
«Ученый по обработке данных — это тот, кто разбирается в статистике лучше любого инженера-программиста и лучше любого специалиста в области статистики».
- «АНАЛИТИК ДАННЫХ» смотрит на «прошлые данные» и «что происходит, когда происходит».
- DA ПРЕДОСТАВЛЯЕТ «СВОДКУ» ДАННЫХ.
«УЧЕНЫЕ ПО ДАННЫМ» ПРЕДОСТАВЛЯЮТ «ПРОГНОЗЫ» В ОТНОШЕНИИ «ДАННЫХ» И СОЗДАЮТ ЛУЧШУЮ МОДЕЛЬ ДЛЯ ДАННЫХ.
Проблемы в ML: -
Десять важных моментов, которые нужно знать при выполнении машинного обучения:
- 1 DATA COLLECTION - 2 INSUFFICIENT DATA - 3 NON REPRESENTATIVE DATA - 4 POOR QUALITY DATA - 5 IRREVELANT FEATURES - 6 OVERFITTING - 7 UNDERFITTING - 8 SOFTWARE INTEGRATION - 9 OFFLINE LEARNING/DEPLOYMENT - 10 COST INVOLVED
1- Сбор данных
Два способа сбора данных -
- API
- ВЕБ-ЧИСТКА
2- Недостаточно данных / помеченных данных
Больше данных имеет значение в любом случае, например, если вы создали две модели, одну с меньшим количеством данных, и модель работала хорошо, а вторая модель была создана с большими данными, где модель не дала хороших результатов по сравнению с первой моделью, но поскольку данные были там больше, чем первая, поэтому выберет вторая модель.
- Но в реальной жизни сбор размеченных данных — большая проблема. например, вам нужно создать модель классификации изображений, для этого вы можете выбирать данные путем веб-скраппинга, но маркировка переменных является большой задачей, поскольку маркировка готовых данных очень мала.
3- Нерепрезентативные данные
когда у вас есть нерепрезентативные данные, это означает, что вы собираетесь решить мою проблему, но ваши данные наполовину. например, вы проводите опрос, какая политическая партия побеждает, и вы собираете данные не по всей Индии, а из некоторых мест, где люди предвзято относятся к одной партии, которая называется (шум выборки), это необъективные данные, и ваша модель не даст надлежащего Результаты.
4 — Данные низкого качества
Неформатированные данные, резкие данные, выбросы и пропущенные значения — все это, когда у нас есть данные, мы можем сказать, что это данные низкого качества.
5- Нерелевантные функции
Признаки означают — COLUMN Столбец, который не способствует нахождению каких-либо значений. Например, «МУСОР В МУСОР» — допустим, вы организуете беговой марафон, пригласили людей для участия и собираете некоторые данные на основе (роста, веса, возраста и местоположения) — это переменные, которые вы собрали, и теперь вы можете думать о местоположении. переменная не дает никакого результата о том, кто может пробежать марафон или нет. так что местоположение не имеет значения.
- также иногда вы комбинируете две переменные и создаете одну новую переменную, поскольку обе функции в конечном итоге говорят одно и то же. например, рост, вес, поэтому вы создали новую переменную «ИМТ», которая по-прежнему дает то же значение для данных.
