Подключите Spring Boot к Elasticsearch

И Java, и Elasticsearch - популярные элементы в общих технологических стеках, которые используют компании. Java - это язык программирования, выпущенный еще в 1996 году. Java принадлежит Oracle и все еще находится в активной разработке.
Elasticsearch - молодая технология по сравнению с Java - она была выпущена только в 2010 году (что на 14 лет моложе Java). Он быстро набирает популярность и сейчас используется во многих компаниях в качестве поисковой системы.
Видя, насколько популярны и те и другие, многие люди и компании хотят связать Java с Elasticsearch, чтобы разработать свою собственную поисковую систему. В этой статье я хочу научить вас, как подключить Java Spring Boot 2 к Elasticsearch. Мы узнаем, как создать API, который будет вызывать Elasticsearch для получения результатов.
Подключение Java с помощью Elasticsearch
Первое, что мы должны сделать, это подключить наш проект Spring Boot к Elasticsearch. Самый простой способ сделать это - использовать клиентскую библиотеку, предоставляемую Elasticsearch, которую мы можем просто добавить в наш менеджер пакетов (например, Maven или Gradle).
В этой статье мы будем использовать spring-data-elasticsearch библиотеку, предоставленную Spring Data, которая также включает клиентскую библиотеку высокого уровня Elasticsearch.
Запуск нашего проекта
Начнем с создания нашего проекта Spring Boot с Spring Initialzr. Я настрою свой проект так, как показано на рисунке ниже, поскольку мы собираемся использовать высокоуровневый клиент. Затем мы можем использовать удобную библиотеку, предоставляемую Spring, Spring Data Elasticsearch:
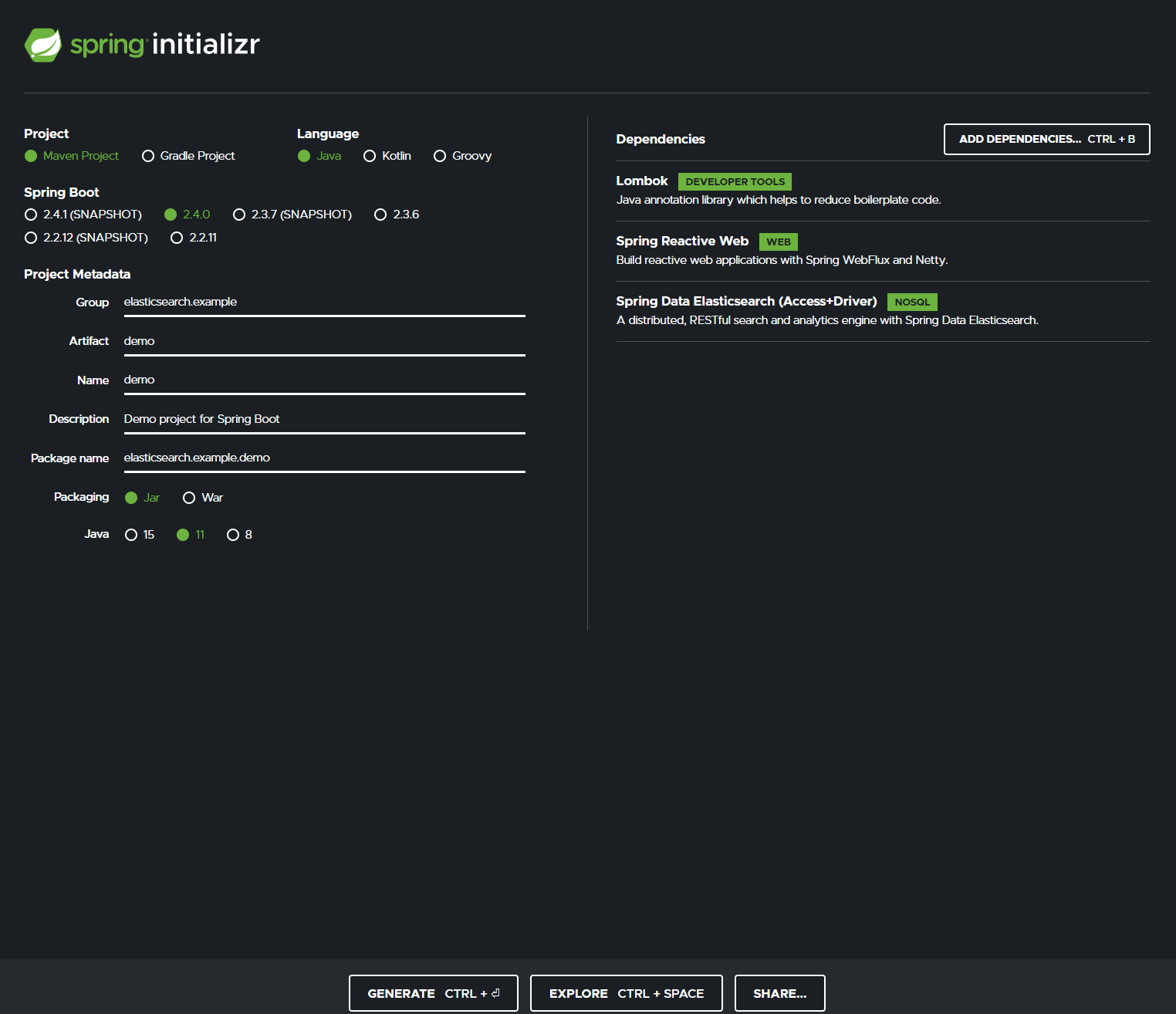
Добавление зависимости к Spring Data Elasticsearch
Если вы следовали моей конфигурации Spring Initialzr в предыдущем разделе, значит, у вас уже должна быть клиентская зависимость Elasticsearch в вашем проекте. Но если вы этого не сделаете, вы можете добавить его:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>Создание bean-компонента клиента Elasticsearch
Есть два метода инициализации bean-компонента: вы можете использовать bean-компоненты, определенные в библиотеке Spring Data Elasticsearch, или создать свой собственный bean-компонент.
