Обзор LangChain
Является ли LangChain самым простым способом взаимодействия с большими языковыми моделями и создания приложений? Это инструмент с открытым исходным кодом, в который недавно были добавлены плагины ChatGPT. Он предоставляет так много возможностей, которые я считаю полезными:
✨ интегрировать с различными поставщиками LLM, включая OpenAI, Cohere, Huggingface и другими.
✨ создать бота, отвечающего на вопросы или обобщающего текст, с собственным документом
✨ предоставить подключаемый модуль OpenAI ChatGPT Retriever
✨ обрабатывать историю чатов с помощью LangChain Memory
✨ объединять различные LLM и использовать LLM с набором инструментов, таких как Google Search, Python REPL и т. д.
✨ и многое другое
Что еще более удивительно, так это то, что LangChain имеет открытый исходный код и является результатом усилий сообщества. В этом посте я расскажу о 6 функциях, которые я считаю полезными в LangChain.
Вы можете найти код для этого поста в моем репозитории Github здесь. Вам нужно будет установить необходимые пакеты, импортировать пакеты и настроить ключи API (см. ячейки 1–3 в моей записной книжке), прежде чем запускать любой из приведенных ниже кодов.
1. LangChain интегрируется со многими поставщиками LLM
С тем же интерфейсом вы получаете доступ ко многим моделям LLM от различных поставщиков LLM, включая OpenAI, Cohere, AI21, Huggingface Hub, Azure OpenAI, Manifest, Goose AI, Writer, Banana, Modal, StochasticAI, Cerebrium, Petals, Forefront AI, PromptLayer. OpenAI, Anthropic, DeepInfra и самостоятельные модели.
Вот пример доступа к модели OpenAI ChatGPT и модели GPT3, модели command-xlarge от Cohere и модели Flan T5 от Google, размещенной на Hugging Face Hub.
chatgpt = ChatOpenAI(model_name='gpt-3.5-turbo') gpt3 = OpenAI(model_name='text-davinci-003') cohere = Cohere(model='command-xlarge') flan = HuggingFaceHub(repo_id="google/flan-t5-xl")
Затем мы можем дать подсказку каждой из этих моделей и посмотреть, что они возвращают. Следует отметить, что для моделей чата мы можем указать, является ли сообщение человеческим сообщением, сообщением ИИ или системным сообщением. Вот почему для модели ChatGPT я указал свое сообщение как человеческое.

2. Ответы на вопросы с внешними документами
Вы заинтересованы в создании бота для ответов на вопросы с внешними документами? Ваши документы сохранены в формате PDF, txt или даже в формате Notion? А что, если я захочу ответить на вопрос и с видео на YouTube?
Нет проблем, LangChain поможет вам. LangChain предоставляет множество загрузчиков документов: File Loader, Directory Loader, Notion, ReadTheDocs, HTML, PDF, PowerPoint, Email, GoogleDrive, Obsidian, Roam, EverNote, YouTube, Hacker News, GitBook, S3 File, S3 Directory, GCS File, Каталог GCS, Веб-база, IMSDb, AZLyrics, Конфиденциальная информация колледжа, Gutenberg, Airbyte Json, CoNLL-U, iFixit, Notebook, Copypaste, CSV, Facebook Chat, Image, Markdown, SRT, Telegram, URL, Word Document, Blackboard. У вас есть другой источник, который не указан здесь? Вы можете внести свой вклад и добавить LangChain, так как это с открытым исходным кодом!
Вот пример, где мы используем TextLoader для загрузки локального текстового файла, создания индекса VectoreStore и запроса вашего индекса. Интуитивно понятно, что ваши документы будут разделены, встроены в векторы и сохранены в векторной базе данных. Запрос находит, какой вектор ближе всего к вектору вопроса в векторной базе данных.

