Расширение возможностей ваших информационных панелей с помощью ИИ
Microsoft недавно предприняла решительные шаги по согласованию технологий с открытым исходным кодом и внедрению технологий искусственного интеллекта в свои продукты, и Power BI включен в этот план. Power BI - один из основных инструментов для создания панелей мониторинга сегодня, и Microsoft с каждым днем увеличивает возможности и гибкость разработки.
Чтобы сделать разработку панелей мониторинга возможной, Power BI имеет несколько функций для обработки данных, и одной из наиболее важных является инструмент интеграции с R, а в последнее время интеграция с Python. Возможность работы с языками разработки R и Python открывает огромный диапазон возможностей внутри инструмента бизнес-аналитики, и одна из этих возможностей - работать с инструментами машинного обучения и создавать модели непосредственно в Power BI.
В этой статье я пошагово расскажу, как обучать и делать прогнозы с помощью модели машинного обучения непосредственно в PowerBI, используя язык R, из следующих тем:
- Установка зависимостей
- Анализ данных
- Практика - код
- Результаты
- Вывод
1. Установка зависимостей
Первым шагом является установка R Studio на ваш компьютер, поскольку разработка будет вестись на языке R. Поскольку PowerBI имеет встроенную интеграцию с языком R, он требует, чтобы пользователь установил пакеты R.
Загрузить можно по этой ссылке: https://www.rstudio.com/products/rstudio/download/
Сразу после установки вы должны открыть R studio и установить библиотеки зависимостей.
- каретка
- наборы данных
- мономвн
Чтобы установить пакеты в R, на веб-сайте R-bloggers есть отличный учебник, который научит вас устанавливать и загружать пакеты в R Studio. Ссылка: https://www.r-bloggers.com/2013/01/how-to-install-packages-on-r-screenshots/
Анализ данных
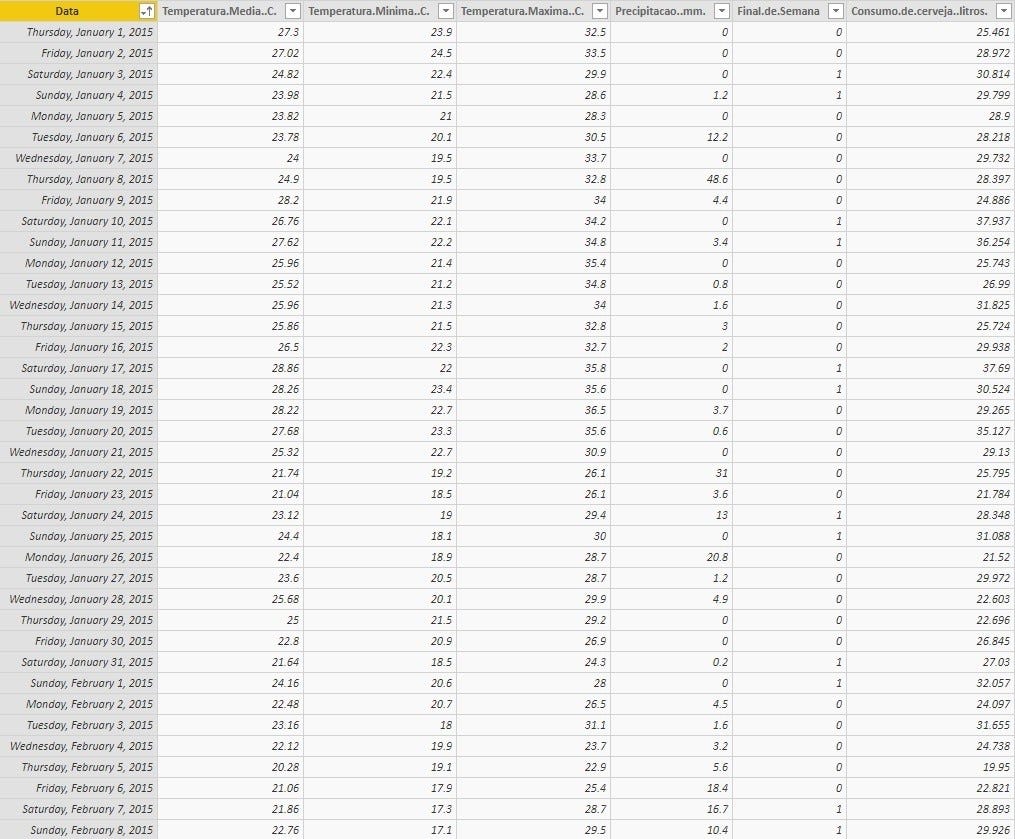
Набор данных был получен с веб-сайта kaggle.com и состоит из данных о потреблении пива в университете Сан-Паулу, а также минимальной, максимальной и средней температуры за каждый день и объемных осадков.
