Метрики и оценка в машинном обучении, включая разницу между регрессионными и классификационными метриками. Он также вводит понятие функций потерь, которые измеряют производительность или ошибку прогнозов модели и могут использоваться для обучения на основе градиента. В то время как функции потерь оптимизированы для градиентного спуска, метрики отдают приоритет обеспечению интуитивного понимания эффективности модели.
Проще говоря, хотя функции потерь и метрики имеют схожие функции, это разные инструменты. Некоторые показатели нельзя использовать в качестве функций потерь, поскольку они недифференцируемы. В то время как некоторые функции потерь могут быть легко поняты людьми, метрики отдают предпочтение интуитивному объяснению производительности модели, в то время как функции потерь предназначены для оптимизации градиентного спуска.
Средняя абсолютная ошибка
Средняя абсолютная ошибка (MAE) — это широко используемый показатель регрессии, который измеряет среднюю разницу между предсказанными значениями модели и истинными значениями данных, на которых она обучалась. Он позволяет оценить, насколько точны прогнозы модели, принимая во внимание абсолютные различия между прогнозируемыми и истинными значениями.

import numpy as np
def mean_absolute_error(y_true, y_pred):
assert y_pred.shape == y_true.shape
return np.sum(np.absolute(y_true - y_pred)) / len(y_pred)
Представьте себе класс из 30 студентов, сдающих экзамен, который оценивается по 100 баллам. Учитель предсказал экзаменационные баллы для каждого ученика на основе их прошлой успеваемости в классе. Однако, когда были возвращены фактические экзаменационные баллы, учитель понял, что их прогнозы были неточными.
Чтобы оценить точность своих прогнозов, учитель рассчитал разницу между их прогнозируемой оценкой и фактической оценкой каждого ученика. Однако, поскольку они хотели получить более общее представление о том, насколько ошибочны их прогнозы в целом, они решили взять среднее значение всех различий между предсказанными и фактическими оценками. Это называется средней абсолютной ошибкой, и оно дает единственное значение, представляющее среднюю разницу между прогнозируемыми и фактическими оценками для всех учащихся в классе.
Этот метод прост и понятен, говоря нам о средней разнице между метками и предсказаниями модели. Однакоодна изсерьезных проблем заключается в том, что MAE не учитывает прогнозы с выбросами. Итак, проблема с MAE заключается в том, что он обрабатывает все ошибки прогнозирования одинаково, независимо от их величины. Это может быть проблемой, потому что большая ошибка прогноза может иметь гораздо большее влияние на полезность модели, чем небольшая ошибка. Например, модель, которая отличается на 50–55 % или более, вероятно, не очень полезна, в то время как модель, которая отличается всего на 1–6 %, все еще может считаться достаточно точной.
реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import mean_absolute_error mean_absolute_error(y_true, y_pred)
Среднеквадратическая ошибка
Как следует из названия, среднеквадратическая ошибка возводит разницу между предсказаниями модели и меткой достоверности во вторую степень вместо того, чтобы принимать абсолютное значение. Среднеквадратическая ошибка (MSE):

Однако у нас нет интуиции, насколько именно модель неверна. Поскольку мы возвели результат в квадрат, а не брали абсолютное значение, получаемая нами оценка не масштабируется до диапазона результатов теста, например, средняя ошибка 127,8 невозможна для теста, который набрал от 0 до 100 баллов.
import numpy as np
def mean_squared_error(y_true, y_pred):
assert y_pred.shape == y_true.shape
return np.sum((y_true - y_pred) ** 2) / len(y_pred)
Чтобы противостоять такой проблеме, мы можем взять квадратный корень из результата, чтобы «обратить» операцию возведения во вторую степень, поместив ошибку в контекстную шкалу, но при этом подчеркнув любые прогнозы с выбросами. Этот показатель представляет собой среднеквадратичную ошибку (RMSE):

