K-means++ is an improvement on the standard K-means clustering algorithm. Like K-means, it is an unsupervised learning algorithm used to group similar data points together based on their similarity. The goal of K-means++ is to initialize the cluster centers in a more intelligent way than the random initialization used by K-means, which can lead to suboptimal results.
Как работает K-Means++
Вот основные шаги алгоритма K-средних++:
Шаг 1. Инициализируйте первый центр кластера, случайным образом выбрав одну точку данных из набора данных.
Шаг 2. Для каждой точки данных, еще не выбранной в качестве центра кластера, вычислите расстояние между точкой и ближайшим центром кластера.
Шаг 3. Выберите следующий центр кластера из оставшихся точек данных с вероятностью, пропорциональной квадрату расстояния до ближайшего центра кластера. Это гарантирует, что новый центр находится далеко от существующих центров. Это помогает гарантировать, что начальные центры кластеров хорошо распределены по набору данных, а не сгруппированы в одном регионе. Это, в свою очередь, может привести к более точным результатам кластеризации, поскольку начальные центры кластеров могут сильно повлиять на окончательный результат кластеризации.
Шаг 4. Повторяйте шаги 2 и 3, пока не будут инициализированы все K кластерных центров.
Приступайте к стандартному алгоритму K-средних, чтобы назначать точки данных кластерам и обновлять центры кластеров до сходимости.
Инициализируя кластерные центры более интеллектуальным способом, K-means++ с меньшей вероятностью застрянет в неоптимальном решении и может привести к лучшим результатам кластеризации.
Как работает код
Давайте создадим несколько случайных точек и нанесем их на график
import numpy as np import matplotlib.pyplot as pltX = np.random.rand(100, 2) * 2 plt.scatter(X[:, 0], X[:, 1]) plt.show()
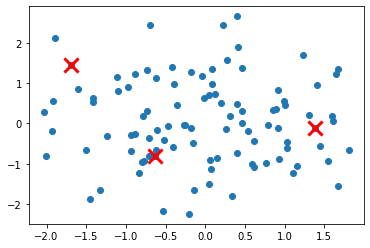
Шаг 1: Инициализируйте первый центр кластера, случайным образом выбрав одну точку данных из набора данных.
# Generate some random data import numpy as np X = np.random.randn(100, 2) # Initialize the first cluster center by randomly selecting one data point from the dataset center_indices = np.random.choice(len(X), size=1) centers = X[center_indices]# Lets plot the inital Cluster plt.scatter(centers[:, 0], centers[:, 1], marker='x', s=200, linewidths=3, color='r') plt.scatter(X[:, 0], X[:, 1]) plt.show()

Шаг 2: Для каждой точки данных, еще не выбранной в качестве центра кластера, вычислите расстояние между точкой и ближайшим центром кластера.
# Compute the distances between each data point and the nearest cluster center
distances = np.sqrt(((X - centers[:, np.newaxis])**2).sum(axis=2))
min_distances = distances.min(axis=0)Шаг 3: Выберите следующий центр кластера из оставшихся точек данных с вероятностью, пропорциональной квадрату расстояния до ближайшего центра кластера.
# Select the next cluster center with probability proportional to the distance squared to the nearest cluster center probs = min_distances**2 / np.sum(min_distances**2) center_index = np.random.choice(np.arange(len(X)), p=probs) centers = np.vstack([centers, X[center_index]])#Lets plot again and check the clusters plt.scatter(centers[:, 0], centers[:, 1], marker='x', s=200, linewidths=3, color='r') plt.scatter(X[:, 0], X[:, 1]) plt.show()

Шаг 4: Повторяйте шаги 2 и 3, пока не будут инициализированы все K кластерных центров.
# Initialize K-means++ clustering algorithm with 3 clusters
k = 3
centers = X[np.random.choice(len(X), size=1)]
#Lets plot again and check the clusters
plt.scatter(centers[:, 0], centers[:, 1], marker='x', s=200, linewidths=3, color='r')
plt.scatter(X[:, 0], X[:, 1])
plt.show()
while len(centers) < k:
distances = np.sqrt(((X - centers[:, np.newaxis])**2).sum(axis=2))
min_distances = distances.min(axis=0)
probs = min_distances**2 / np.sum(min_distances**2)
center_index = np.random.choice(np.arange(len(X)), p=probs)
centers = np.vstack([centers, X[center_index]])
#Lets plot again and check the clusters
plt.scatter(centers[:, 0], centers[:, 1], marker='x', s=200, linewidths=3, color='r')
plt.scatter(X[:, 0], X[:, 1])
plt.show()


