимо умножить и суммировать.
Чтобы смягчить эту проблему, вводится коэффициент масштабирования √dₖ, чтобы уменьшить величину оценок и уменьшить вероятность появления исчезающих градиентов.
Этот метод помогает улучшить стабильность и сходимость модели во время обучения.
Мы называем матрицу, которая проходит через softmax, A’.
Дополнительно (необязательно):
Предполагая, что каждый элемент в векторе запроса и ключевыбирается независимо из стандартного нормального распределения N(0, 1), в соответствии с приведенной ниже формулой скалярного произведения:

скалярное произведение q и k следует нормальному распределению со средним значением 0 и дисперсией dₖ.
Разделив скалярный продукт на √dₖ, вы получите дисперсию, равную 1.
3. A’V
Прежде чем углубляться в этот раздел, давайте вспомним свойства A’:
- A’ имеет то же количество строк, что и количество входных запросов.
- A’ имеет то же количество столбцов, что и количество входных ключей.
- Каждый элемент в каждой строке A’ лежит в диапазоне от 0 до 1, где запись (i, j) представляет значимость j-го ключа для i-го запроса.
- Сумма всех элементов в одной строке A’ равна 1.
Предполагая, что A’ выглядит следующим образом:

Далее давайте обсудим V, который представляет фактические значения за ключами.
Ключи можно рассматривать как идентификаторы учащихся, а значения — как информацию, такую как имена, классы и оценки. Вы используете студенческий билет, чтобы найти человека, но за ним стоит соответствующая информация. Для модели то же самое: значения — это то, что она фактически использует для расчета.
Размер V представлен dᵥ, для которого можно установить любое подходящее значение. Вы также можете использовать Linear(input_k_dim, dᵥ) для преобразования входного вектора в это измерение.
Обратите внимание, что я установил первый параметр приведенной выше команды на input_k_dim, потому что источником ключей и значений должен быть один и тот же вектор, но один преобразуется в пространство Q для сравнения, а другой преобразуется в фактические значения. .
Другими словами, ключи и значения имеют однозначное соответствие: первое значение соответствует первому ключу, второе значение соответствует второму ключу и так далее.
Внешний вид V выглядит следующим образом:
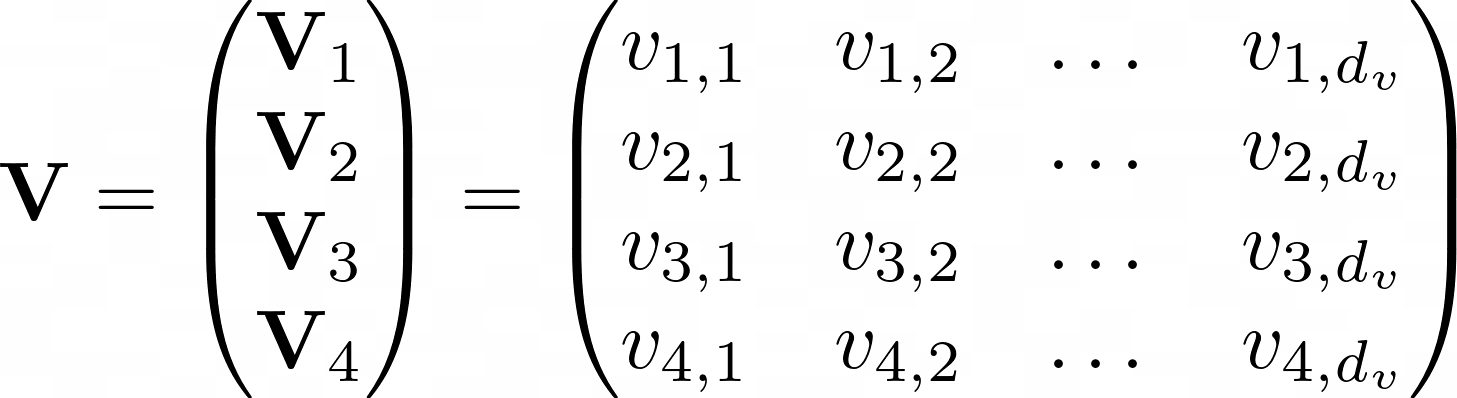
Давайте посмотрим, что делает A’V:

Из приведенного выше уравнения мы можем заметить, что A’V будет:
- Создайте матрицу, в которой количество строк равно количеству запросов.
- Для каждого запроса его окончательное значение представляет собой средневзвешенное значение строк в V.
- Веса основаны на внутреннем произведении запроса и соответствующего ему ключа.
Заключение масштабированного скалярного произведения внимания
На самом деле делается две вещи:
- Создание таблицы поиска (внутренний продукт Q и K, масштабированный, softmax).
- Вычисление конечного результата путем взвешивания средневзвешенных строк в V на основе таблицы внимания.
Вы также можете думать о ключах и значениях как о своего рода базе данных, и внимание на самом деле заключается в нахождении подходящего вектора для представления каждого запроса на основе содержимого в базе данных.
В предыдущем объяснении Запрос и Ключ-Значение — это две разные последовательности, но на самом деле их ввод может быть одной и той же последовательностью, и в этом случае она называется Самостоятельным вниманием.
Самостоятельное внимание особенно полезно при обработке естественного языка, где выходные данные можно рассматривать как встраивание слов в каждый запрос с учетом контекста.
Пример
Наконец, для углубления вашего понимания приводится практический пример использования внимания.
Предположим, мы хотим преобразовать факультет компьютерных наук и факультет философии (два запроса) в векторы, понятные модели, и в базе данных есть четыре предмета (четыре пары ключ-значение): английский язык, социальные науки, математика, и физика. Таблица внимания, рассчитанная по модели, может выглядеть так:

Толкование следующее: для кафедры ХХ важность этих четырех предметов составляет…

Далее нам нужны значения V. Здесь я установил dᵥ = 3, где три значения в V представляют память, языковые способности и способность к логическому мышлению.
(Примечание: на самом деле мы не можем знать, что представляют собой столбцы Value, и модель сама узнает, что они должны представлять.)

