MLlib — это библиотека машинного обучения (ML) Spark. Его цель — сделать практическое машинное обучение масштабируемым и простым. На высоком уровне он предоставляет такие инструменты, как:
- Алгоритмы машинного обучения: общие алгоритмы обучения, такие как классификация, регрессия, кластеризация и совместная фильтрация.
- Характеризация: извлечение признаков, преобразование, уменьшение размерности и выбор
- Конвейеры: инструменты для создания, оценки и настройки конвейеров машинного обучения.
- Постоянство: сохранение и загрузка алгоритмов, моделей и конвейеров
- Утилиты: линейная алгебра, статистика, обработка данных и т. д.
Предпосылки:
1. Знание Pyspark
2. Вы можете кодировать в любой среде, в которой установлен Pyspark, я использую версию databricks сообщества для демонстрационных целей.
Модели регрессии (как линейные, так и нелинейные) используются для прогнозирования реальной стоимости, например, зарплаты. Если вашей независимой переменной является время, то вы прогнозируете будущие значения, в противном случае ваша модель прогнозирует текущие, но неизвестные значения.
Регрессионный анализ - это форма метода прогнозного моделирования, который исследует взаимосвязь между зависимой (целевой) и независимой переменной (переменными) (предиктором). Например, взаимосвязь между необдуманным вождением и количеством дорожно-транспортных происшествий с участием водителя лучше всего изучать с помощью регрессии.

В этой части вы поймете и узнаете, как реализовать следующие регрессионные модели машинного обучения:
Простая линейная регрессия
Он используется для оценки реальных значений (стоимость домов, количество звонков, общий объем продаж и т. д.) на основе непрерывных переменных. Здесь мы устанавливаем связь между независимыми и зависимыми переменными, подбирая наилучшую линию.
Эта линия наилучшего соответствия известна как линия регрессии и представлена линейным уравнением Y= a *X + b.

Код:
Набор данных доступен по адресу:
ML_Sklearn/Простая линейная регрессия на мастере · shorya1996/ML_Sklearn · GitHub
from pyspark.sql import SparkSession
from pyspark.ml.stat import Correlation
import pyspark.sql.functions as f
from pyspark.ml.linalg import Vector
from pyspark.ml.feature import VectorAssembler
spark = SparkSession.builder.getOrCreate()
from pyspark.sql.types import *
Schema = StructType([
StructField('YearsExperience', FloatType(), True),
StructField('Salary', FloatType(), True)
])
df = spark.read.csv("/FileStore/tables/Salary_Data.csv", header=True,schema=Schema)
assembler = VectorAssembler(inputCols=['YearsExperience'],outputCol='features')
data_set = assembler.transform(df)
data_set = data_set.select(['features','salary'])
train_data,test_data = data_set.randomSplit([0.8,0.2])
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol="features",labelCol='salary')
lrModel = lr.fit(train_data)
test_stats = lrModel.evaluate(test_data)
print(f"RMSE: {test_stats.rootMeanSquaredError}")
print(f"R2: {test_stats.r2}")
print(f"R2: {test_stats.meanSquaredError}")

test_stats.predictions.show()

Множественная линейная регрессия
Линейная регрессия бывает в основном двух типов: простая линейная регрессия и множественная линейная регрессия. Простая линейная регрессия характеризуется одной независимой переменной. И множественная линейная регрессия (как следует из названия) характеризуется несколькими (более 1) независимыми переменными.

