В какой-то момент развития бизнеса мы сталкиваемся с увеличением объема хранимых данных. Стремясь быстрее внедрить в производство новый функционал, мы можем допускать различные дизайнерские недоработки. Да, это не идеально, но в жизни так бывает. В результате этих проблем мы получаем много данных, которые не организованы в соответствии с нашими требованиями, что затрудняет дальнейшее развитие проекта. В этой статье я поделюсь некоторыми советами по переносу данных между экземплярами MongoDB.
вступление
Предположим, у нас есть интернет-магазин в США и он основан на облачной инфраструктуре в регионе США, мы решили использовать базу данных MongoDB. Изначально мы хранили заказы, товары и пользователей в одном пространстве имен базы данных, назовем его хранилищем.
db namespace: store collections: orders, products, users
Наш магазин в США начал приносить хороший доход. Через некоторое время мы подумали, а не попробовать ли нам запустить его на другие рынки, например, в Индию? Стоит попробовать. Хорошая новость для нас: нашу структуру данных не нужно сильно переделывать, просто добавьте поле country в каждый документ в коллекции и все. Поэтому мы решили добавить префикс US к существующему документу в коллекции, а для записей из Индии мы начали добавлять префикс IN.
К нашей радости, проект начал быстро набирать популярность, даже превзойдя темпы роста, которые мы наблюдали на рынке США. Однако в нашем волнении мы упустили из виду некоторые важные факторы, в том числе:
- Более низкая прибыль на одного клиента. Несмотря на то, что на индийском рынке больше клиентов, прибыль, полученная на одного клиента, значительно ниже, чем в США.
- Резкое увеличение числа клиентов. Число клиентов в Индии внезапно выросло в десять раз больше, чем в США, что создает новые проблемы.
- Затраты на инфраструктуру. Вся инфраструктура теперь развернута в регионе США, что может оказаться дорогостоящим при обслуживании клиентов из других регионов.
- Проблемы с производительностью. Высокий пинг и длительное время запроса между клиентами и серверами вызывают проблемы с производительностью, что негативно влияет на основной бизнес компании.
- Ориентация на местный рынок. Чтобы эффективно удовлетворить местные тенденции и потребности, стало очевидно, что необходимо сосредоточиться на независимой разработке продуктов для каждого региона.