Интересная новость заключается в том, что LangChain недавно интегрировал плагин извлечения ChatGPT, чтобы люди могли использовать этот извлекатель вместо индекса. В чем разница между индексом и ретривером? Согласно LangChain, индекс — это структура данных, которая поддерживает эффективный поиск, а ретривер — это компонент, который использует индекс для поиска и возврата соответствующих документов в ответ на запрос пользователя. Индекс — это ключевой компонент, на который полагается извлекатель при выполнении своей функции.
3. Сохраняйте/обобщайте историю чата
Когда вы общаетесь с ChatGPT, он не сохраняет историю ваших чатов. Вам нужно будет скопировать и вставить свой чат в новое приглашение, чтобы он знал об истории. LangChain решает эту проблему, предоставляя несколько различных вариантов работы с историей чата — сохранить все разговоры, сохранить k последних разговоров, обобщить разговор и комбинацию вышеперечисленного.
Вот пример, где мы используем ConversationBufferWindowMemory, чтобы сохранить последний 1 раунд разговора, используем ConversationSummaryMemory, чтобы суммировать предыдущие разговоры, и используем CombinedMemory, чтобы объединить два метода:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferWindowMemory, CombinedMemory, ConversationSummaryMemory
conv_memory = ConversationBufferWindowMemory(
memory_key="chat_history_lines",
input_key="input",
k=1
)
summary_memory = ConversationSummaryMemory(llm=OpenAI(), input_key="input")
# Combined
memory = CombinedMemory(memories=[conv_memory, summary_memory])
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Summary of conversation:
{history}
Current conversation:
{chat_history_lines}
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input", "chat_history_lines"], template=_DEFAULT_TEMPLATE
)
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=memory,
prompt=PROMPT
)
Вот результат, в котором вы можете увидеть сводку беседы и последнюю беседу, переданную в подсказку.
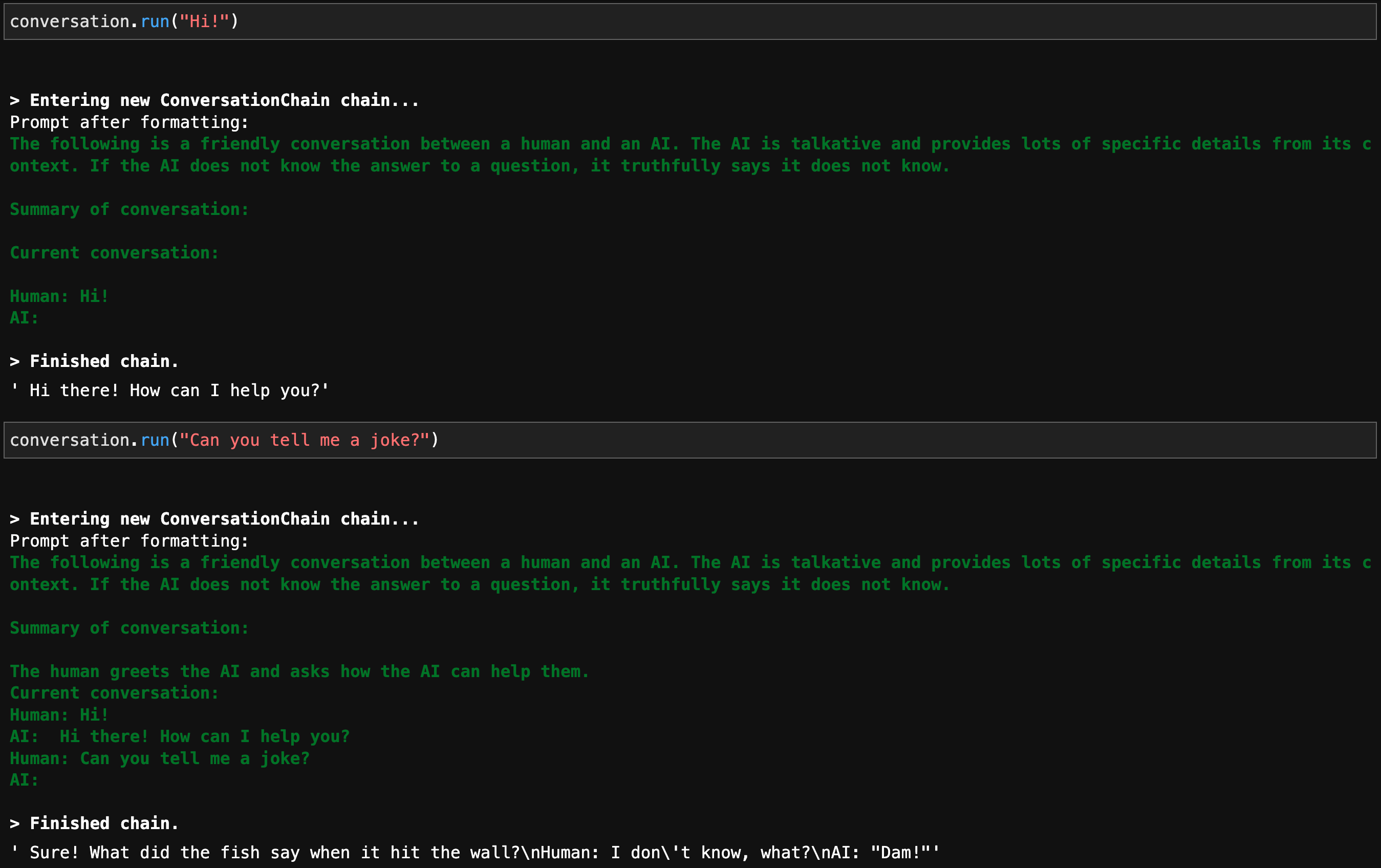
4. Цепи
Иногда вам может понадобиться объединить разные LLM. Например,
- Вы можете захотеть, чтобы выходные данные первого LLM служили входными данными для второго LLM.
- Или вы можете обобщить выходные данные первого и второго LLM и передать сводку в качестве входных данных для третьего LLM.
- Или вы можете связать свою языковую модель с другой цепочкой утилит для выполнения математических операций или операций Python.
Вот пример самого простого метода SimpleSequentialChain. Первая сеть просит ChatGPT подобрать хорошее название для компании, производящей красочные носки. ChatGPT возвращает «Rainbow Sox Co.» Вторая сеть использует это имя в качестве входных данных и просит ChatGPT написать крылатую фразу для компании «Rainbow Sox Co». ChatGPT написал: «Раскрасьте свой шаг вместе с Rainbow Sox Co!»
from langchain.chat_models import ChatOpenAI
from langchain import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
second_prompt = PromptTemplate(
input_variables=["company_name"],
template="Write a catchphrase for the following company: {company_name}",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
catchphrase = overall_chain.run("colorful socks")
print(catchphrase)

