
В дождливый день, когда стук капель дождя по оконному стеклу оркеструет симфонию, я нахожу утешение в мире программирования. Я предпринял бесчисленное множество путешествий по программированию, каждое из которых сопровождалось собственным набором проблем и триумфов. Точно так же, как дождь, который иногда играет непредсказуемо, кодирование тоже может иметь свою долю непредсказуемых моментов, когда возникает икота, и мы должны искать средства, чтобы справляться с ними.
В огромном ландшафте разработки программного обеспечения Spring Boot выступает как маяк надежды, принося освежающий ветерок простоты и эффективности. Подобно нежному приходу весны, он предлагает обновленное чувство энтузиазма, делая процесс разработки более приятным и управляемым. Spring Boot позволяет нам сосредоточиться на создании замечательных приложений, в то время как утомительные и повторяющиеся задачи настройки выполняются за кулисами.
Теперь давайте углубимся в увлекательный аспект Spring Boot, который оказался ценным союзником в создании устойчивых и масштабируемых систем — SQS или Simple Queue Service. SQS, предлагаемый Amazon Web Services (AWS), представляет собой полностью управляемый сервис очередей сообщений, который позволяет приложениям взаимодействовать асинхронно, разделяя отправителя и получателя. Он выступает в качестве надежного посредника, обеспечивая безопасную доставку сообщений между компонентами, даже при колебаниях спроса или возможных сбоях в системе.
Работа с spring boot и SQS для меня не нова. Несколько лет назад я работал над проектом весенней загрузки, где использовал SQS. Недавно у меня появилась возможность начать новый проект. Убедившись в доказанных достоинствах SQS в прошлом, я с нетерпением решил включить его в это новое начинание. Однако, к моему удивлению, я обнаружил, что сталкиваюсь с непредвиденными проблемами, с которыми я не мог припомнить, чтобы сталкивался раньше. Возможно, в моем предыдущем проекте я присоединился к команде, когда она достигла определенного уровня зрелости, и конфигурации уже были на месте, умело обработанные другим членом команды. Однако на этот раз мои ожидания гладкой работы с минимальной конфигурацией для базовых вариантов использования столкнулись с неожиданными препятствиями.
В этой статье я поделюсь проблемами, с которыми я столкнулся, и тем, что я сделал, чтобы преодолеть эти проблемы.
Сначала я создал новый проект весенней загрузки с инициализатором весны. Я использую весеннюю загрузочную версию 2.7.7. Поскольку теперь я загрузил проект, теперь мне нужен экземпляр SQS для тестирования нашей разработки. Я не хочу запускать настоящий экземпляр sqs. Чтобы сэкономить немного денег, я предпочитаю развертывать локальный sqs с докером. Вот состав докера:
version: "3"
services:
sqs:
image: roribio16/alpine-sqs
ports:
- '9334:9324'
- '9335:9325'
volumes:
- my-datavolume:/sqs-data
volumes:
my-datavolume:
Только для этой демонстрации я выбрал это изображение roribio16/alpine-sqs. Он легкий, а также имеет пользовательский интерфейс. В то время как localstack немного тяжеловат.
Теперь компоновка докеров должна привести нас к запуску sqs.
Так вот Идея. У меня будет такая dto Task:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Task {
private String id;
private String name;
private String description;
}
И такой контроллер:
@PostMapping("/task")
public void createTask(@RequestBody Task task){
log.info("Received task {}", task.toString());
queueService.publishTask(task);
}
Так что я могу отправить задачи в эту конечную точку, и эта конечная точка вызовет метод в queueService, который будет иметь необходимые коды для публикации задач в sqs.
Позже мы создадим класс прослушивателя, который будет получать задачи из очереди и выполнять некоторые тяжелые (!!) вычисления. Нет, просто несколько журналов, но он должен передать идею.
С spring-cloud-starter-aws-messaging мы получаем QueueMessagingTemplate. Это абстракция, позволяющая легко публиковать/получать сообщения в очередь. Он также предоставляет API для настройки различных конвертеров.
Итак, мы собираемся создать Bean-компонент QueueMessagingTemplate. Для создания функционального QueuMessagingTemplate нам также понадобится экземпляр SqsClient. Мы создадим их обоих в классе с именем SQSConfig.