import numpy as np
def root_mean_squared_error(y_true, y_pred):
assert y_pred.shape == y_true.shape
return mean_squared_error(y_true, y_pred) ** 0.5
Реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import mean_squared_error mean_squared_error(y_reg_true, y_reg_pred) mean_squared_error(y_reg_true, y_reg_pred) ** 0.5
MAE, MSE и RMSE являются одними из наиболее важных для задач регрессии.
Матрица путаницы
Подобно метрикам регрессии, использующим концепцию MAE, многие метрики классификации используют матрицу путаницы для оценки производительности модели. Матрица путаницы обеспечивает полезную визуализацию, которая показывает, сколько ошибок сделано и какой тип ошибки возникает в задаче классификации. Используя матрицу путаницы, мы можем лучше понять производительность модели классификации и определить любые конкретные области, в которых модель может нуждаться в улучшении.
Матрица путаницы — это инструмент, используемый для оценки производительности модели путем сравнения ее прогнозов с фактическими метками. Он состоит из четырех компонентов: истинно положительные, ложноположительные, истинно отрицательные и ложноотрицательные. Каждый компонент описывается двумя словами. Первое слово указывает, был ли прогноз модели правильным или неправильным (это «истина», если прогноз верен, и «ложь», если он неверен). Второе слово относится к фактической метке или базовой истине («положительно» для метки 1 и «отрицательно» для метки 0).
- Когда прогноз модели равен 1, а основная правда равна 1, это действительно положительный результат.
- Когда прогноз модели равен 1, а основная правда равна 0, это ложное срабатывание.
- Когда прогноз модели равен 0, а истинное значение равно 0, это действительно отрицательный результат.
- Когда предсказание модели равно 0, а истинное значение равно 1, это ложноотрицательный результат.

Точность
Одним из простейших методов оценки эффективности модели классификации является расчет ее точности. Точность измеряет процент значений, правильно предсказанных моделью. С технической точки зрения точность рассчитывается путем деления суммы истинных положительных и истинных отрицательных значений на общее количество значений прогноза.
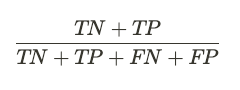
Точность — популярная метрика для оценки моделей классификации, потому что ее легко понять и рассчитать. Однако точность имеет недостаток при работе с несбалансированными данными. Несбалансированные данные — это когда выборок одного класса значительно больше, чем другого. В таких случаях точность может ввести в заблуждение, поскольку она не учитывает дисбаланс в данных.
import numpy as np
def accuracy(y_true, y_pred):
assert y_true.shape == y_pred.shape
return np.average(y_true == y_pred)
Например, если есть 100 выборок, из которых 90 относятся к положительному классу и 10 к отрицательному классу, модель, которая просто предсказывает все выборки как положительные, достигнет точности 90%, даже если это не очень хорошая модель. С другой стороны, хорошо разработанная модель, которая правильно предсказывает 81 из 90 положительных образцов и 9 из 10 отрицательных образцов, намного лучше. Следовательно, точность сама по себе не является достаточным показателем для оценки моделей классификации при работе с несбалансированными данными.
реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import accuracy_score accuracy_score(y_class_true, y_class_pred)
Точность
Точность — это метрика, учитывающая проблему несбалансированных классов в данных. Он измеряет точность положительных прогнозов, сделанных моделью, путем расчета отношения истинных срабатываний к сумме истинных срабатываний и ложных срабатываний. Точность полезна для наказания моделей, которые плохо работают с положительным классом в несбалансированных наборах данных и имеют большое количество отрицательных значений.