Более простой вариант - использовать bean-компонент, настроенный Spring Data Elasticsearch.
Например, вы можете добавить эти свойства в свой application.properties:
spring.elasticsearch.rest.uris=localhost:9200
spring.elasticsearch.rest.connection-timeout=1s
spring.elasticsearch.rest.read-timeout=1m
spring.elasticsearch.rest.password=
spring.elasticsearch.rest.username=Второй метод предполагает создание собственного bean-компонента. Вы можете настроить параметры, создав bean-объект RestHighLevelClient. Если компонент существует, Spring Data будет использовать его в качестве своей конфигурации.
Тестирование подключения нашего приложения Spring Boot к Elasticsearch
Теперь, когда вы настроили компонент, ваше приложение Spring Boot и Elasticsearch должны быть подключены. Поскольку мы собираемся проверить соединение, убедитесь, что ваш Elasticsearch запущен и работает!
Чтобы проверить это, мы можем создать bean-компонент, который будет создавать индекс в Elasticsearch в файле DemoApplication.java. Класс будет выглядеть так:
Хорошо, в этом коде мы дважды вызывали Elasticsearch с RestHighLevelClient,, о чем мы узнаем позже в этой статье. Первый вызов - удалить индекс, если он уже существует. Мы использовали _8 _ / _ 9_, потому что, если индекс не существует. Затем elasticsearch выдаст ошибку, что приведет к сбою процесса запуска нашего приложения.
Второй вызов - создать индекс. Поскольку я использую только одноузловой Elasticsearch, я настроил шарды на 1, а реплики на 0.
Если все прошло нормально, вы должны увидеть индексы при проверке Elasticsearch. Чтобы проверить это, просто перейдите на http://localhost:9200/_cat/indices?v, и вы увидите список индексов в своем Elasticsearch:
Поздравляю! Вы просто подключаете свое приложение к Elasticsearch !!
Другие способы подключения
Я рекомендую вам использовать библиотеку spring-data-elasticsearch, если вы хотите подключиться к Elasticsearch с помощью Java. Но если вы не можете использовать эту библиотеку, есть другой способ подключить ваши приложения к Elasticsearch.