@Configuration
public class SqsConfig {
private final int BATCH_SIZE = 10;
private final String queueEndpoint;
public SqsConfig(@Value("${queue.endpoint}") String queueEndpoint) {
this.queueEndpoint = queueEndpoint;
}
@Bean
@Primary
public AmazonSQSAsync amazonSQSAsync(@Value("${spring.profiles.active}") String profile){
if(profile.equals("dev")){
return AmazonSQSAsyncClientBuilder
.standard()
.withEndpointConfiguration(new AwsClientBuilder.EndpointConfiguration(queueEndpoint,
Region.AP_SOUTHEAST_1.id()))
.build();
}
else{
return AmazonSQSAsyncClientBuilder
.standard()
.withRegion(Region.AP_SOUTHEAST_1.id())
.build();
}
}
@Bean
public QueueMessagingTemplate queueMessagingTemplate(AmazonSQSAsync amazonSQSAsync) {
return new QueueMessagingTemplate(amazonSQSAsync);
}
Как и в моей среде dev, у меня есть собственные sqs, работающие по адресу http://127.0.0.1:9334, что не является обычной конечной точкой sqs, поэтому я создал экземпляр с помощью AmazonSQSAsyncClientBuilder, указав конечную точку для разработчика.
Теперь пришло время создать реализацию QueueService. Мы возьмем в конструкторе queueMessagingTemplate и воспользуемся его методом convertAndSend для публикации сообщения в нашей очереди.
@Slf4j
@Service
public class QueueServiceImpl implements QueueService {
private final QueueMessagingTemplate queueMessagingTemplate;
private final String taskQueue;
public QueueServiceImpl(QueueMessagingTemplate queueMessagingTemplate,
@Value("${queue.task}") String taskQueue) {
this.queueMessagingTemplate = queueMessagingTemplate;
this.taskQueue = taskQueue;
}
@Override
public void publishTask(Task task) {
task.setId(UUID.randomUUID().toString());
log.info("Publishing task to queue {}", task);
queueMessagingTemplate.convertAndSend(taskQueue, task);
}
}
Давайте перезапустим сервер и будем надеяться, что все скомпилируется. Затем запустите следующий завиток:
curl --location 'http://localhost:8080/task' \
--header 'Content-Type: application/json' \
--data '{
"name":"Task 1",
"description": "save the world"
}'
Теперь, если мы перейдем к http://localhost:9335/ в нашем браузере и щелкнем вкладку нашей очереди, мы сможем увидеть сообщение.
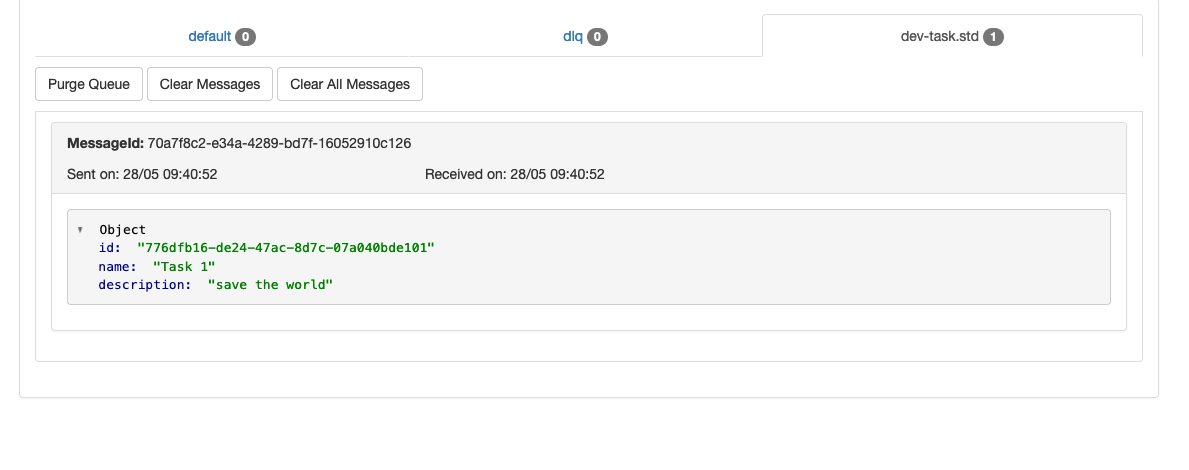
Сообщение будет там, если потребитель не получит сообщение и не удалит его.