- Безопасность данных и соответствие нормативным требованиям: В США в ходе аудита было обнаружено требование хранить данные в зашифрованном виде, что потребовало более строгих мер безопасности данных.
Существует множество других причин разделения данных, каждая из которых уникальна и потенциально влияет на общую эффективность и стабильность различных проектов.
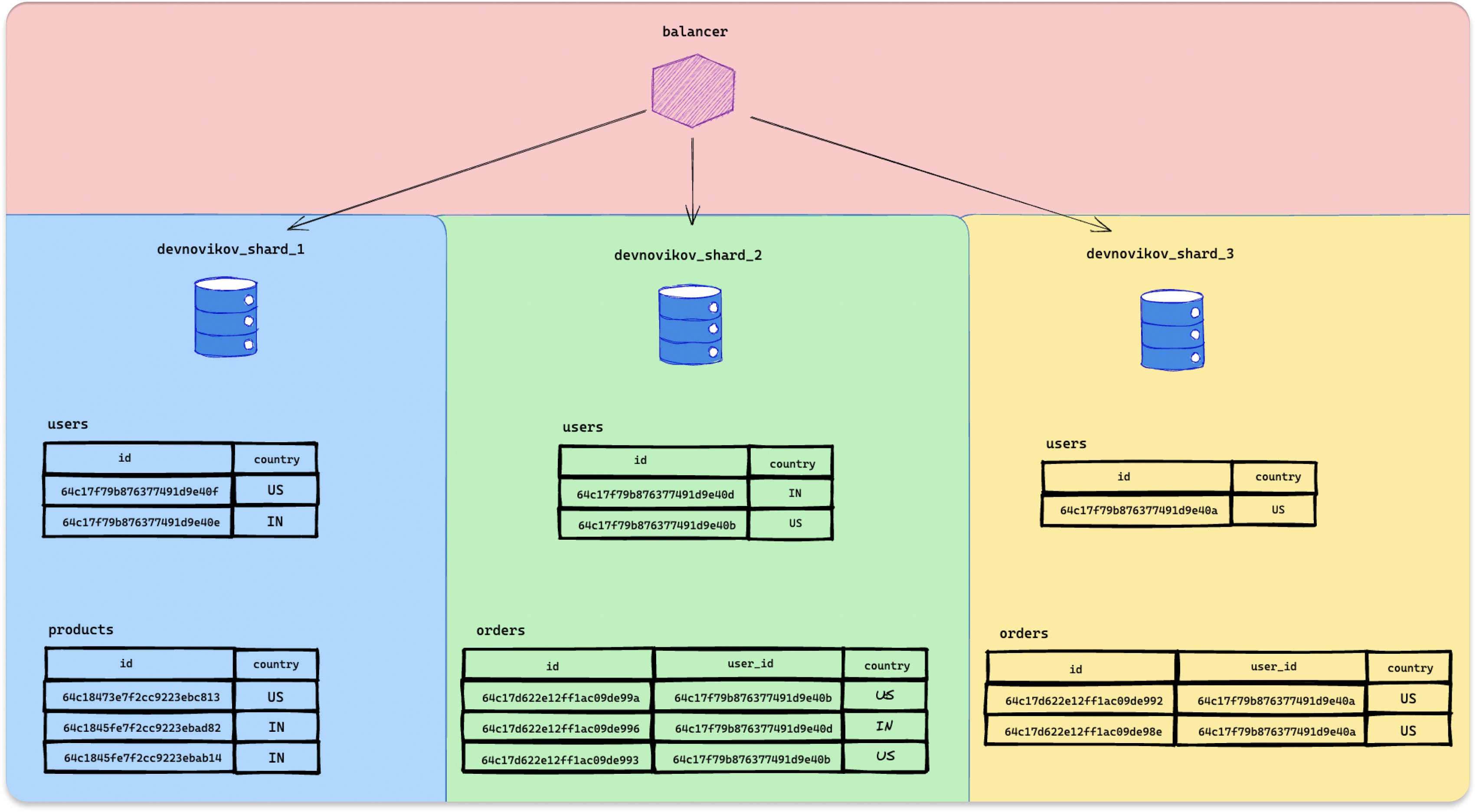
Теперь давайте углубимся в структуру базы данных. Наша база данных сегментирована и содержит три сегмента (devnovikov_shard_*). Вот список коллекций в базе данных:
пользователи — коллекция сегментируется по хеш-ключу id;
orders — еще одна сегментированная коллекция по хэш-ключу user_id;
products — несегментированная коллекция;
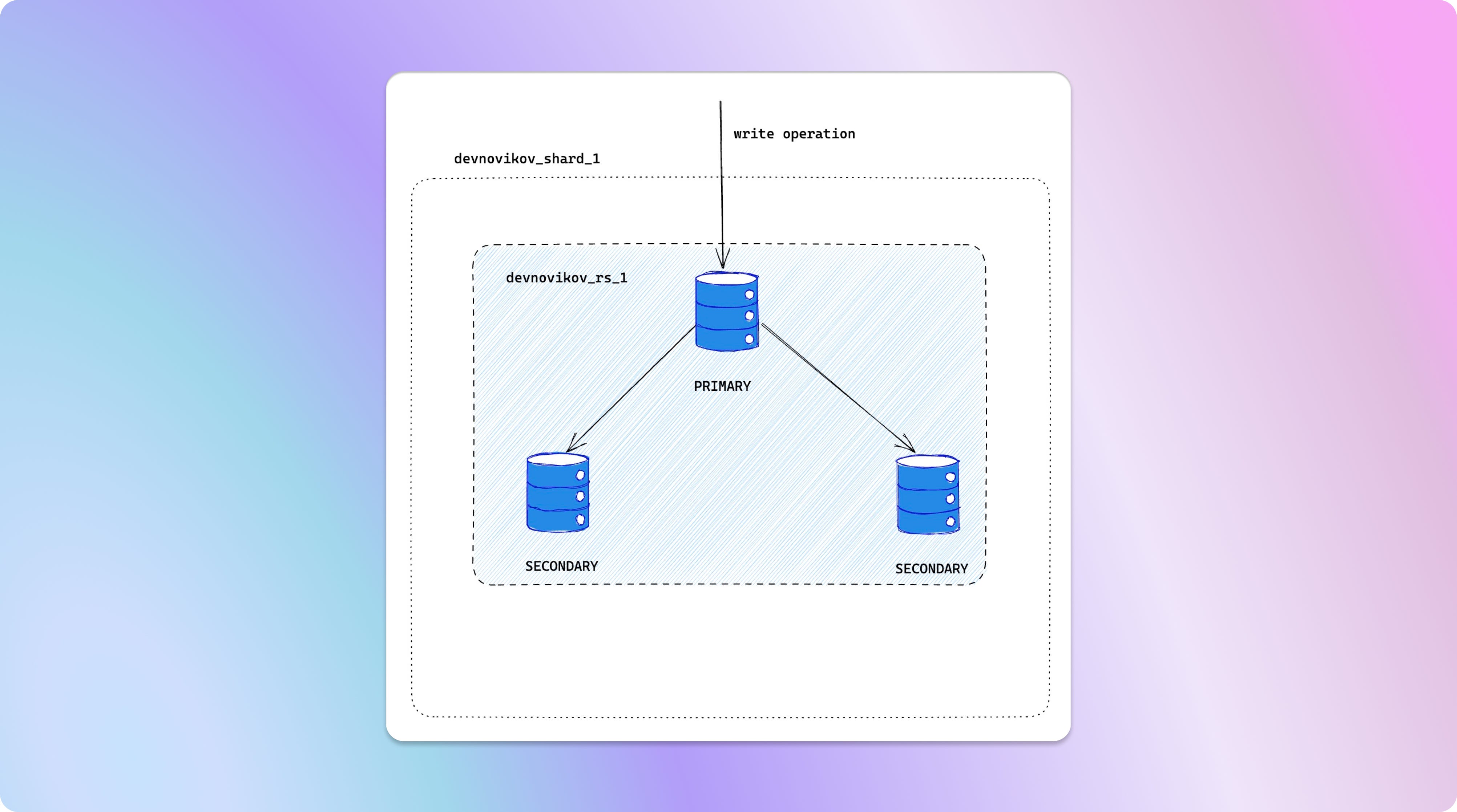
Типичная структура набора реплик с именем devnovikov_rs_1 (1 основной, 2 вторичных)
Если у вас объем данных более 1 ТБ и вам необходимо перенести документы из одного общего кластера или набора реплик в другой, вы будете удивлены, сколько времени это может занять. Этот процесс потенциально может занять несколько часов в зависимости от таких факторов, как характеристики вашего оборудования, количество задействованных индексов, пропускная способность сети и т. д. Итак…
Как мы можем ускорить процесс миграции данных?