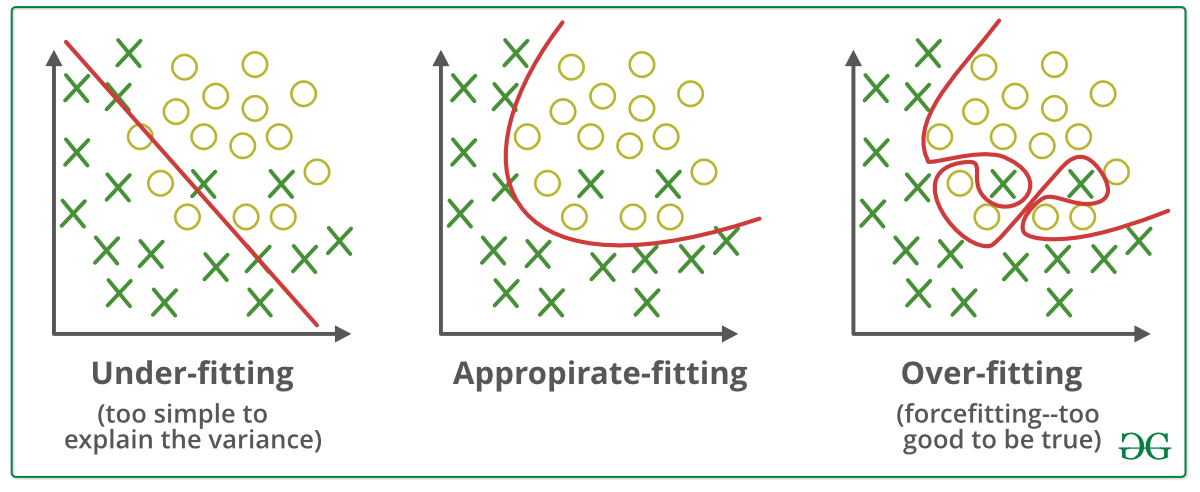
6 — Переоснащение
вы обучили модель ML, и ваша модель только что изучила все данные, когда вы вводите новые данные в модель, она не работает должным образом, это называется переоснащением. бывший — я поехал в Европу и пошел за покупками в один магазин и обнаружил, что цена очень высока, поэтому я решил и дал отзыв, что Европа очень дорогая, что неправильно, основываясь на одном мнении. это переоснащение.
7 — Недооснащение
Противоположность переоснащению
8 — Интеграция программного обеспечения
- в конце, когда вы будете работать над моей моделью, она будет решать проблемы пользователей, работая как программная часть.
- поэтому, когда вы создали мл после создания модели, следующая работа — вам нужно поместить вашу модель в программное обеспечение.
- поэтому интеграция моделей машинного обучения в программное обеспечение — сложная задача. бывший. в java это было очень сложно. тензор в порядке.
- Одна модель машинного обучения не будет хорошо работать на каждой платформе. поэтому вам следует проверить свою модель, преобразовав ее в веб-сайт и преобразовав в приложение для Android. на данный момент это сложная работа по запуску модели в программном обеспечении.
9 — Пакетное обучение / автономное обучение
В пакетном/автономном режиме модель обучения не обновляется онлайн.
10 — Затраченные затраты
Когда вы развертываете модель ежедневно и более 10 000 пользователей ежедневно используют вашу модель и обновляют вашу модель на сервере, это требует огромных затрат. Так что не создавайте безосновательную модель
- После создания модели правильно разверните ее на сервере и отправьте пользователю для проверки работы вашей модели. этот процесс подпадает под ML OPS. который работает на серверах, где развертывается модель обновления модели, запускается модель и проверяется на основе использования пользователем.
ПРИМЕНЕНИЕ ОД
Есть так много примеров, когда ML используется. Я сосредоточусь на 5 примерах: -
1- Retail (Amazon / Big bazar) 2 - Banking and Finance 3- Transport - OLA 4 - Manufacturing - Tesla 5- COnsumer Internet - Twitter
1- Розничная торговля (Amazon/Большой базар)
Розничная торговля — большой рынок для Ml. например, использование амазонки мл. Каждый год у амазонки большие продажи в Индии, которые происходят за счет увеличения продаж, и если у вас есть продукт на 6 лакхов, то как вы узнаете, какой запас продукта необходим для увеличения запасов, весь продукт имеет очень огромную стоимость. поэтому специалисты по данным «используют все прошлые данные о продажах, изучают поведение данных и приходят к выводу, какие данные о продуктах мы можем увеличить.
- Вы думали, почему большой базар или любой другой магазин запрашивает все ваши личные данные перед покупкой чего-либо? потому что они анализируют на основе вашего покупательского поведения и создают ваш профиль, и на основе вашего интереса ваш номер предоставляется той же компании, поэтому вы получаете случайный звонок, электронное письмо или сообщение, не проверяя их страницу. ex — вы покупаете продукты для фитнеса в основном, поэтому, основываясь на вашем поведении, большой базар или amazon дали ваш номер любому тренажерному залу или фитнес-компании. для фитнес-компаний это очень качественные данные по сравнению с отправкой и сбором данных по электронной почте.