Допустим, вы просите врача определить значение вашего ИМТ (индекса массы тела). Он примет во внимание ваш рост и вес для расчета ИМТ. Итак, здесь ИМТ — ваша зависимая переменная, а вес и рост — ваши независимые переменные.
Код:
Набор данных доступен по адресу 50_Startups.csv:
Я создал таблицу в databricks из CSV-файла, вы также можете напрямую использовать CSV-файл.
df = spark.sql("select * from startups")
df.show()

from pyspark.ml.feature import StringIndexer indexer = StringIndexer(inputCol='State', outputCol='State_numeric') indexer_fitted = indexer.fit(df) df_indexed = indexer_fitted.transform(df) from pyspark.ml.feature import OneHotEncoder encoder = OneHotEncoder(inputCols=['State_numeric'], outputCols=['State_onehot']) df_onehot = encoder.fit(df_indexed).transform(df_indexed) df_onehot.printSchema()

from pyspark.ml.functions import vector_to_array
df_col_onehot = df_onehot.select('*', vector_to_array('state_onehot').alias('col_onehot'))
df_col_onehot.show()

num_categories = len(df_col_onehot.first()['col_onehot'])
cols_expanded = [(f.col('col_onehot')[i].alias(f'{indexer_fitted.labels[i]}')) for i in range(num_categories)]
df_cols_onehot = df_col_onehot.select('*', *cols_expanded)
df_cols_onehot.show()

df_final = df_cols_onehot.select("R&D Spend", "Administration", "Marketing Spend", "California", "New York", "profit")
assembler = VectorAssembler(inputCols=df_final.columns[:-1],outputCol='features')
data_set = assembler.transform(df_final)
data_set = data_set.select(['features','profit'])
data_set.show()

train_data,test_data = data_set.randomSplit([0.8,0.2])
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol="features",labelCol='profit')
lrModel = lr.fit(train_data)
test_stats = lrModel.evaluate(test_data)
print(f"RMSE: {test_stats.rootMeanSquaredError}")
print(f"R2: {test_stats.r2}")
print(f"R2: {test_stats.meanSquaredError}")
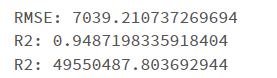
test_stats.predictions.show()

Регрессия дерева решений
Дерево решений строит модели регрессии или классификации в виде древовидной структуры. Он разбивает набор данных на все меньшие и меньшие подмножества, в то же время постепенно разрабатывается соответствующее дерево решений. В результате получается дерево с узлами решений и листовыми узлами. У узла решения есть два или более узла, каждый из которых представляет значения для тестируемого атрибута. Листовой узел представляет собой решение о числовой цели. Верхний узел решения в дереве, который соответствует лучшему предсказателю, называется корневым узлом. Деревья решений могут обрабатывать как категориальные, так и числовые данные.


Алгоритм дерева решений
Основной алгоритм построения деревьев решений, названный Дж. Р. Куинланом ID3, использует жадный поиск сверху вниз в пространстве возможных ветвей без возврата. Алгоритм ID3 можно использовать для построения дерева решений для регрессии, заменив прирост информации на уменьшение стандартного отклонения.
Стандартное отклонение
Дерево решений строится сверху вниз от корневого узла и включает в себя разделение данных на подмножества, содержащие экземпляры с похожими значениями (однородные). Мы используем стандартное отклонение для расчета однородности числовой выборки. Если числовая выборка полностью однородна, ее стандартное отклонение равно нулю.
а) Стандартное отклонение для одного атрибута


Уменьшение стандартного отклонения
Уменьшение стандартного отклонения основано на уменьшении стандартного отклонения после разделения набора данных по атрибуту. Построение дерева решений заключается в поиске атрибута, который дает наибольшее уменьшение стандартного отклонения (т. е. наиболее однородные ветви).

Код:
Набор данных доступен по адресу
ML_Sklearn/Регрессия дерева решений/Position_Salaries.csv в мастере · shorya1996/ML_Sklearn · GitHub
df = spark.sql("select * from position_salaries")
df.show()
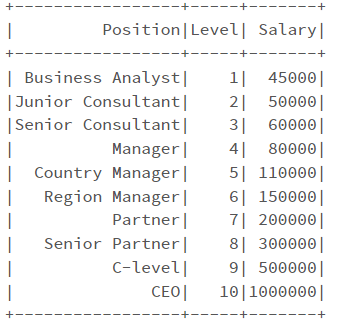
from pyspark.ml.feature import StringIndexer indexer = StringIndexer(inputCol='Position', outputCol='Position_numeric') indexer_fitted = indexer.fit(df) df_indexed = indexer_fitted.transform(df) assembler = VectorAssembler(inputCols=[ 'Level', 'Position_numeric'],outputCol='features') data_set = assembler.transform(df_indexed) data_set = data_set.select(['features','Salary']) data_set.show()