Клиент высокого уровня
Как мы знаем из предыдущего раздела, spring-data-elasticsearch библиотека, которую мы использовали, также включает клиент высокого уровня Elasticsearch. Если вы уже импортировали spring-data-elasticsearch, вы уже можете использовать клиент высокого уровня Elasticsearch.
При желании также можно использовать клиентскую библиотеку высокого уровня напрямую, без зависимости от Spring Data. Вам просто нужно добавить эту зависимость в свой диспетчер зависимостей:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>8.0.0</version>
</dependency>Мы также будем использовать этот клиент в наших примерах, потому что функциональность в клиенте высокого уровня более полная, чем у spring-data-elasticsearch.
Для получения дополнительной информации вы можете прочитать Документацию по Elasticsearch.
Клиент низкого уровня
Вам будет сложнее с этой библиотекой, но вы можете настроить ее больше. Чтобы использовать его, вы можете добавить следующую зависимость:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.0.0</version>
</dependency>Для получения дополнительной информации вы можете прочитать об этом Документацию Elasticsearch.
Транспортный клиент
Elasticsearch также предоставляет транспортный клиент, который позволяет идентифицировать ваше приложение как один из узлов Elasticsearch. Я не рекомендую этот метод, потому что он скоро станет нерекомендуемым.
Если вам интересно, вы можете прочитать о транспортном клиенте здесь.
REST звонок
Последний способ подключиться к Elasticsearch - выполнить вызов REST. Поскольку Elasticsearch использует REST API для подключения к своему клиенту, вы можете использовать REST-вызов для подключения своих приложений к Elasticsearch. Вы можете использовать OkHttp, Feign или свой веб-клиент для подключения своих приложений к Elasticsearch.
Я также не рекомендую этот метод, потому что это неудобно. Поскольку Elasticsearch уже предоставляет клиентские библиотеки, лучше использовать их. Используйте этот метод, только если у вас нет другого способа подключиться.
Использование Spring Data Elasticsearch
Во-первых, давайте узнаем, как использовать spring-data-elasticsearch в нашем проекте Spring. spring-data-elasticsearch очень проста в использовании и представляет собой высокоуровневую библиотеку, которую мы можем использовать для доступа к Elasticsearch.
Создание объекта и настройка нашего индекса
После того, как вы подключили свои приложения к Elasticsearch, пришло время создать объект! С помощью Spring Data мы можем добавить метаданные к нашей сущности, которые будут считываться созданным нами bean-компонентом репозитория. Таким образом, код будет намного чище и быстрее разрабатываться, поскольку нам не нужно будет создавать какую-либо логику сопоставления на нашем уровне обслуживания.
Давайте создадим объект под названием Product:
Итак, позвольте мне объяснить, что происходит в приведенном выше блоке кода. Во-первых, я не буду рассказывать о @Data, @AllArgsConstructor, @NoArgsConstructor и @Builder. Это аннотации из библиотеки Lombok для constructor, getter, setter, builder и других вещей.
Теперь поговорим о первой аннотации данных Spring в объекте @Document. Аннотация @Document показывает, что класс - это объект, содержащий метаданные настройки индекса Elasticsearch. Чтобы использовать репозиторий Spring Data, о котором мы узнаем позже, аннотация @Document является обязательной.
Единственная аннотация, которая является обязательной в @Document, - это indexName. Это должно быть довольно ясно из названия - мы должны заполнить его именем индекса, которое мы хотим использовать для объекта. В этой статье мы будем использовать то же имя, что и объект, product.
Второй параметр @Document, о котором следует поговорить, - это параметр createIndex. Если вы установите createIndex как true, ваши приложения будут автоматически создавать индекс при запуске приложений, если индекс еще не существует.
Параметры shards, replicas и refreshInterval определяют настройки индекса при его создании. Если вы измените значения этих параметров после того, как индекс уже создан, настройки не будут применены. Таким образом, параметры будут использоваться только при создании индекса в первый раз.
Если вы хотите использовать собственный идентификатор в Elasticsearch, вы можете использовать аннотации @Id. Если вы используете аннотации @Id, Spring Data сообщит Elasticsearch о необходимости сохранения идентификатора в документе и источнике документа.