- Вам было любопытно, как каждый товар распределяется в любом магазине, таком как Walmart, большой базар, больше, магазины Reliance и т. Д. Все это делается путем изучения данных, какой товар может сочетаться с каким товаром для увеличения продаж с помощью «ОБУЧЕНИЕ НА ОСНОВЕ СООТВЕТСТВУЮЩИХ ПРАВИЛ », который является моделью ML, также путем нахождения корреляций между двумя элементами.
2 — Банковское дело и финансы
В банковском деле используется очень высокая базовая модель ML для многих вещей:
- 1- одобрение кредита клиенту путем сравнения поведения клиентов
- 2- выделение кредитной карты на основе проверки поведения клиентов
- 3- где можно открыть новую ветку
- 4- какой сегмент клиент может предложить продукты.
3- Транспорт — OLA
- Вы когда-нибудь задумывались, почему цена ola зависит от времени, например, ранним утром или поздней ночью цена удваивается? потому что есть приложение, которое используется водителями ola или uber, которое разделено на красные и зеленые области, которые показывают, где клиент находится высоко, а такси низко, поэтому uber, ola предлагает водителям такси двойную плату за поездку в это место и выбрать клиента. и эти деньги платит клиент, поэтому цены выше в определенное время. эта зона поиска определяется поведением клиентов с использованием модели мл.
- Swiggy отправляет 3 заказа вместе, что делается только путем анализа расстояния клиента на основе мл.
- поэтому в логистике мл обеспечивает лучшее решение.
4 — Производство — Тесла
ML также широко используется в производстве, поскольку бывшая TESLA использует автоматизацию в производстве.
- Как Тесла может узнать, какая часть машины не работает? Таким образом, в тот же день автомобиль не будет создан, поскольку Tesla уже предоставляет продукт покупателю на основе даты, поэтому, если производство останавливается даже на один день, продажи продукта также увеличиваются в день, что плохо для имиджа названия продукта. поэтому tesla использует «интернет-датчик» «IOT» на своей производственной машине, который проверяет постоянные характеристики машины, такие как температура, скорость вращения и давление. если какое-либо устройство выходит из строя, поэтому, если возникает какой-либо сигнал, эта конкретная машина проверяется, прежде чем она выйдет из строя. этот процесс называется «прогнозирование технического обслуживания».

5- Потребительский Интернет — Твиттер
Twitter — одна из тех компаний, которая очень старая, но не прибыльная по сравнению с Facebook, LinkedIn, YouTube и Twitter, не имеющая активного источника дохода. Глава Twitter решил использовать твиты и проводить анализ настроений в твитах и использовать этот план для заработка.
- Анализ настроений означает проверку настроений с помощью слов и проверку того, дает ли пользователь положительные или отрицательные отзывы, выбирая слова из отрицательных и положительных слов.
- поэтому Twitter использовал анализ настроений и зарабатывал деньги.
- во время выборов люди делают много твитов, а также используют хэштеги, поэтому Twitter собирает все твиты, собирая хэштеги и анализируя опросы, положительные для какого лидера или отрицательные для какого лидера, так что это очень реальные данные, и люди настоящие, и они давая ответ, основанный на их собственной оригинальной личности и основе взгляда на мыслительный процесс. и Twitter анализирует эти данные, поэтому эти данные могут быть проданы Twitter биржевым брокерам, таким как Morgan Stanley, JPMorgan и т. д., которые помогают этой биржевой брокерской компании вкладывать деньги в те компании, которые поддерживают ведущую партию. поэтому, когда партия побеждает, и акции компании, поддерживающей партию, увеличиваются. и компания становится надежной для предоставления более правильных прогнозов. поэтому эти компании отдают Twitter процент прибыли, полученной в результате их анализа настроений по данным. Таким образом, машинное обучение помогает потребительским интернет-компаниям.