from pyspark.ml.regression import DecisionTreeRegressor dr = DecisionTreeRegressor(featuresCol="features",labelCol='Salary') drModel = dr.fit(data_set)
Случайная лесная регрессия
Модель случайного леса — это тип аддитивной модели, которая делает прогнозы, комбинируя решения из последовательности базовых моделей. Более формально мы можем записать этот класс моделей как:
g(x)=f0(x)+f1(x)+f2(x)+…
где окончательная модель g представляет собой сумму простых базовых моделей fi. Здесь каждый базовый классификатор представляет собой простое дерево решений.
ЭТАПЫ СЛУЧАЙНОЙ РЕГРЕССИИ ЛЕСА

Код:
Используемый набор данных — это набор данных о недвижимости, доступный по адресу:
# The inputs are as follows
# X1=the transaction date (for example, 2013.250=2013 March, 2013.500=2013 June, etc.)
# X2=the house age (unit: year)
# X3=the distance to the nearest MRT station (unit: meter)
# X4=the number of convenience stores in the living circle on foot (integer)
# X5=the geographic coordinate, latitude. (unit: degree)
# X6=the geographic coordinate, longitude. (unit: degree)
# The output is as follow
# Y= house price of unit area (10000 New Taiwan Dollar/Ping, where Ping is a local unit, 1 Ping = 3.3 meter squared)
df = spark.sql("select * from real_estate")
df.show()

assembler = VectorAssembler(inputCols=df.columns[1:-1],outputCol='features') data_set = assembler.transform(df) data_set = data_set.select(['features','Y house price of unit area']) data_set.show()

train_data,test_data = data_set.randomSplit([0.8,0.2]) from pyspark.ml.regression import RandomForestRegressor rf = RandomForestRegressor(featuresCol="features",labelCol='Y house price of unit area') rfModel = rf.fit(train_data) test_stats = rfModel.transform(test_data) test_stats.show()
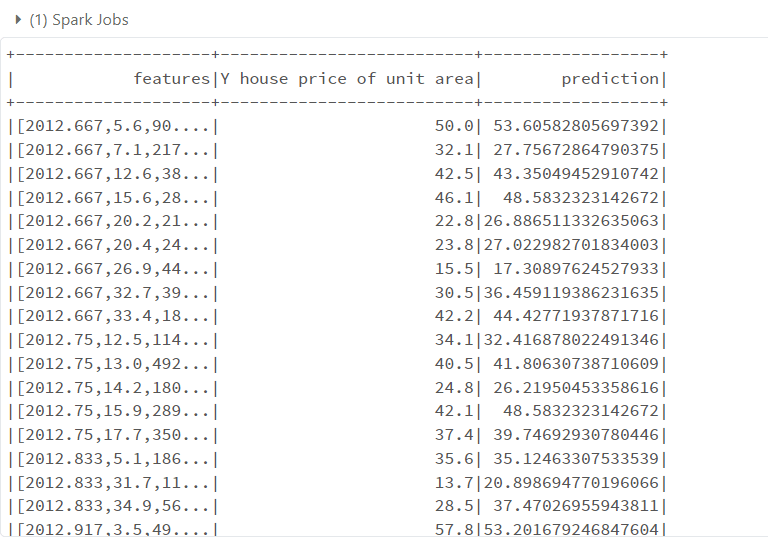
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(
labelCol="Y house price of unit area", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(test_stats)
rmse
7.484506897505033
Это подводит нас к концу нашей части 1. Полный код доступен по адресу
PySpark/regression_mllib.ipynb на главной · shorya1996/PySpark (github.com)
подпишитесь на меня в LinkedIn
LinkedIn: https://www.linkedin.com/in/shorya-sharma-b94161121