Стратегия создания индекса
Сначала перенеситедокументы и затем создайте индексы > О новой коллекции. Когда вы создаете индекс для коллекции, MongoDB должен создать индекс для всех существующих документов. Если вы создаете индексы перед переносом данных, каждое создание индекса может привести к дополнительным накладным расходам, поскольку MongoDB необходимо индексировать документы несколько раз
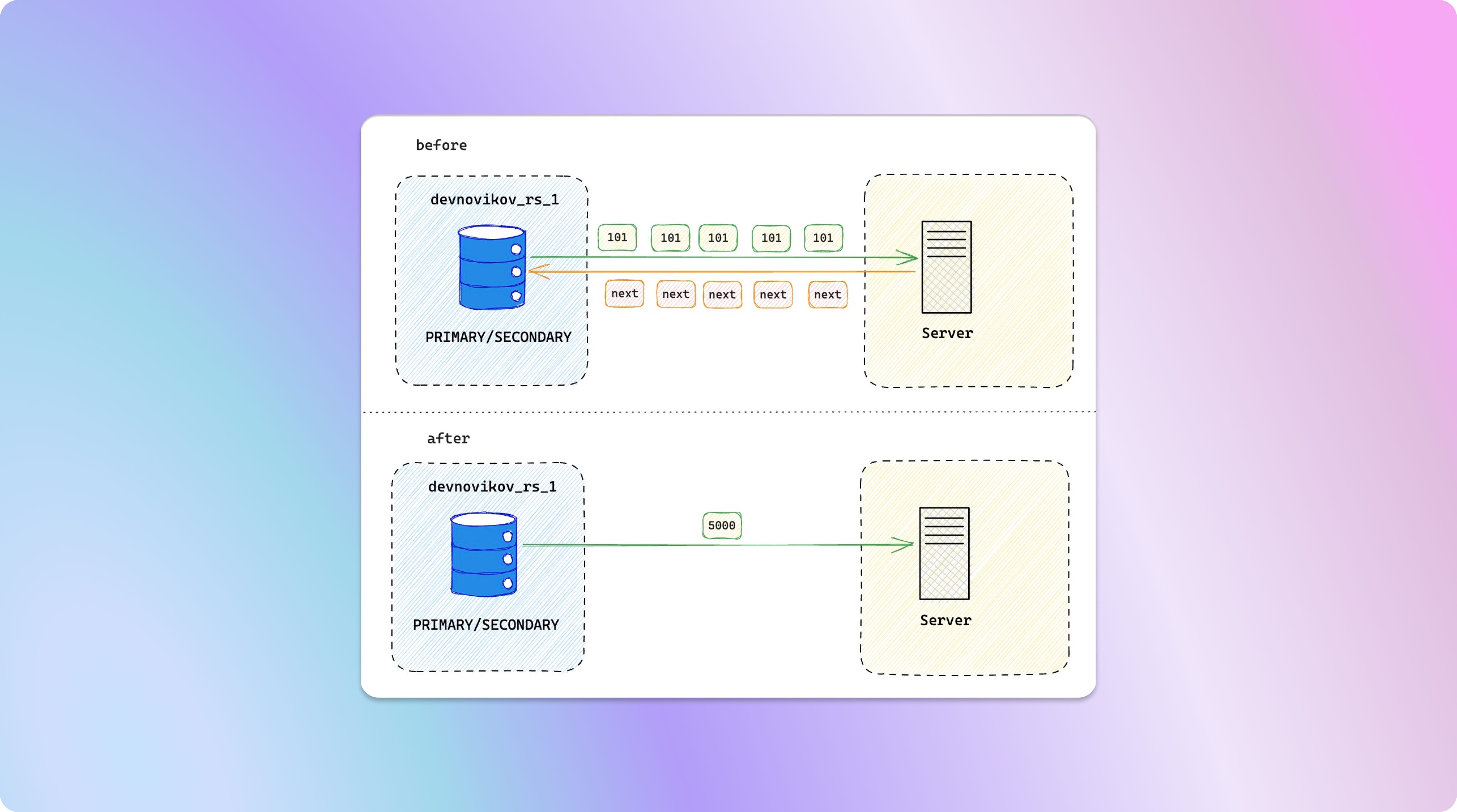
Размер пакета
Рассмотрите возможность настройки размера пакета, который управляет количеством результатов документа, возвращаемых в каждом обратном пути между клиентом и сервером базы данных. По по умолчанию для batchSize установлено значение 101.
Чтобы свести к минимуму количество циклов обработки и повысить производительность, увеличьте размер пакета, принимая во внимание доступную память как на исходном, так и на целевом серверах. Если доступно много ресурсов, больший размер пакета может быть полезен для оптимизации процесса миграции.