import numpy as np
def precision(y_true, y_pred):
assert y_true.shape == y_pred.shape
return ((y_pred == 1) & (y_true == 1)).sum() / y_pred.sum()
Это особенно полезно в наборах данных, где количество отрицательных образцов значительно превышает количество положительных образцов, например, при диагностике заболеваний. Точность дает осмысленное представление о том, насколько точна модель при прогнозировании редкого положительного класса.
реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import precision_score precision_score(y_class_pred, y_class_pred)
Отзывать
Отзыв — это показатель, который фокусируется на правильности прогнозов положительного класса, сделанных моделью. Он измеряет процент истинно положительных результатов (правильно спрогнозированных положительных образцов) по всем положительным меткам. Отзыв особенно полезен в сценариях, где положительный класс встречается редко или имеет решающее значение для точного прогнозирования, например, при медицинской диагностике, когда ложноотрицательные результаты (неспособность идентифицировать заболевание) могут быть опасными для жизни. В этих случаях оптимизация для высокой полноты имеет решающее значение, даже если это означает принятие более высокого уровня ложных срабатываний.
Избегать ложных отрицательных результатов гораздо важнее, чем избегать ложных срабатываний, когда ресурсы ограничены для разработки идеальной модели, которую мы бы оптимизировали для более высокого отзыва, поскольку мы хотим, чтобы модель была максимально точной, особенно при прогнозировании положительного класса.

import numpy as np
def recall(y_true, y_pred):
assert y_true.shape == y_pred.shape
return ((y_pred == 1) & (y_true == 1)).sum() / y_true.sum()
реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import recall_score recall_score(y_class_true, y_class_pred)
Оценка F1
Оценка F1 — это способ объединить точность и полноту в единую метрику, которая дает более полное представление о производительности модели. Гармоническое среднее используется потому, что и точность, и полнота выражаются в виде коэффициентов, поэтому нам нужен способ их объединения, учитывающий их относительный вклад. Оценка F1 дает равный вес точности и отзыву, что важно, когда мы хотим сбалансировать компромисс между ними. Например, если мы диагностируем редкое заболевание, мы можем захотеть оптимизировать для высокой полноты, но не за счет точности. Оценка F1 помогает нам найти оптимальный баланс между этими двумя показателями.
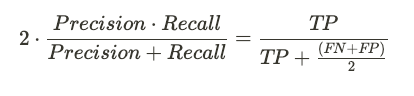
def f1_score(y_true, y_pred):
num = (2 * precision(y_true, y_pred) * recall(y_true, y_pred))
denom = (precision(y_true, y_pred) + recall(y_true, y_pred))
return num / denom
По сравнению с точностью и полнотой оценка F1 обеспечивает лучшее понимание точности положительной классификации классов.
Оценка F1 может быть расширена до оценки F-бета, что позволяет регулировать важность, придаваемую точности и полноте. Значение бета определяет вес или акцент, придаваемый каждой из этих метрик.