(Для краткости я пропустил часть создания очереди. Для этого можно использовать служебный скрипт или aws cli.)
Первый сбой: модуль времени
Все идет нормально. Сейчас буду менять Dto. Я хочу добавить мгновенное поле с именем profitAt. Я заполню поле непосредственно перед публикацией в очередь. Теперь я обновил метод dto и publishTask.
@Override
public void publishTask(Task task) {
task.setId(UUID.randomUUID().toString());
task.setArrivedAt(Instant.now());
log.info("Publishing task to queue {}", task);
queueMessagingTemplate.convertAndSend(taskQueue, task);
}
После перезапуска приложения, если мы снова нажмем на завиток, то… бум!

Из этого сообщения об ошибке я могу определить, что где-то используется ObjectMapper. Старый друг всех Java-разработчиков, и мы все знаем, что когда мы используем Instant, мы должны создавать экземпляры ObjectMapper немного по-другому. Что легко. Но вопрос в том, как настроить QueueMessageTemplate для использования этого пользовательского ObjectMapper.
Погуглив и прочитав документацию, я обнаружил, что по умолчанию используется SimpleMessageConverter. Исходник нашел здесь, буду добавлять свой конвертер сообщений вот так. Но перед этим я создам bean-компонент для ObjectMapper:
@Configuration
public class ObjectMapperConfig {
@Bean
ObjectMapper getObjectMapper(){
return new ObjectMapper().registerModule(new JavaTimeModule());
}
}
Теперь я напишу свой собственный преобразователь сообщений и воспользуюсь средством сопоставления объектов, чтобы преобразовать полезную нагрузку в строку, прежде чем передать объект Message в sqs.
Мой преобразователь сообщений реализует интерфейс MessageConveter с двумя методами fromMessage и toMessage. Прямо сейчас я публикую сообщение только в sqs. Поэтому я добавлю свою собственную реализацию в метод toMessage, а для fromMessage просто скопирую реализацию из SimpleMessageConverter.
public class MyMessageConverter implements MessageConverter {
private final ObjectMapper objectMapper;
public MyMessageConverter(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@Override
public Object fromMessage(Message<?> message, Class<?> targetClass) {
return null;
}
@Override
public Message<?> toMessage(Object payload, MessageHeaders headers) {
if (headers != null) {
MessageHeaderAccessor accessor = MessageHeaderAccessor.getAccessor(headers, MessageHeaderAccessor.class);
if (accessor != null && accessor.isMutable()) {
return MessageBuilder.createMessage(getStringPayload(payload), accessor.getMessageHeaders());
}
}
return MessageBuilder.withPayload(getStringPayload(payload)).copyHeaders(headers).build();
}
private String getStringPayload(Object payload){
try {
return objectMapper.writeValueAsString(payload);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
Здесь на самом деле toMessage также является копией SimpleMessageConverter, отличие заключается в преобразовании полезной нагрузки в строку внутри метода withPayload MessageBuilder.
