Оптимизация оркестрации рабочих процессов больших данных.

Курсы по требованию | рекомендуемые
Некоторые из моих читателей обратились ко мне с просьбой о курсах по запросу, которые помогут вам СТАТЬ солидным инженером данных. Вот три замечательных ресурса, которые я бы порекомендовал:
- Нанотехнология обработки данных (UDACITY)
- Потоковая передача данных с помощью Apache Kafka и Apache Spark наноуровне (UDACITY)
- Spark и Python для больших данных с помощью PySpark (UDEMY)
Еще не являетесь участником Medium? Рассмотрите возможность регистрации по моей реферальной ссылке, чтобы получить доступ ко всему, что может предложить Medium, всего за 5 долларов в месяц!
Введение
В динамичной среде разработки и анализа данных построение масштабируемых и автоматизированных конвейеров имеет первостепенное значение.
Энтузиасты Spark, которые некоторое время работали с Airflow, могут задаться вопросом:
Как выполнить задание Spark на удаленном кластере с помощью Airflow?
Как автоматизировать конвейеры Spark с помощью AWS EMR и Airflow?
В этом уроке мы собираемся объединить эти две технологии, показав, как:
- Настройте и получите необходимые параметры из пользовательского интерфейса Airflow.
- Создайте вспомогательные функции для автоматического создания предпочтительной команды
spark-submit. - Используйте метод
EmrAddStepsOperator()Airflow для создания задачи, которая отправляет и выполняет задание PySpark в EMR. - Используйте метод
EmrStepSensor()Airflow для мониторинга выполнения скрипта.
Код, используемый в этом руководстве, доступен на GitHub.
Предварительные условия
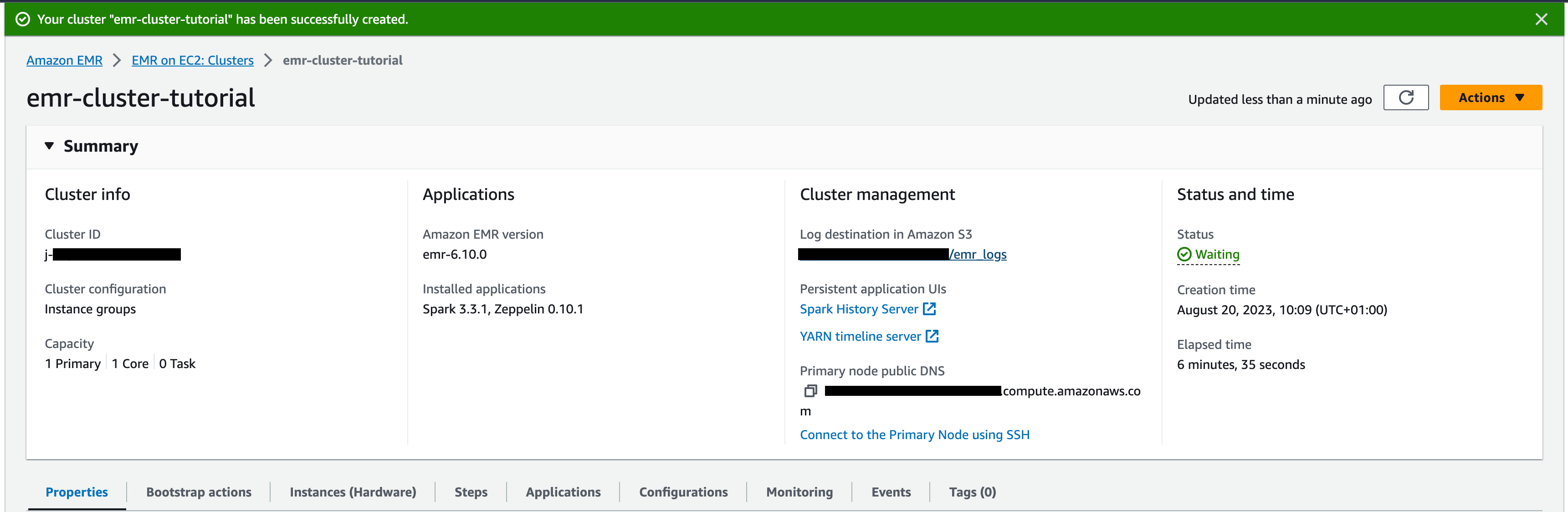
- Учетная запись AWS с корзиной S3 и кластером EMR, настроенная в том же регионе (в данном случае
eu-north-1). Кластер EMR должен быть доступен и находиться в состоянииWAITING. В нашем случае он получил имяemr-cluster-tutorial:
- Некоторые ложные данные
balancesуже доступны в сегментеS3под…