Интерпретация следующая: для испытуемого XX оценки памяти, языка и логического мышления, необходимые для успешной работы, соответственно…
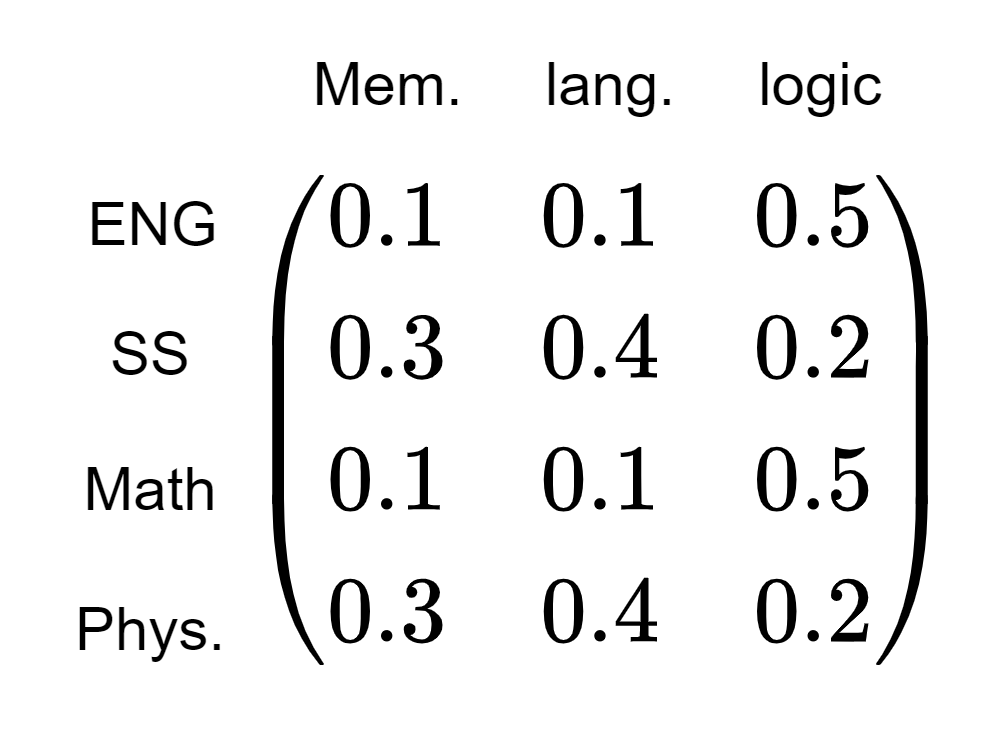
(Оценки являются чисто вымышленными.)
Умножение двух матриц:
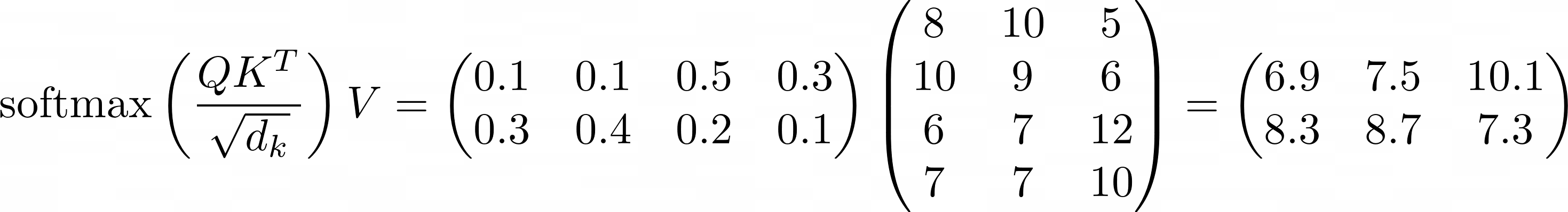
Окончательный результат выглядит следующим образом: показатели памяти, языка и логического мышления, необходимые для успешной сдачи XX отдела, соответственно…
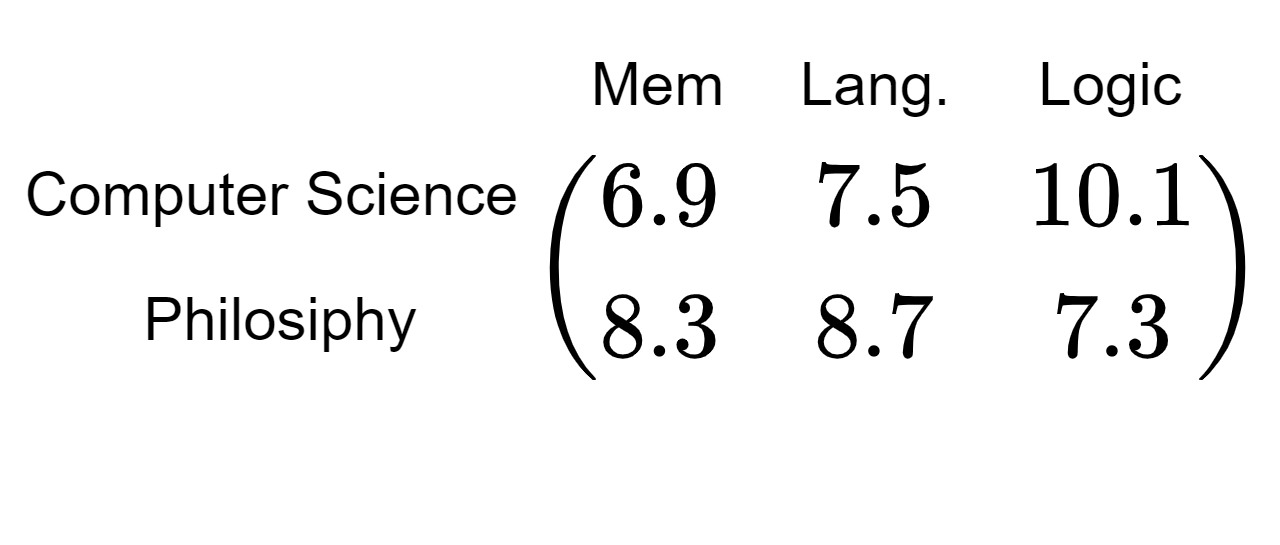
Модель также будет использовать два вектора, 6.9 7.5 10.1 и 8.3 8.7 7.3, для представления двух отделов соответственно.
Я надеюсь, что этот пример дал вам четкое представление о том, как работает внимание и как установить измерение внимания.
Заключение
В этой статье представлено подробное введение в детали вычислений и логику проектирования Scaled Dot-Product Attention, а также пример использования Attention.
Если мы внимательно сравним модель, представленную в предыдущей статье, мы обнаружим, что хотя две архитектуры выглядят очень по-разному, общая логика очень похожа.
Помимо внимания, архитектура Transformer включает в себя несколько других важных элементов, таких как структуры кодировщика и декодера, MultiHead и позиционное кодирование. Хотя эта статья не может подробно охватить эти аспекты, мы надеемся изучить их более подробно в будущих статьях.