Наконец, подключите MyMessageConverter с QueueMessagingTemplate:
@Bean
public QueueMessagingTemplate queueMessagingTemplate(AmazonSQSAsync amazonSQSAsync, MyMessageConverter myMessageConverter) {
QueueMessagingTemplate queueMessagingTemplate = new QueueMessagingTemplate(amazonSQSAsync);
queueMessagingTemplate.setMessageConverter(myMessageConverter);
return queueMessagingTemplate;
}
Теперь, если я перезапущу сервер и нажму cURL, ошибка должна исчезнуть, и в веб-интерфейсе sqs я смогу увидеть опубликованное сообщение с новым полемprofitAt:
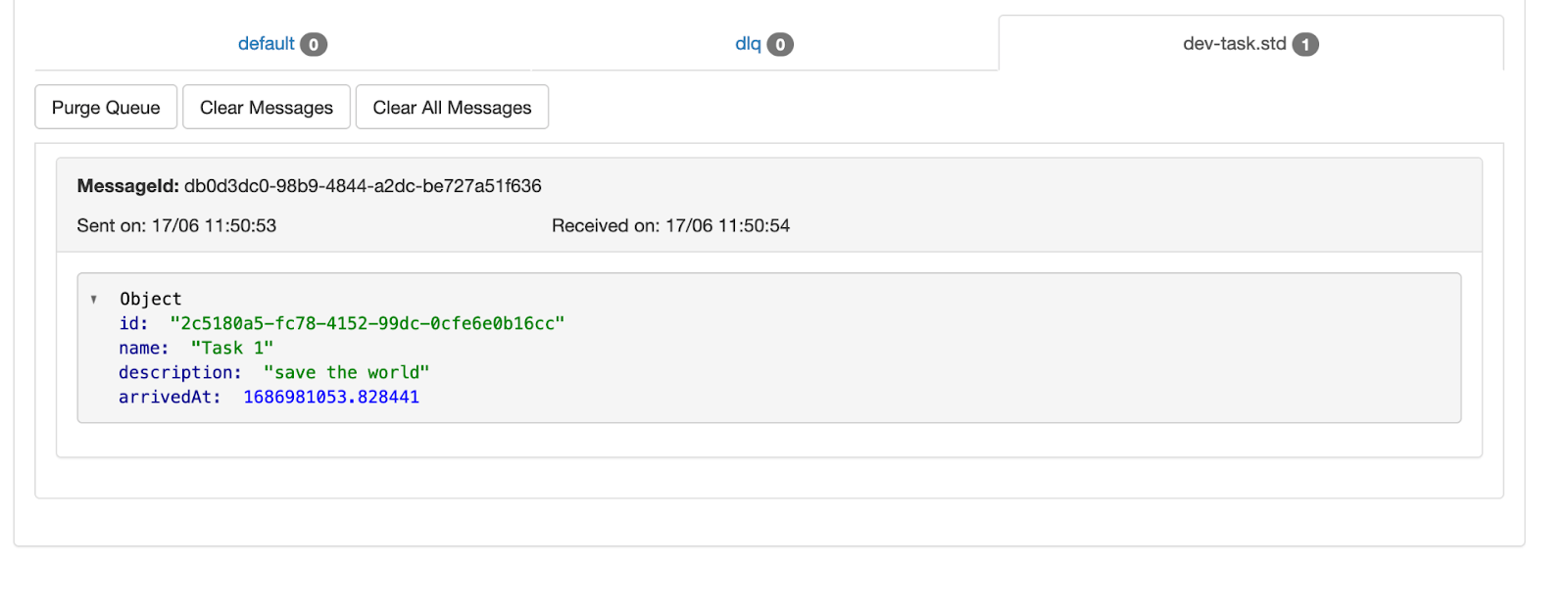
Второй сбой: слушатель не получает объект
Пока нам удалось опубликовать сообщение из контроллера в очередь. Это хорошее время, чтобы начать слушать очередь сообщений. Итак, мы добавляем службу и аннотируем метод с помощью @SqsListener:
@Service
@Slf4j
public class TaskProcessorImpl implements TaskProcessor {
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ON_SUCCESS)
public void process(String task) {
log.info("Processing task {}", task);
}
}
Этого достаточно для получения сообщений в виде строковой полезной нагрузки. Если мы перезапустим приложение, мы увидим такие журналы:
2023-06-28 12:44:21.522 INFO 10804 --- [enerContainer-2] x.r.sqsdemo.service.TaskProcessorImpl : Processing task {"id":"2813920f-589e-44ff-a38a-aeb87fd2b021","name":"Task 1","description":"save the world","arrivedAt":1687934661.470700713}
Это означает, что мы можем получать сообщения. Теперь мы можем преобразовать строку в объект и делать все, что захотим.
Но можем ли мы получить объект в методе, аннотированном с помощью SqsListener?
Наверное, можно, давайте изменим тип со String на Task.
@Service
@Slf4j
public class TaskProcessorImpl implements TaskProcessor {
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(Task task) {
log.info("Processing task {}", task);
}
}
Теперь перезапустите приложение и попробуйте опубликовать сообщение, вы увидите, что консоль снова залита ошибками.
Потому что нам нужно сообщить sqs, как он может преобразовать полученные строки в объект. Поэтому мы добавляем компонент QueueMessageHandlerFactory.