Крайне важно учитывать скорости чтения и записи скоростей в вашем приложении. Если скорость чтения значительно превышает скорость записи, могут возникнуть узкие места и потенциальные сбои памяти или приложения сбои .
Более того, при выборе параметра пакетного размера будьте внимательными к изменчивости размеров документа внутри разных коллекции. Некоторые коллекции могут содержать большие и сложные документы, тогда как другие содержат меньшие по размеру документы. Адаптация параметра batchSize для учета этих изменений важна для достижения эффективной миграции данных (попробуйте изменить значение и понаблюдать за эффектом; рассмотрите возможность установки его, например, на 5000).
Пропускная способность сети и сжатие
Проверьте пропускную способность сети. Он измеряет объем данных, которые могут быть переданы по сети за определенный промежуток времени. Вполне возможно, что максимальная пропускная способность будет достигнута в процессе миграции данных, и в этом случае пропускная способность сети может стать узким местом, и ее следует увеличить.
Сжатие:Включение сжатия может помочь оптимизировать процесс данных передачи, особенно когда сеть пропускная способность является узким местом. Обычно это выглядит так (хотя может отличаться в зависимости от драйвера):
mongodb://<user>:<password>@<cluster-url>/?compressors=zstd
Я рекомендую использовать для сжатия zstd (но есть еще snappy, zlib). Для получения дополнительной сравнительной информации вы можете изучить соответствующие репозитории GitHub.
Код Python ниже демонстрирует сжатие данных, которого можно легко достичь с помощью библиотеки zstd:
import bson
import zstd
# Aleksei Novikov (devnovikov)
# Document compression using zstd library
order_document = {
"_id": "64c17d622e12ff1ac09de99a",
"user_id": "64c17f79b876377491d9e40b",
"country": "US",
"items": [
{"product_id": "64c18473e7f2cc9223ebc813", "quantity": 2},
{"product_id": "64c18473e7f2cc9223ebc816", "quantity": 1},
],
"total_price": 149.99,
"shipping_address": {
"street": "456 Main St",
"city": "New York",
"country": "USA"
}
}
# Convert Document to bson
bson_data = bson.encode(order_document)
# Compression
compressed_data = zstd.compress(bson_data)
print("Original BSON Document Size:", len(bson_data))
print("Compressed Data Size:", len(compressed_data))
# Output
# Original BSON Document Size: 335
# Compressed Data Size: 232
Кэширование
Кэшируйте данные, к которым вы будете часто обращаться, на сервере приложений. Это особенно полезно, если у вас слабо денормализованные данные и структура данных больше похожа на SQL с внешними ключами, и вы хотите сделать что-то вроде JOIN.
Как мы помним, мы хотим перенести все данные, относящиеся к Индии, в другие страны. ниже. Если мы кешируем, например, user_id, мы сможем быстро получить все необходимые данные для конкретных пользователей, если они релевантны. индексы в других коллекциях. То есть, если у вас есть 50 таблиц, в которых используется user_id, вы можете эффективно получить необходимые записи. Более того, вы можете распараллелить передачу данных по N экземплярам. Кроме того, по разным причинам может не быть явного разделения по полю страны, но может существовать user_id, с помощью которого можно эффективно получить необходимые данные.
Асинхронный драйвер
Использовать асинхронный драйвер: Асинхронный драйвер позволяет выполнять неблокирующие операции, что означает, что вы можете выполнять несколько баз данных операций одновременно без ожидания завершения каждой операции перед началом следующей.
Операции массовой записи
Использовать операции массовой записи. Вместо выполнения отдельных операций вставки или обновления используйте операции массовой записи, такие как insertMany() или bulkWrite() для . >группировать несколько операций вместе. Это может значительно сократить количество обменов между клиентом и сервером и повысить общую скорость миграции. .

