
Intel® oneAPI Hackathon: веб-приложение для прогнозирования качества пресной воды.
Добро пожаловать в мой проект по машинному обучению! В этом репозитории я использовал Intel® Distribution of Modin для анализа и предварительной обработки набора данных, Intel® Optimization for XGBoost для создания модели классификации и daal4py из библиотеки Intel® oneAPI Data Analytics Library (oneDAL) для экспорта и выполнения. вывод по модели XGBoost.

Мотивация проекта
Прогноз качества пресной воды важен по нескольким причинам:
Здоровье человека: Качество пресной воды напрямую связано со здоровьем человека. Плохое качество воды может привести к распространению таких заболеваний, как холера и брюшной тиф, которые могут привести к летальному исходу.
Гигиена окружающей среды. Пресноводные экосистемы являются домом для разнообразных растений и животных и являются для людей жизненно важным источником пищи, воды и других ресурсов. Плохое качество воды может нанести вред этим экосистемам, что приведет к упадку или исчезновению видов.
Экономическое воздействие: пресная вода является важным ресурсом для многих отраслей, включая сельское хозяйство, производство и производство энергии. Плохое качество воды может привести к снижению производительности, увеличению затрат и даже закрытию предприятий.
Управление водными ресурсами: Понимание качества пресной воды необходимо для эффективного управления водными ресурсами. Прогнозирование качества воды может помочь лицам, принимающим решения, выявить потенциальные проблемы, принять меры по смягчению последствий и обеспечить устойчивое использование водных ресурсов.
Изменение климата. Изменение климата, вероятно, окажет значительное влияние на ресурсы пресной воды, в том числе на качество воды. Прогнозирование качества пресной воды может помочь нам понять, как изменение климата повлияет на эти ресурсы, и разработать стратегии адаптации к этим изменениям.
Таким образом, прогнозирование качества пресной воды имеет решающее значение для защиты здоровья человека и окружающей среды, поддержки экономического развития, управления водными ресурсами и адаптации к последствиям изменения климата.
Настройка среды
Перед запуском процесса обучения вам необходимо создать новую среду Python. Я рекомендую использовать Mamba для создания окружения.
$ mamba create -n oneapi -c intel daal4py xgboost modin-all scikit-learn scikit-learn-intelex mlflow optuna $ mamba activate oneapi
После того, как у вас есть среда conda, вам нужно загрузить CSV-файл набора данных и поместить его в легкодоступное место.
Исследовательский анализ данных
Процесс EDA выполняется в Jupyter Notebook, вам потребуется установить
notebookиipykernelв вашу среду!
В процессе EDA наша цель — выяснить, какие задачи предварительной обработки мы должны выполнить перед процессом моделирования, а также обобщить некоторые функции набора данных для создания простой информационной панели.
Для суммирования данных я в основном использовал метод resample для объединения окон, а затем сохранял его в файл JSON, чтобы его можно было загрузить позже из веб-приложения.
Предварительная обработка данных
Основываясь на собранной информации из процесса EDA, сама обработка данных не сложна, задействованы всего два процесса:
- Метка, кодирующая категориальные признаки (цвет, источник, месяц)
- Заполнить пустые значения
Вы можете узнать больше о предварительной обработке данных в preprocess.py о том, как сопоставить категориальные признаки с числами и о стратегии заполнения пропущенных значений.
Запуск тренировочного процесса
Перед запуском процесса обучения убедитесь, что у вас есть файл набора данных в формате CSV. Активируйте среду conda и cd в каталог challenge1, затем запустите скрипт train.py.
$ git clone --recurse-submodules https://github.com/fahminlb33/intel-oneapi-hackathon $ cd intel-oneapi-hackathon/challenge1 $ python train.py --model-format daal4py --dataset ./dataset/freshwater.csv --output ./models
Через некоторое время вы должны получить свою модель .pkl в каталоге models.
Оптимизация гиперпараметров
Поздравляем! Вы успешно создали свою первую модель классификации. Но имейте в виду, что эта модель может быть еще не лучшей с точки зрения точности классификации.
В этом разделе вы можете запустить другой скрипт, optimize.py, для оптимизации гиперпараметров базовой модели. Используя те же данные, этот скрипт попробует различные параметры модели XGBoost в надежде, что это повысит точность классификации и оценку F1. Вам понадобится optuna для запуска скрипта, а также mlflow для мониторинга производительности модели на каждой итерации.
$ mlflow ui # start the MLflow $ python optimize.py # open a new terminal and run this
По умолчанию этот скрипт будет выполняться 50 итераций и сохранит метрики в MLflow.
Теперь у вас есть лучшие параметры, сохраненные в MLflow, вы можете скопировать их в файл parameters.py, а затем снова запустить тренировку, используя train.py, но теперь с еще одним переключателем, --best-params. Это укажет сценарию использовать наилучшие параметры, определенные в файле parameters.py.
Этот сложный проект также поставляется с веб-приложением, поэтому вы можете легко использовать модель для прогнозирования новых данных, а также предоставляет простую панель мониторинга, чтобы показать некоторые ключевые идеи из набора данных.
Вам понадобится установленный Docker для запуска веб-приложения (технически вам это не нужно, но это значительно упрощает процесс).
Запуск веб-приложения
Самый простой способ, если использовать Docker. Клонируйте этот репозиторий, если еще не сделали этого.
$ git clone --recurse-submodules https://github.com/arpan-mondal/intel-oneapi-hackathon $ cd intel-oneapi-hackathon/challenge1/app_web $ docker build -t challenge1:latest . $ docker run --rm -it -p 8001:8001 challenge1:latest
После запуска команды docker run вы можете получить доступ к веб-приложению по адресу http://localhost:8001.
Делать прогнозы
Откройте веб-приложение по адресу http://localhost:8001, после чего вам будет представлена форма с множеством входных данных и кнопка для отображения сводки панели управления.