MLDLC («Жизненный цикл разработки машинного заработка»)
КАК ML Do обрабатывает данные —
- 1- Сформулируйте проблему
- 2- Сбор данных
- 3- Предварительная обработка данных
- 4- Исследовательский анализ данных
- 5- Разработка и выбор функций
- 6- Оценка обучения модели
- 7- Развертывание модели
- 8- Тестирование
- 9 — оптимизировать
1- Сформулируйте проблему
Если вам нужно создать модель, вы должны подумать о нескольких вещах, прежде чем начинать модель - подумайте обо всех проблемах.
- Сколько ни один сотрудник не будет работать
- Модель находится под присмотром или без присмотра
- Сколько затрат это займет
- Модель пакетного обучения или онлайн-модель
- Какой алгоритм поможет
- Где вы собираете данные после того, как сделаете все, что мы думаем для второго шага.
2- Сбор данных
В конкретных компаниях, где сбор данных затруднен:
- через API мы можем собирать данные, используя некоторый код Python
- Веб-скраппинг данных с веб-сайтов компаний extrivago дает данные об отелях
- Хранилище данных создает (ETL) и извлекает данные отсюда через кластер.
3- Предварительная обработка данных
Данные обычно имеют нечистую структуру, зашумленные данные, выбросы, количество мест, откуда поступают данные.
- здесь мы должны удалить «дубликаты», удалить «отсутствующие значения», удалить «выбросы» и «значения масштабирования» для выравнивания параметров данных, выполняя «стандартизацию».
4- Исследовательский анализ данных
EDA делают для анализа данных. найти взаимосвязь между «входными» и «выходными» данными, проведя множество экспериментов с визуализацией данных, «одномерный анализ» означает, как работают отдельные переменные (среднее значение, sd, какая кривая следует)
- «Двусторонний анализ» — это то, как две переменные работают вместе.
- «многофакторный анализ» проверка производительности с несколькими переменными.
- «Обнаружение выбросов» выполняется в процессе EDA.
5- Разработка и выбор функций
- Эта функция означает «ВХОДНАЯ колонка».
- выходной столбец зависит от входного столбца.
- мы также создаем новый столбец на основе сходства двух переменных и удаляем старый.
- мы также можем вносить изменения в текущие функции в зависимости от характера необходимой работы.
- ненужные функции можно удалить, что бесполезно для поиска результатов.
6- Оценка обучения модели
- После того, как все данные очищены и все функции созданы, вы выбираете разные «АЛгоритмы» для «ДАННЫХ», чтобы проверить, какой из них лучше всего работает с данными.
- В процессе оценки мы используем «матрицу эффективности», которая различается в зависимости от алгоритма.
- оценка модели помогает узнать, какую модель можно выбрать.
- затем выберите модель и выполните наилучшую настройку гиперпараметров модели, чтобы ее функции работали хорошо.
- Иногда методы ансамбля объединяют несколько моделей, чтобы получить хорошую модель.
- так что в конце у вас есть очень мощная модель, которая хороша для «предсказания».
7- Развертывание модели
- Теперь, после создания модели, вам нужно развернуть эту модель для конечного пользователя. для развертывания модели необходимо преобразовать ее в «Программное обеспечение».
- из «модели» мы делаем «бинарный файл» с помощью «pickle» или других «инструментов» и конвертируем его в «API»
. «API» дает ответ в формате «JSON».
. и этот ответ в формате JSON показал пользователю.
. этот процесс называется развертыванием модели.
- для развертывания мы используем такие серверы, как — «herikoo», «AWS», «GCP», «А AZURE».
- на сервере в масштабе вы запускаете модель, выполняете резервное копирование модели, резервное копирование данных, настройку автоматизации и решаете, как часто следует переобучать модель, чтобы избежать «загнивания» модели.
8- Тестирование
затем вы проводите бета-тестирование, например, «A/B-тестирование» на некоторых доверенных пользователях, чтобы сначала проверить, как работает модель. если у него есть какие-то проблемы, вы снова выполняете процесс MLDLC, чтобы реформировать модель.
9- Оптимизировать
- на сервере в масштабе вы запускаете модель, выполняете резервное копирование модели, резервное копирование данных, настройку автоматизации и решаете, как часто следует переобучать модель, чтобы избежать «загнивания» модели.
- время автоматизации решит, еженедельно, ежемесячно и ежечасно обучаемая модель.