Ребалансировка общего кластера
Остановить ребалансировку данных в общем кластере: Остановить балансировщик необходимо во время миграции данных, чтобы предотвратить данные фрагменты от перемещения между осколками во время процесса миграции. Это гарантирует данные согласованность во время процесса миграции и предотвращает устаревание или несогласованность данных в исходном и целевом сегментах. .
sh.stopBalancer()
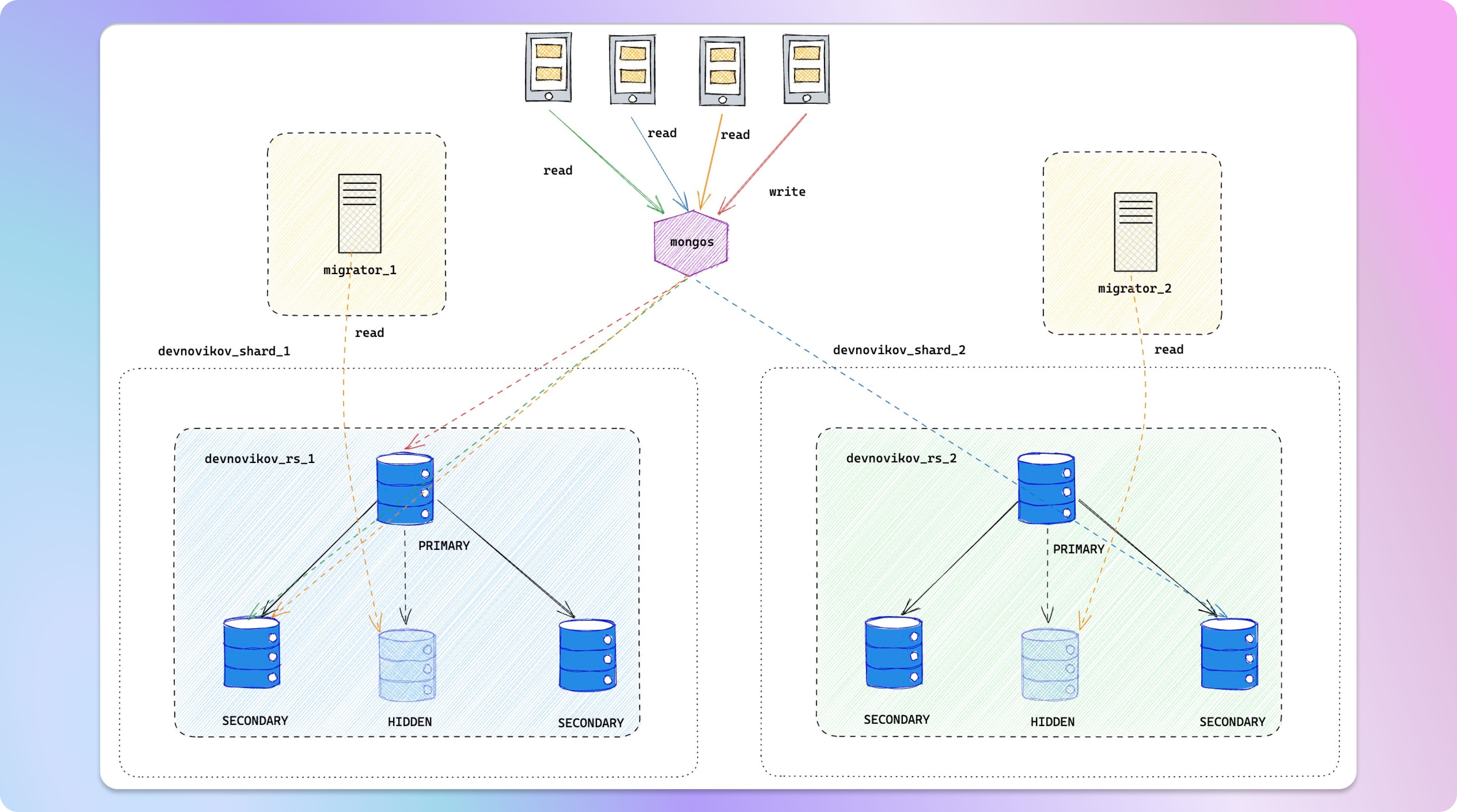
Прямые связи
Чтение напрямую из набора реплик, если существует узкое место в mongos при получении данных из сегментированного кластера. Имейте в виду, что при чтении данных из вторичной реплики может не быть полностью соответствующим -date (в конечном итоге соответствует). Чтобы прочитать данные из вторичной реплики, настройте параметр readPreference=secondary.