Вы можете использовать этот пример точки данных из набора данных для тестирования веб-приложения.
Дата: 11 апреля 2023 г., 04:00

После того, как вы заполнили форму, нажмите Запустить прогноз.
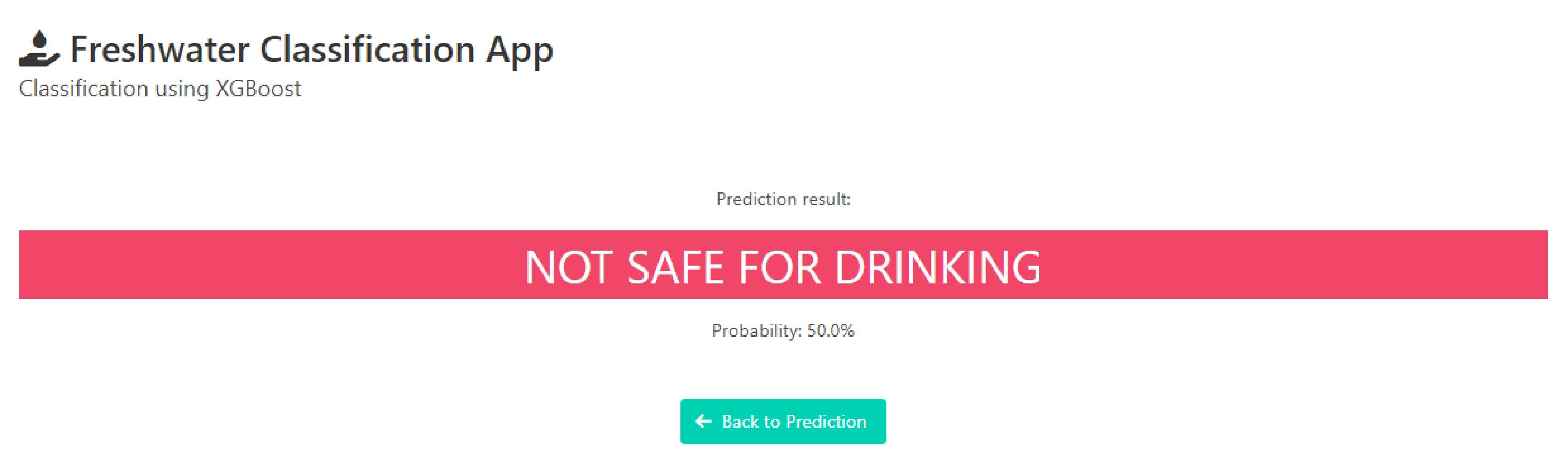
Прогноз будет показан на следующей странице, безопасно ли это для питья. Вероятность также будет показана под результатом прогноза.
Панель приборов
Панель инструментов показывает нам некоторые полезные ключевые идеи из набора данных. Я использовал библиотеку ApexCharts для отображения диаграмм, а источником данных являются файлы JSON, обработанные с помощью Pandas Modin.
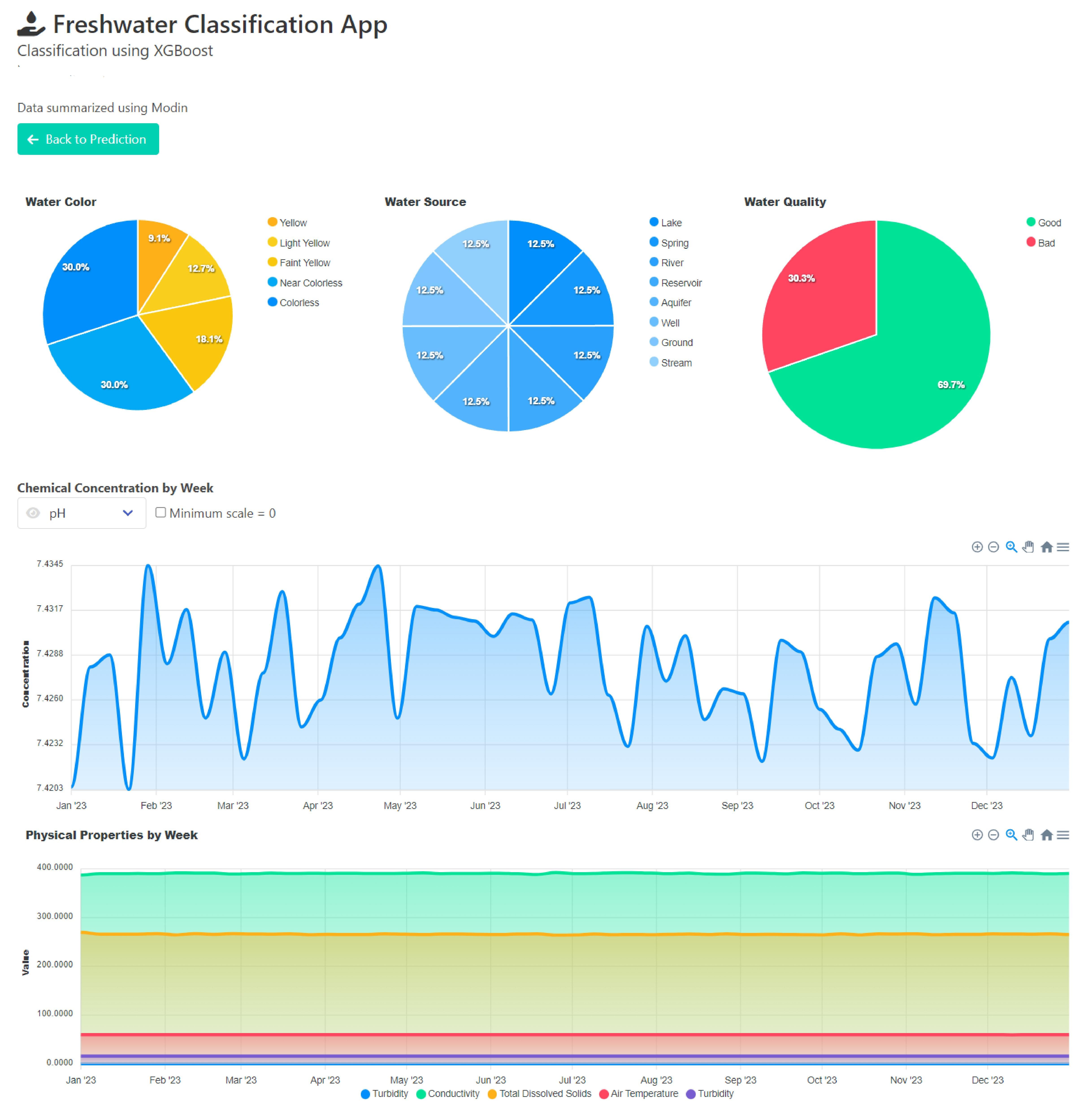
Здесь вы можете увидеть некоторые диаграммы, такие как цвет воды, источник и процент качества, а также диаграмму временных рядов химических и физических свойств воды. Вы можете выбрать, какое химическое вещество отображать, используя раскрывающийся список, и вы можете установить масштаб оси Y от автоматического до 0, используя флажок.
Использование API
Я также предоставляю простой в использовании API для запуска ваших собственных прогнозов с использованием REST API.
Для каждого прогноза вам понадобится уникальный ключ объекта в качестве идентификатора, и каждое значение объекта должно быть массивом каждой функции. Результатом будет та же схема, но теперь массив представляет собой вероятность классификации ровно с двумя элементами ([probability of the good class, probability of the bad class]).
Примечание:
- Все категориальные признаки должны быть закодированы как число. См.
paramters.pyдля получения более подробной информации. - Порядок столбцов функций такой же, как в приведенном выше примере.
Использование почтальона:

