Машинное обучение — это область исследования и применения, которая включает разработку алгоритмов и моделей, которые позволяют компьютерам учиться и делать прогнозы или решения без явного программирования. Это подмножество искусственного интеллекта (ИИ), основанное на идее о том, что машины могут учиться на данных и со временем улучшать свою производительность.
Теория машинного обучения:
- Обучение с учителем. При этом подходе машина учится на помеченных данных, где каждый входной пример связан с соответствующим целевым значением. Цель состоит в том, чтобы изучить функцию отображения, которая может предсказывать целевое значение для новых, невидимых входных данных.

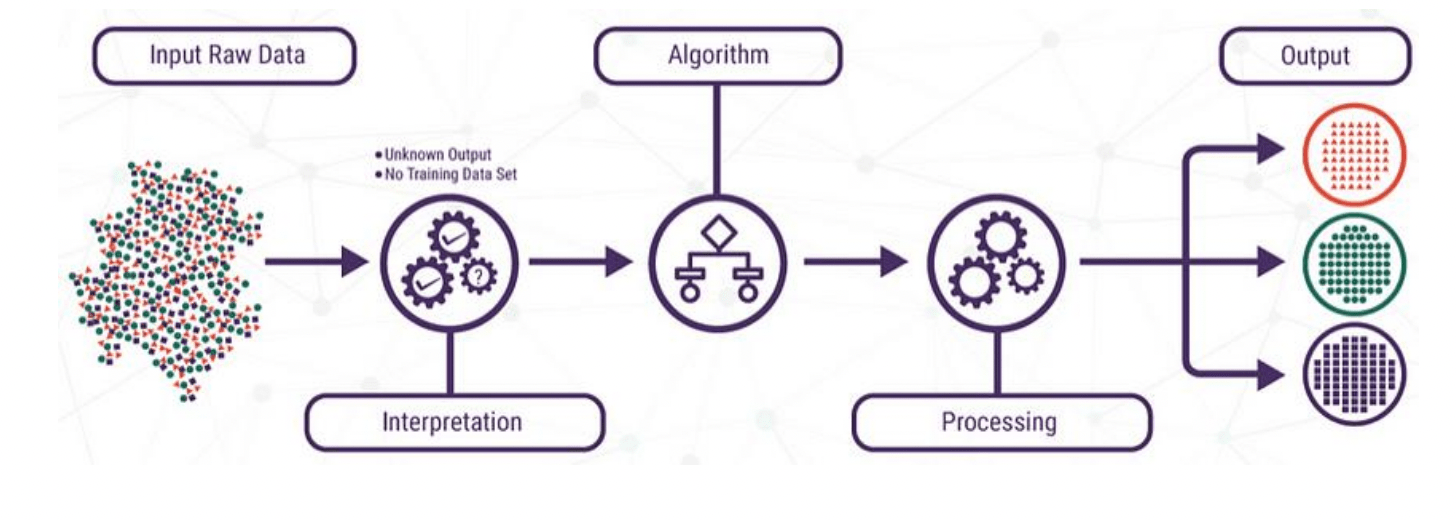
2. Обучение без учителя. При обучении без учителя машина учится на немаркированных данных, стремясь обнаружить закономерности или взаимосвязи в данных без какой-либо конкретной целевой переменной. Кластеризация и уменьшение размерности являются распространенными методами обучения без учителя.
3. Обучение с подкреплением. Этот подход предполагает обучение агента взаимодействию с окружающей средой и освоению оптимальных действий методом проб и ошибок. Агент получает обратную связь в виде вознаграждений или штрафов в зависимости от своих действий.

4. Глубокое обучение.Глубокое обучение — это раздел машинного обучения, который фокусируется на разработке многоуровневых нейронных сетей. Эти сети способны изучать сложные шаблоны и представления данных.

Преимущества машинного обучения:
• Автоматизация. Машинное обучение позволяет автоматизировать задачи, которые в противном случае потребовали бы ручных усилий и принятия решений.
• Обработка сложных данных. Алгоритмы машинного обучения могут обрабатывать и извлекать ценную информацию. из больших и сложных наборов данных.
• Повышенная точность: модели машинного обучения могут делать точные прогнозы или решения на основе закономерностей и связей, обнаруженных в данных.
• Адаптивность: Модели машинного обучения могут адаптироваться и улучшать свою производительность с течением времени по мере поступления новых данных.
Недостатки машинного обучения:
•Зависимость от данных. Модели машинного обучения во многом зависят от качества и количества доступных данных. Недостаточные или предвзятые данные могут привести к неточным или несправедливым прогнозам.
• Отсутствие способности объяснять:Некоторые алгоритмы машинного обучения, такие как глубокие нейронные сети, часто считаются черными ящиками, что затрудняет понимание. обоснование своих решений.
• Переоснащение:модели машинного обучения могут стать чрезмерно специализированными на обучающих данных, что приводит к снижению производительности на новых, невидимых данных.
• Вычислительные возможности Требования: Сложные модели машинного обучения, особенно модели глубокого обучения, требуют значительных вычислительных ресурсов и времени на обучение.
Приложения машинного обучения:
• Распознавание изображений и речи. Алгоритмы машинного обучения используются в таких приложениях, как распознавание лиц, обнаружение объектов и преобразование речи в текст.
• Обработка естественного языка: Методы машинного обучения обеспечивают языковой перевод, анализ настроений, чат-боты и генерацию текста.
• Системы рекомендаций. Системы рекомендаций на основе машинного обучения используются в электронной коммерции, потоковых сервисах и персонализации контента.
• Обнаружение мошенничества. Модели машинного обучения могут обнаруживать закономерности мошеннического поведения при финансовых транзакциях и отмечать подозрительные действия.
Ключевые темы машинного обучения:
- Метрики оценки. Метрики оценки измеряют эффективность моделей машинного обучения. Общие показатели включают точность, прецизионность, полноту, показатель F1, среднеквадратическую ошибку (MSE) и площадь под кривой рабочей характеристики приемника (AUC-ROC).
• Регрессия: Алгоритмы регрессии используется для прогнозирования непрерывных числовых значений на основе входных переменных.
• Классификация: Алгоритмы классификации используются для присвоения примеров входных данных предопределенным категориям или классам.

Кластеризация.Алгоритмы кластеризации группируют схожие точки данных на основе их характеристик.

- Уменьшение размерности.Эти методы направлены на уменьшение количества входных переменных при сохранении важной информации.
• Ансамбльное обучение: Ансамбльное обучение объединяет несколько моделей машинного обучения для прогнозирования или решения. Он повышает точность, уменьшает переобучение и включает в себя такие методы, как объединение в пакеты, повышение и накопление.