Чтобы добавить еще одну важную функцию, я создал столбец под названием «Выходные», который указывает, когда день суббота или воскресенье, чтобы немного учесть сезонность потребления, поскольку выходные представляют собой более высокое потребление, я мог бы также рассмотреть пятницу, но для В этот первый момент я решил быть более консервативным.
3 - Практическое руководство - Код
Для тестов я собрал байесовскую модель линейной регрессии с использованием пакета monomvn (регрессия Байесовского хребта), чтобы предсказать данные о потреблении пива в литрах в день, наряду с проверкой с помощью перекрестной проверки с 10-кратной проверкой.
Я не буду подробно останавливаться на модели и ее результатах в этой статье, поскольку цель состоит в том, чтобы сосредоточиться больше на интеграции с Power BI, чем на моделировании.
Первая часть кода импортирует библиотеки
library(caret) library(datasets) library(monomvn)
Сразу после импорта данных Power BI в виде набора данных внутри R
mydata <- dataset mydata <- data.frame(mydata)
С этим мы можем создать модель и выполнить прогноз. В этом случае я не определял набор тестовых данных, я просто использовал набор данных для обучения с проверкой CV10, чтобы кратко проанализировать показатели обучения.
fitControl <- trainControl( method = "repeatedcv", number = 10, repeats = 10) lmFit <- train(mydata[1:365, 2:6],mydata[1:365,7], method ='bridge',trControl = fitControl) predictedValues <- predict(lmFit,newdata = mydata[, 2:6])
Наконец, мы создали новый столбец в наборе данных PowerBI со значениями, сгенерированными прогнозом модели.
mydata$PredictedValues <- predictedValues
Полный код
library(caret) library(datasets) library(monomvn) mydata <- dataset mydata <- data.frame(mydata) fitControl <- trainControl( method = "repeatedcv", number = 10, repeats = 10) lmFit <- train(mydata[1:365, 2:6],mydata[1:365,7], method ='bridge',trControl = fitControl) predictedValues <- predict(lmFit,newdata = mydata[, 2:6]) mydata$PredictedValues <- predictedValues
4 - Результаты
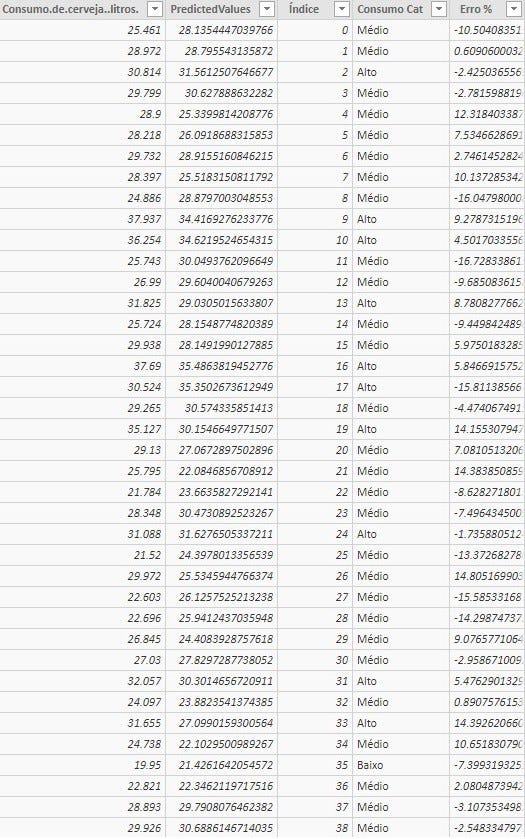
Ниже приведен полный набор данных с реальным значением, прогнозом и ошибкой (%). Средняя ошибка обучения составила 7,82% с максимумом 20,23% и минимумом 0,03%.