На этом шаге мы повторяем шаги 2 и 3 до тех пор, пока не будут инициализированы все центры K кластеров. Сначала мы устанавливаем количество кластеров равным k. Затем мы инициализируем первый центр кластера, как описано в шаге 1. Мы используем цикл while для повторения шагов 2 и 3, пока len(centers) не станет равным k.
Шаг 5: Продолжите стандартный алгоритм K-средних для присвоения данных
cnt = 0 centroids = None while True and cnt < 10: cnt = cnt +1 # Initialize the first cluster center by randomly selecting one data point from the dataset center_indices = np.random.choice(len(X), size=1) centers = X[center_indices] # Calculate new centroids while len(centers) < k: distances = np.sqrt(((X - centers[:, np.newaxis])**2).sum(axis=2)) min_distances = distances.min(axis=0) probs = min_distances**2 / np.sum(min_distances**2) center_index = np.random.choice(np.arange(len(X)), p=probs) centers = np.vstack([centers, X[center_index]]) # Check for convergence if centroids is not None and np.all(centroids == centers): break # Update centroids centroids = centers#Plot the new clusters plt.scatter(X[:, 0], X[:, 1]) plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=200, linewidths=3, color='r') plt.show()
Минусы Kmeans
Хотя K-means++ является популярным и эффективным алгоритмом кластеризации, он не лишен своих ограничений и недостатков. Вот некоторые из основных недостатков K-means++:
- Чувствительность к начальному семени: хотя K-средние++ помогает обеспечить хороший начальный набор центров кластеров, алгоритм по-прежнему чувствителен к начальному семени или начальной точке. Разные исходные значения могут привести к разным центрам кластеров и, в конечном счете, к разным результатам кластеризации.
- Сложность определения оптимального количества кластеров: K-means++ требует, чтобы количество кластеров было указано заранее. Однако определение оптимального количества кластеров не всегда просто и может потребовать проб и ошибок или других методов, таких как метод локтя или оценка силуэта.
- Склонность к локальным оптимумам: как и традиционные K-средние, K-средние++ склонны застревать в локальных оптимумах, что может привести к субоптимальным результатам кластеризации. Этого можно избежать, запустив алгоритм несколько раз с разными исходными значениями и выбрав наилучший результат.
- Предполагается, что кластеры сферические: K-means++ предполагает, что кластеры имеют сферическую форму и имеют одинаковый размер и плотность. Это может не подходить для наборов данных с кластерами несферической или неправильной формы.
- Может быть дорогостоящим в вычислительном отношении: K-means++ может быть дорогостоящим в вычислительном отношении для больших наборов данных или многомерных данных. Алгоритм требует многократных итераций вычисления расстояний и вероятностей, что может занять много времени для больших наборов данных или многомерных данных.
- Проблемы с многомерными данными
В целом, K-means++ является полезным и широко используемым алгоритмом кластеризации, но важно знать о его ограничениях и потенциальных недостатках.
Когда использовать Kmeans++
K-средних++ хороший выбор, когда количество кластеров известно или может быть оценено заранее. Это также хороший выбор, когда данные имеют четкую базовую структуру, а кластеры относительно хорошо разделены. K-means предназначен для использования, когда все ваши функции являются числовыми.
Вот несколько сценариев, в которых K-means++ может быть хорошим выбором:
- Сегментация изображения: K-means++ можно использовать для сегментации изображения, цель которого состоит в том, чтобы разделить изображение на разные области на основе цвета или текстуры. В этом случае количество кластеров можно оценить на основе количества отдельных областей на изображении.
- Сегментация рынка: K-means++ можно использовать для сегментации рынка, где цель состоит в том, чтобы определить группы клиентов со схожим покупательским поведением или предпочтениями. В этом случае количество кластеров можно оценить на основе количества отдельных потребительских сегментов.
- Категоризация инвентаря
Это интуиция к K Means++. Оригинальный инструмент может отличаться от этого.
Оставайтесь с нами для большего количества таких объяснений.