Тип @Field будет определять отображение поля поля. Как и shards, replicas и refreshInterval, тип @Field будет влиять на Elasticsearch только при первом создании индекса. Если вы добавите новое поле или измените типы, когда индекс уже создан, это ничего не сделает.
Теперь, когда мы настроили сущность, давайте попробуем автоматическое создание индекса с помощью Spring Data! Когда мы настроим createIndex как true, Spring Data проверит, существует ли индекс в Elasticsearch. Если его не существует, Spring Data создаст индекс с конфигурацией, которую мы создали в сущности.
Запустим наше приложение. После того, как он запустится, давайте проверим настройки и посмотрим, верны ли они:
curl --request GET \
--url http://localhost:9200/product/_settingsРезультат:
Все как мы настроили! refresh_interval имеет значение 5s, number_of_shards - 1, а number_of_replicas - 0.
Теперь давайте проверим сопоставления:
curl --request GET \
--url http://localhost:9200/product/_mappingsРезультат:
Отображения также соответствуют нашим ожиданиям. Это то же самое, что мы настроили в классе сущности.
Базовый CRUD с интерфейсом репозитория Spring Data
После того, как мы создали объект, у нас есть все необходимое для создания интерфейса репозитория в Spring Boot. Давайте создадим репозиторий под названием ProductRepository.
При создании интерфейса не забудьте расширить ElasticsearchRepository<T, U>. В этом случае объект T - это ваша сущность, а тип объекта U, который вы хотите использовать для идентификатора данных. В нашем случае мы будем использовать сущность Product, которую мы создали ранее, как T и String как U.
Теперь, когда интерфейс вашего репозитория готов, вам не нужно заботиться о реализации, потому что Spring позаботится об этом. Теперь вы можете вызывать любую функцию в классах, на которые распространяется ваш репозиторий.
Примеры CRUD можно найти в приведенном ниже коде:
В приведенных выше блоках кода мы создали класс обслуживания с именем SpringDataProductServiceImpl, который автоматически подключается к ProductRepository, который мы создали ранее.
В нем четыре основные функции CRUD. Первый - createProduct, который, как следует из названия, создаст новый продукт в индексе product. Второй, getProduct, получает проиндексированный нами продукт по его идентификатору. Функцию deleteProduct можно использовать для удаления продукта в индексе по идентификатору. Функция insertBulk позволит вам вставить несколько продуктов в Elasticsearch.
Все готово! Я не буду писать о тестировании API в этой статье, потому что хочу сосредоточиться на том, как наши приложения могут взаимодействовать с Elasticsearch. Но если вы хотите попробовать API, я оставил ссылку на GitHub в конце статьи, чтобы вы могли клонировать и опробовать этот проект.
Пользовательские методы запроса в Spring Data
В предыдущем разделе мы использовали только основные методы, которые уже определены в других классах. Но мы также можем создавать собственные методы запросов для использования.
Что очень удобно в Spring Data, так это то, что вы можете создать метод в интерфейсе репозитория, и вам не нужно кодировать какую-либо реализацию. Библиотека Spring Data прочитает репозиторий и автоматически создаст для него реализации.
Попробуем найти товары по полю name:
Да, это все, что вам нужно сделать, чтобы создать функцию в интерфейсе репозитория Spring Data.
Вы также можете определить собственный запрос с аннотацией @Query и вставить запрос JSON в параметры.
Оба созданных нами метода делают одно и то же - используют запрос match с name в качестве параметра. Если вы попробуете, то получите те же результаты.
Использование ElasticsearchRestTemplate
Если вы хотите выполнить более сложный запрос, например агрегирование, выделение или предложения, вы можете использовать ElasticsearchsearchRestTemplate, предоставленный библиотекой данных Spring. Используя его, вы можете создать свой собственный запрос, сделав его настолько сложным, насколько захотите.
Например, давайте создадим функцию для выполнения match запроса к полю name, как и раньше:
Вы должны заметить, что приведенный выше код более сложен, чем тот, который мы определили в ElasticserchRepository. По возможности рекомендуется использовать репозиторий Spring Data. Но для более сложных запросов, таких как агрегирование, выделение или предложения, вы должны использовать ElasticsearchRestTemplate.