Использование CURL:
$ curl --location 'http://localhost:8001/predict' \
--header 'Content-Type: application/json' \
--data '{
"single": [
7.258203145845717,
6.107129837217062e-09,
9.26167580122401,
182.2423407530417,
4.3998520479124295e-224,
0.4164775464847408,
2,
0.0478031791644083,
1.0161962374839366,
0.2980934209430296,
3.1441986515867457,
114.55142662349748,
160.06255735415195,
2.3250939237169903,
6.020679600903066e-16,
214.5531038247008,
1,
15.891904856714174,
61.13914033047329,
1,
11.0,
4.0
]
}'
{
"single": [
0.5000045723839148,
0.4999954276160851
]
}
Из приведенного выше ответа мы можем сделать вывод, что прогнозируемый класс равен 0 (хорошо), потому что первый элемент результата выше, чем второй класс (>0,5). Вы можете использовать numpy.argmax, чтобы получить результат классификации в двоичном формате.
Нагрузочные тесты
Тест выполняется с помощью load_test/test_challenge1.js на том же ПК, на котором работает сервер. Это не идеально, но его можно использовать для приблизительной оценки общей пропускной способности API. Тест выполняется с использованием К6 с 20 ВУ в течение одной минуты.

В среднем 2,61 мс на вывод — это отлично! Это приложение, безусловно, будет хорошо масштабироваться для использования в производственной среде.