Но что если ваши вторичные реплики уже испытывают значительную перегрузку ?
Стандартная и рекомендуемая практика добавления скрытого узла в набор реплик:
rs.add({ host: "hidden_hostname:port", priority: 0, hidden: true })
Как только скрытый узел будет добавлен, вы сможете напрямую подключиться к нему. Это позволяет вам получить все необходимые данные, не затрагивая производственные клиенты.
Вы можете получить подробную информацию о доступных членах набора реплик в сегментированном кластере, выполнив следующие команды на mongos:
use config db.shards.find()
Миграция разделов
Выполняйте параллельную передачу данных на нескольких машинах. Для достижения этой цели можно использовать множество различных стратегий. Например, вы можете равномерно разделить пользователей по user_id на количество доступных экземпляров. Кроме того, общие коллекции, не имеющие сегментного ключа, должны быть явно прикреплены равномерно между доступными ресурсами.
Подробнее
- В непиковые часы: Запланируйте миграцию данных в непиковые часы, когда сеть менее загружена. Это может освободить больше пропускной способности для процесса миграции и свести к минимуму помехи для обычных операций.
- Инициализация чанка. Если у вас очень большая коллекция со значительным объемом данных, указание numInitialChunks может помощь. распределите исходные данныеболее равномерно по сегментам. Это может предотвратить появление горячих точек на определенных шардах и обеспечить сбалансированное распределение с самого начала. Я рекомендую выполнить тестовую миграцию, а затем посмотреть, сколько фрагментов потребуется для ваших данных.
- Будьте проще: может быть, вам будет достаточно Восстановления на момент времени (PITR)? Это может быть простой и эффективный подход к миграции данных или резервному копированию в MongoDB, особенно в сценариях, где у вас нет очень больших баз данных. PITR позволяет вам создать снимок резервную копию ваших данных в >конкретную точку во времени и затем применить изменения из oplog > чтобы обновить новый экземпляр. Вы можете начать использовать новые базы данных с дополнительными данными, а затем удалить их.
- ESR (равенство, сортировка, диапазон): при работе с составными индексами помните правила ESR. Это помогает определить порядок полей, чтобы максимизировать его эффективность для разных типов запросов.
- Настройка механизма хранения WiredTiger: вы можете увеличить размер кеша размер (wiredTigerCacheSizeGB) до храните больше данных в памяти, сокращая объем дискового ввода-вывода во время миграции. Но в последней версии mongodb по умолчанию все достаточно хорошо. Вам следует хотя бы поэкспериментировать с этим вариантом.
- Изменить настройки записи. Возможно, большинство пользователей пишут по умолчанию. Если возможно, рассмотрите использование функции меньшей записи во время миграции
(только w: 0 → если вы на 100 процентов уверены, что нет дублирующейся ошибки ключа или других нарушений ограничений, в противном случае w: 1) чтобы уменьшить ожидание время для подтверждения. - Потоки изменений. Используйте потоки изменений в своей стратегии миграции в соответствии со своими потребностями. Например, вы можете перенести все данные из скрытых, проиндексировать их и после этого начинать с последней принятой записи в oplog. Для этой цели существует другая опция, например «startAfter», которая позволяет указать токен возобновления для запуска потока изменений с определенной точки в оплоге. Если указанная начальная точка находится в прошлом, она должна находиться во временном диапазоне оплога. Чтобы проверить временной диапазон оплога, см.
rs.printReplicationInfo()
На сегодня всё! :)
Если вам нравится мой контент и вы хотите поддержать мою работу, можете подарить мне чашечку кофе ☕️ 🥰
Есть вопрос? Не стесняйтесь обратиться ко мне:
- LinkedIn:девновиков