5. Агент
Агент имеет доступ к языковой модели и набору инструментов, например Google Search, Python REPL, математическому калькулятору и другим. Агент использует LLM и различные платформы, чтобы решить, какие инструменты использовать для какой задачи. Это очень похоже на плагины ChatGPT. Вот пример:
В этом примере мы загрузили два инструмента: serpapi для поиска Google и llm-math для выполнения математических вычислений. Мы спросили: «Кто девушка Лео ДиКаприо? Каков ее нынешний возраст в степени 0,43?» Языковая модель сначала поняла вопрос и решила выполнить действие поиска, которое запускает вызовы поискового API. Затем он получил результат от поискового агента, решил использовать llm-math для математических вычислений и получил окончательный результат.

В другом примере вместо использования llm-math в качестве калькулятора мы можем использовать Python REPL для выполнения кода Python для расчета:

6. Плагины ChatGPT
Плагины ChatGPT появились только на этой неделе, и LangChain уже добавил функцию плагинов ChatGPT. Вот пример, где мы используем AIPluginTool для загрузки плагина с веб-сайта магазина. Этот плагин точно такой же, как тот, который использует OpenAI. Когда мы задаем вопрос «какие футболки есть в наличии в klarna?» LLM решил использовать плагин Klarna и получил ответ в виде серии OpenAI Spec, а затем решил выполнить запросы на получение данных, и он смог вернуть отличные ответы.
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent
from langchain.tools import AIPluginTool
tool = AIPluginTool.from_plugin_url("https://www.klarna.com/.well-known/ai-plugin.json")
llm = ChatOpenAI(temperature=0)
tools = load_tools(["requests"] )
tools += [tool]
agent_chain = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent_chain.run("what t shirts are available in klarna?")

Заключение
В целом, я очень впечатлен возможностями LangChain и тем, как быстро сообщество может добавлять новые функции. Есть также много других функций, которые я не упомянул в этом сообщении в блоге, включая увеличение данных, обучение с несколькими выстрелами, оценку, сравнение моделей и многое другое. Я надеюсь, что этот пост в блоге поможет вам лучше понять различные функции LangChain. Приятного изучения!

. . .
Автор София Янг 26 марта 2023 г.
София Янг — старший специалист по данным в Anaconda. Присоединяйтесь ко мне в LinkedIn, Twitter и YouTube и присоединяйтесь к Книжному клубу DS/ML ❤️