@Bean
public QueueMessageHandlerFactory queueMessageHandlerFactory(ObjectMapper objectMapper,
AmazonSQSAsync amazonSQSAsync) {
MappingJackson2MessageConverter messageConverter = new MappingJackson2MessageConverter();
messageConverter.setObjectMapper(objectMapper);
messageConverter.setStrictContentTypeMatch(false);
QueueMessageHandlerFactory factory = new QueueMessageHandlerFactory();
factory.setAmazonSqs(amazonSQSAsync);
List<HandlerMethodArgumentResolver> resolvers = List.of(
new PayloadMethodArgumentResolver(messageConverter,null, false));
factory.setArgumentResolvers(resolvers);
return factory;
}
Далее нам также нужно будет аннотировать первый параметр метода процесса как @Payload.
Теперь мы можем получать объекты напрямую от слушателя.
Третий сбой: traceId сыщика не распространяется
Это было как-то неожиданно для меня. Потому что за последние несколько лет. Мне никогда не приходилось сталкиваться с распространением идентификаторов сыщиков в журналах. Поскольку мы используем sqs с клиентами или библиотеками из весенней экосистемы, я ожидал, что это будет работать из коробки.
Но это не так. Для этого мне пришлось прочитать traceId, spanId из текущего диапазона и добавить их в заголовки перед публикацией очереди.
А на стороне слушателя я должен начать новый диапазон после чтения этих идентификаторов из заголовка сообщения, а затем внедрить их в новый контекст трассировки.
Сначала давайте поработаем над передачей traceId и spanId в сообщениях, которые мы публикуем.
В QueueServiceImpl добавляем следующий метод:
private Map<String, Object> headers() {
return Map.of(
"SleuthTraceId",tracer.currentSpan().context().traceId(),
"SleuthSpanId", tracer.currentSpan().context().spanId());
}
Затем передайте заголовки с convertAndSend следующим образом:
queueMessagingTemplate.convertAndSend(taskQueue, task, headers());
Теперь нам также нужно захватить заголовки в слушателе, чтобы мы могли их использовать.
Это не сложно. Просто нужно добавить новый аргумент, который представляет собой Map‹String, Object›, и аннотировать параметр аннотацией @Headers.
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
log.info("Processing task {}", task);
}
Если мы перезапустим приложение, опубликуем новое сообщение и поместим указатель отладки в тело метода process и попытаемся посмотреть, что содержит headers, мы найдем что-то вроде этот:
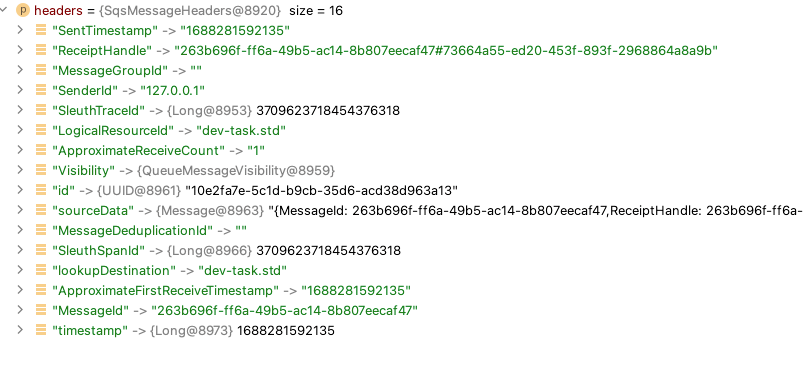
Давайте разделим их и создадим с ними новый traceContext, чтобы все последующие логи печатали их.