Например, давайте напишем небольшой код, который объединит термин:
Elasticsearch RestHighLevelClient
Если вы не используете Spring или ваша версия Spring не поддерживает spring-data-elasticsearch, вы можете использовать библиотеку Java, разработанную Elasticsearch, RestHighLevelClient.
RestHighLevelClient - это библиотека, которую вы можете использовать для выполнения основных задач, таких как CRUD или управления Elasticsearch. Несмотря на то, что название подразумевает, что это высокий уровень, на самом деле это более низкий уровень по сравнению с spring-data-elasticsearch.
Преимущество этой библиотеки перед Spring Data в том, что с ее помощью вы также можете управлять своим Elasticsearch. Он предоставляет индекс и конфигурацию Elasticsearch, которую вы можете использовать с большей гибкостью по сравнению со Spring Data. Он также имеет более полную функциональность для взаимодействия с Elasticsearch.
Недостатком этой библиотеки над Spring Data является то, что эта библиотека находится на более низком уровне, что означает, что вам нужно больше кодировать.
CRUD с RestHighLevelClient
Давайте посмотрим, как мы можем создать простую функцию с библиотекой, чтобы мы могли сравнить ее с предыдущими методами, которые мы использовали:
Как видите, теперь это сложнее и труднее реализовать. Теперь вам нужно обработать исключение, а также преобразовать результат JSON в вашу сущность. Вместо этого рекомендуется использовать Spring Data для основных операций CRUD, поскольку RestHighLevelClient более сложен.
Я включил другие функции CRUD в проект GitHub. Если интересно, можете проверить. Ссылка в конце статьи.
Создание индекса
В этом разделе RestHighLevelClient имеет явное преимущество по сравнению с Spring Data Elasticsearch. Когда мы создавали индекс с его сопоставлениями и настройками в предыдущем разделе, мы использовали только аннотации. Это очень легко сделать, но с этим ничего не поделаешь.
С RestHighLevelClient вы можете создавать методы для управления индексами или практически все, что позволяет Elasticsearch REST API.
Например, давайте напишем код, который создаст индекс product с настройками и сопоставлениями, которые мы использовали ранее:
Итак, давайте посмотрим, что мы сделали в коде:
- Мы инициализировали
createIndexRequest, когда также определяли имя индекса. - Добавили настройки в запрос при звонке
createIndexRequest.settings. В настройках мы также настроили полеindex.requests.cache.enable, что невозможно с библиотекой Spring Data. - Мы сделали
Map, содержащий свойства и сопоставления полей в индексе. - Мы позвонили в Elasticsearch с
restHighlevelClient.indices.create.
Как видите, с RestHighLevelClient мы можем создать более настраиваемый вызов для создания индекса для Elasticsearch по сравнению с аннотациями в объекте Spring Data. В RestHighLevelClient также есть дополнительные функции, которых нет в библиотеке Spring Data. Вы можете прочитать Документацию Elasticsearch для получения дополнительной информации о библиотеке.
Заключение
В этой статье мы узнали о двух способах подключения к Elasticsearch: с помощью Spring Data и через клиент Elasticsearch. Обе библиотеки являются мощными библиотеками, но вы должны использовать Spring Data только в том случае, если это возможно для вашего варианта использования. Код Spring Data Elasticsearch более читабелен и проще в использовании.
Если вам нужна более мощная библиотека, которая может делать все, что позволяет Elasticsearch, вы также можете использовать клиент высокого уровня Elasticsearch. Вы также можете использовать низкоуровневый клиент, который мы не рассматривали в этой статье, если вам нужны еще более мощные функции.
Я также хотел бы поблагодарить вас за чтение этой статьи, и я надеюсь, что эта статья поможет вам начать работу с Elasticsearch в Java Spring Boot. Если вы хотите узнать больше о библиотеках, вы можете ознакомиться с документацией Spring Data Elasticsearch и документацией по высокоуровневому клиенту Elasticsearch.
Ниже приведена ссылка GitHub для проекта GitHub, используемого в этой статье:
Ранее опубликовано на codecurated.com.