Установка бета ниже 1 придает больший вес точности, а это означает, что показатель точности будет цениться больше во время гармонического среднего. С другой стороны, установка бета на значение больше 1 подчеркивает показатель отзыва. Это обеспечивает большую гибкость при сочетании показателей точности и отзыва, поскольку объем внимания можно регулировать в зависимости от ситуации.
Реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import f1_score f1_score(y_class_true, y_class_pred)
Оценка F1 является полезной метрикой для оценки точности прогнозов положительного класса модели, но она имеет некоторые ограничения. Одним из ограничений является то, что он измеряет только положительный класс и не предоставляет информацию о том, насколько хорошо модель работает с отрицательным классом. Другое ограничение заключается в том, что он основан на пороге бинарной классификации, который может не быть оптимальным порогом для данной проблемы. Это может привести к потере важной информации об уверенности модели в своих прогнозах. Поэтому важно учитывать эти ограничения при использовании оценки F1 и других показателей бинарной оценки.
ОКР-АУК
область под кривой рабочих характеристик приемника представляет собой график истинной положительной частоты в сравнении с ложноположительной частотой для различных пороговых значений.
Отзыв или истинно положительный показатель указывает долю правильных прогнозов из всех положительных прогнозов, сделанных моделью. С другой стороны, процент ложноположительных результатов — это доля отрицательных образцов, которые были ошибочно классифицированы как положительные. Это мера того, как часто модель ошибается, когда она предсказывает положительный результат. Путем построения графика истинно положительных показателей и показателей ложноположительных результатов для различных порогов классификации создается кривая ROC. Эта кривая помогает определить оптимальное пороговое значение и позволяет нам визуализировать компромисс между истинно положительными показателями и ложноположительными показателями.
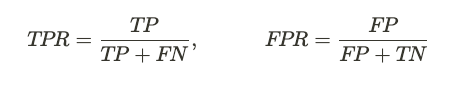
Кривая ROC отображает процент истинных положительных результатов (TPR) в сравнении с уровнем ложных положительных результатов (FPR) для различных пороговых значений предсказанных моделью вероятностей. TPR — это доля фактических положительных результатов, которые правильно классифицируются как положительные, а FPR — это доля фактических отрицательных результатов, которые ошибочно классифицируются как положительные.
def get_tpr_fpr(y_pred, y_true):
tp = (y_pred == 1) & (y_true == 1)
tn = (y_pred == 0) & (y_true == 0)
fp = (y_pred == 1) & (y_true == 0)
fn = (y_pred == 0) & (y_true == 1)
tpr = tp.sum() / (tp.sum() + fn.sum())
fpr = fp.sum() / (fp.sum() + tn.sum())
return tpr, fpr
Чтобы построить кривую ROC, нам нужно вычислить процент истинных положительных результатов (TPR) и уровень ложных положительных результатов (FPR) для различных пороговых значений. Функцию можно использовать для расчета TPR и FPR для каждого порога на основе предсказанных вероятностей, сгенерированных моделью. Функция выбирает определенное количество порогов и вычисляет TPR и FPR для каждого из этих порогов. Затем эти значения сохраняются в отдельных списках и возвращаются функцией.
Когда у нас есть значения TPR и FPR для разных порогов, мы можем построить кривую ROC, где ось x представляет FPR, а ось y представляет TPR. Однако вычислить площадь под кривой (AUC) с помощью интегралов сложно, поскольку у нас нет точной функции, представляющей кривую для всех значений TPR и FPR. Вместо этого мы можем оценить площадь, разделив кривую на прямоугольные участки и просуммировав их площади. По мере того, как мы используем все больше и больше прямоугольников, предполагаемая площадь становится все ближе к истинной площади под кривой. AUC обеспечивает меру того, насколько хорошо модель различает классы, при этом значение 1 указывает на идеальное различие, а значение 0,5 указывает на случайные прогнозы.
def roc_curve(y_pred, y_true, n_thresholds=100):
fpr_thresh = []
tpr_thresh = []
for i in range(n_thresholds + 1):
threshold_vector = (y_true >= i/n_thresholds)
tpr, fpr = get_tpr_fpr(y_pred, y_true)
fpr_thresh.append(fpr)
tpr_thresh.append(tpr)
return tpr_thresh, fpr_thresh
def area_under_roc_curve(y_true, y_pred):
fpr, tpr = roc_curve(y_pred, y_true)
rectangle_roc = 0
for k in range(len(fpr) - 1):
rectangle_roc += (fpr[k]- fpr[k + 1]) * tpr[k]
return 1 - rectangle_roc
Реализация одной строкой с использованием библиотеки sklearn:
from sklearn.metrics import roc_auc_score roc_auc_score(y_true, y_pred)
В этой статье обсуждаются различные метрики и методы оценки, используемые в машинном обучении, включая точность, точность, полноту, оценку F1, кривую ROC и AUC. В нем объясняется интуиция, стоящая за каждой метрикой, и способы их расчета. В статье также рассматриваются ограничения этих показателей и способы их решения. В целом, статья направлена на то, чтобы демистифицировать концепции метрик и оценки в машинном обучении, сделав их более доступными как для новичков, так и для практиков.