Итак, наш модифицированный метод процесса теперь выглядит так:
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
var traceId = headers.get("SleuthTraceId");
var spanId = headers.get("SleuthSpanId");
TraceContext traceContext = TraceContext.newBuilder()
.traceId((Long) traceId)
.spanId((Long) spanId)
.build();
Span span = tracer.nextSpan(TraceContextOrSamplingFlags.create(traceContext));
try(Tracer.SpanInScope scope = tracer.withSpanInScope(span)){
log.info("Processing task {}", task);
} catch (Throwable e) {
throw new RuntimeException(e);
} finally {
span.finish();
}
}
Теперь логи будут выглядеть так:
2023-07-02 | 13:17:59.237 | http-nio-8080-exec-6 | INFO | xyz.ruhshan.sqsdemo.web.TaskController |9e0e13588a8f5aeb,9e0e13588a8f5aeb| Received task Task(id=null, name=Task 1, description=save the world, arrivedAt=null) 2023-07-02 | 13:17:59.237 | http-nio-8080-exec-6 | INFO | x.r.sqsdemo.service.QueueServiceImpl |9e0e13588a8f5aeb,9e0e13588a8f5aeb| Publishing task to queue Task(id=919e794e-ad48-4cc7-8102-6527ba98d4cd, name=Task 1, description=save the world, arrivedAt=2023-07-02T07:17:59.237655Z) 2023-07-02 | 13:17:59.245 | eListenerContainer-2 | INFO | x.r.sqsdemo.service.TaskProcessorImpl |9e0e13588a8f5aeb,9d462662007f81cd| Processing task Task(id=919e794e-ad48-4cc7-8102-6527ba98d4cd, name=Task 1, description=save the world, arrivedAt=2023-07-02T07:17:59.237655Z)
Ура! один и тот же traceId присутствует в журналах перед публикацией в очередь и после получения из очереди.
Да, я знаю, что ты хмуришься.
Хотя это работает. Но это не чисто. Если у нас есть несколько очередей, у нас может быть несколько слушателей. И размещение одного и того же фрагмента кода span-кода для извлечения/создания/запуска в нескольких местах нарушает принцип DRY.
Что мы можем сделать?
Должно быть много способов. Делюсь тем, что сделал.
Я только что сделал следующие изменения:
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
@InjectSleuthIds
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
log.info("Processing task {}", task);
}
Да, только что добавил еще одну аннотацию @InjectSleuthIds. Но откуда оно взялось? К сожалению, мне пришлось его создать. Затем также использовал наш старый друг АОП, чтобы добавить всю функциональность чтения sleuthIds из заголовков sqs и создать с ними новый диапазон.
Это делается в отдельном классе. Но это самый интересный метод в этом классе:
@Around("@annotation(xyz.ruhshan.sqsdemo.aop.InjectSleuthIds)")
public Object injectSleuthIdsAroundAdvice(ProceedingJoinPoint proceedingJoinPoint) {
SleuthIds sleuthIds = getSleuthIdsFromPjp(proceedingJoinPoint);
TraceContext traceContext = TraceContext.newBuilder()
.traceId(sleuthIds.traceId)
.spanId(sleuthIds.spanId)
.build();
Span span = tracer.nextSpan(TraceContextOrSamplingFlags.create(traceContext));
try (var scope = tracer.withSpanInScope(span)) {
return proceedingJoinPoint.proceed();
} catch (Throwable e) {
log.error("Caught exception during proceeding join-point {}", e.getMessage());
throw new RuntimeException(e);
} finally {
span.finish();
}
}
Для вас все довольно очевидно, если вы знаете об аспектно-ориентированном программировании. Но если вы этого не сделаете. Вот мои 2 цента для вас:
- Аннотирование метода с помощью @Around("@annotation(xyz.ruhshan.sqsdemo.aop.InjectSleuthIds)") делает совершенно особую вещь. Часть этого метода будет выполнена до фактического выполнения метода, аннотированного @InjectSleuthIds, а часть метода будет выполнена после.
- ProceedingJoinPoint — это интерфейс, который дает нам доступ к аргументам, которые получает наш целевой аннотированный метод, а также к методам для вызова целевого метода.
С помощью вспомогательного метода getSleuthIdsFromPjp я извлек traceId и spanId из исходящей точки соединения.
Затем создайте spanContext.
Затем начните следующий пролет.
proceedingJoinPoint.proceed() — это вызов нашего аннотированного целевого метода. Оборачивая это с помощью оператора try with resource и запуская в ресурсной части tracer.withSpanInScope(span), мы делаем магию печати идентификаторов сыщика в журналах.
Не поймите меня неправильно. Это добавит идентификаторы сыщика не только для методов, аннотированных аннотацией InjectSleuthIds, но и для всех последующих методов в цепочке вызовов, которые могут начинаться с аннотированного метода.
Надеюсь, вам понравилась эта запись. Если вы знаете лучшие способы решения проблем, с которыми я столкнулся, я буду очень обязан узнать о них. Не стесняйтесь оставлять любые отзывы.
Здесь — полный исходный код этой демонстрации.
Поддержите меня 👇