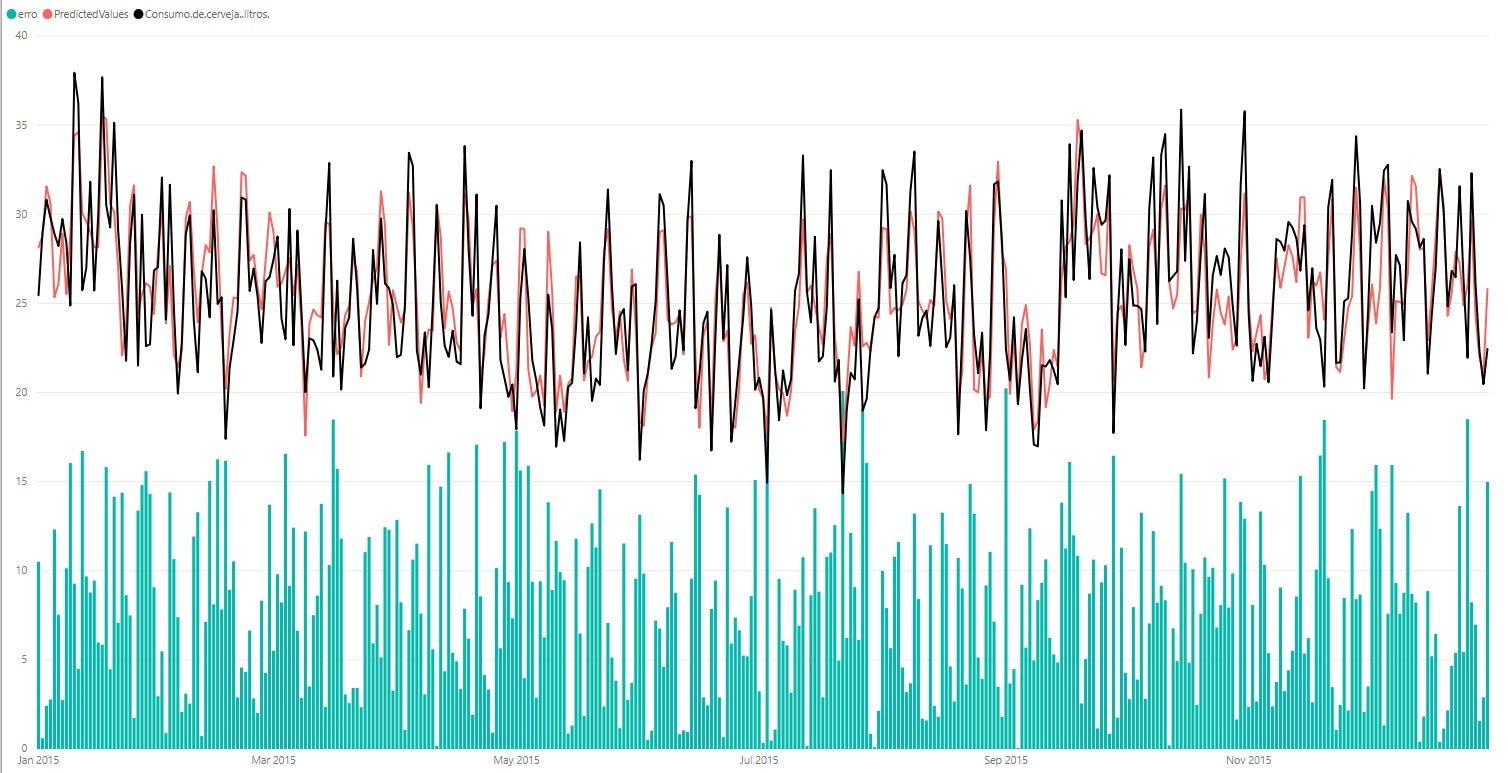
Ниже приведен график с реальными данными, выделенными черным цветом, и данными прогноза, выделенными красным, в дополнение к ошибкам в синих столбцах за весь период тестирования.
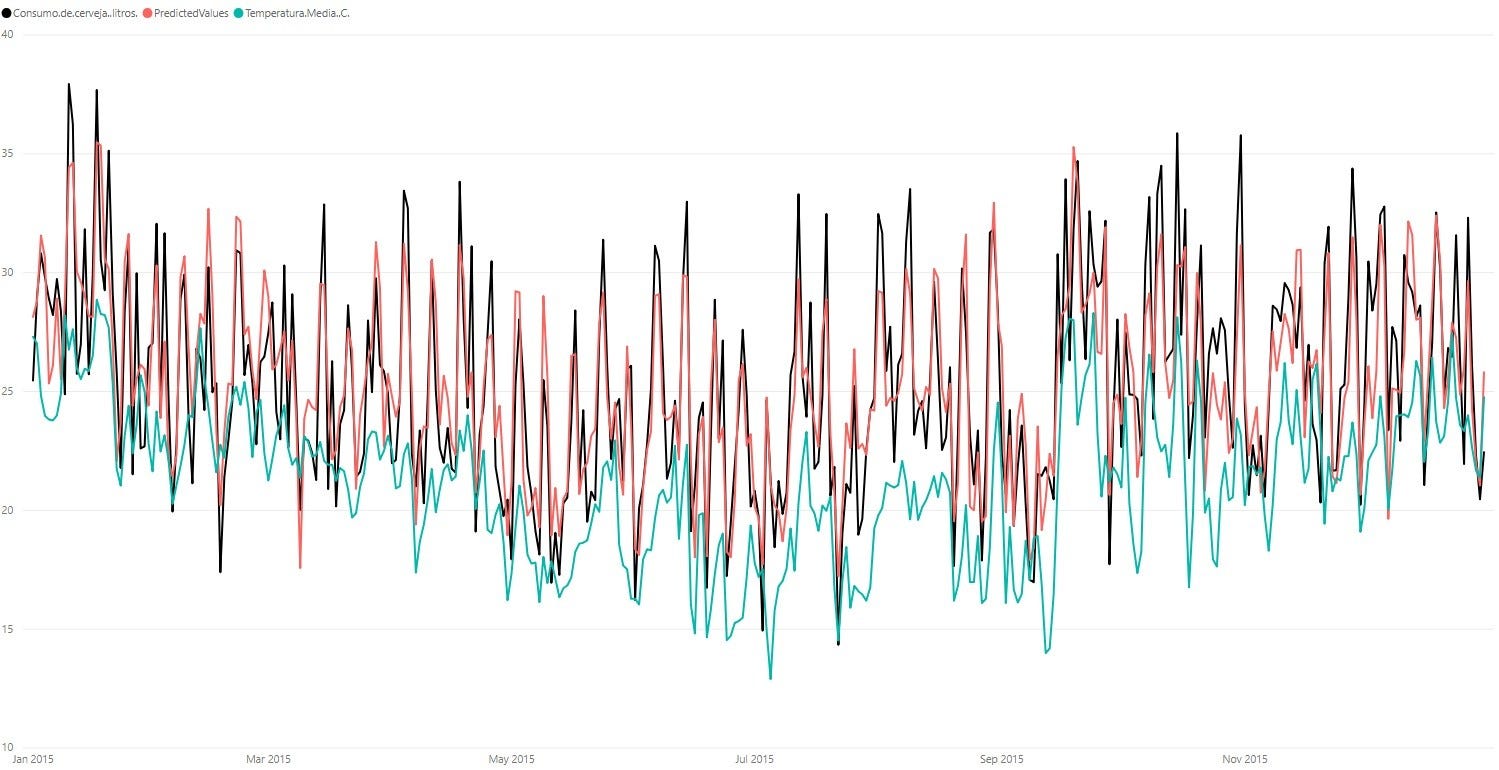
4.1 - Корреляция с температурой
При нанесении на график потребления пива (черный / красный) с температурой (синий) мы видим, что потребление хорошо соответствует колебаниям температуры между месяцами, как «микро» (дневным) колебаниям, так и «макро» (трендам) изменение температуры. Мы видим, что повышение температуры приводит к увеличению потребления, например, в конце и начале года, когда у нас лето, а более низкая температура зимой приводит к снижению потребления пива в SP.
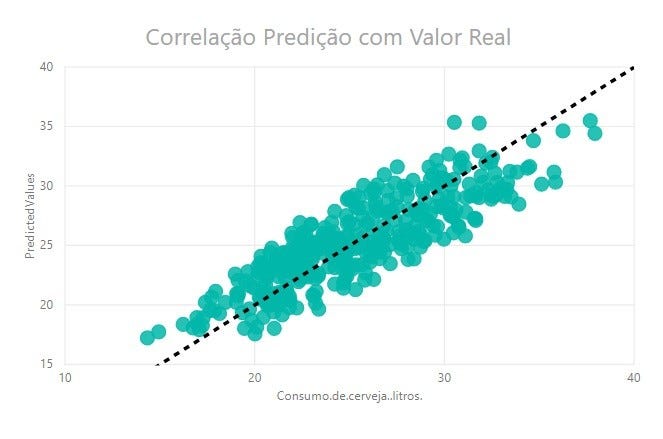
4.2. Корреляция между реальными данными и прогнозом
Применяя корреляцию между реальными значениями и значениями, предсказанными моделью, мы могли бы в идеале получить данные, сконцентрированные в черной пунктирной линии (график ниже), в сценарии, где предсказанные данные будут равны реальным. данные. Построив этот корреляционный график, мы можем увидеть, насколько рассредоточен прогноз модели и не занижена или переоценена концентрация прогнозов.
Анализируя график корреляции, мы видим, что дисперсия не так высока для исходной модели со средним разбросом 7,8%, как было показано ранее. Анализируя концентрацию данных, мы видим, что модель варьируется между прогнозами, большими или меньшими, чем реальный, но в большинстве случаев модель немного переоценивает данные о потреблении, предсказывая более высокое потребление, чем реальное.
4.3 Испытания - данные 2018 г.
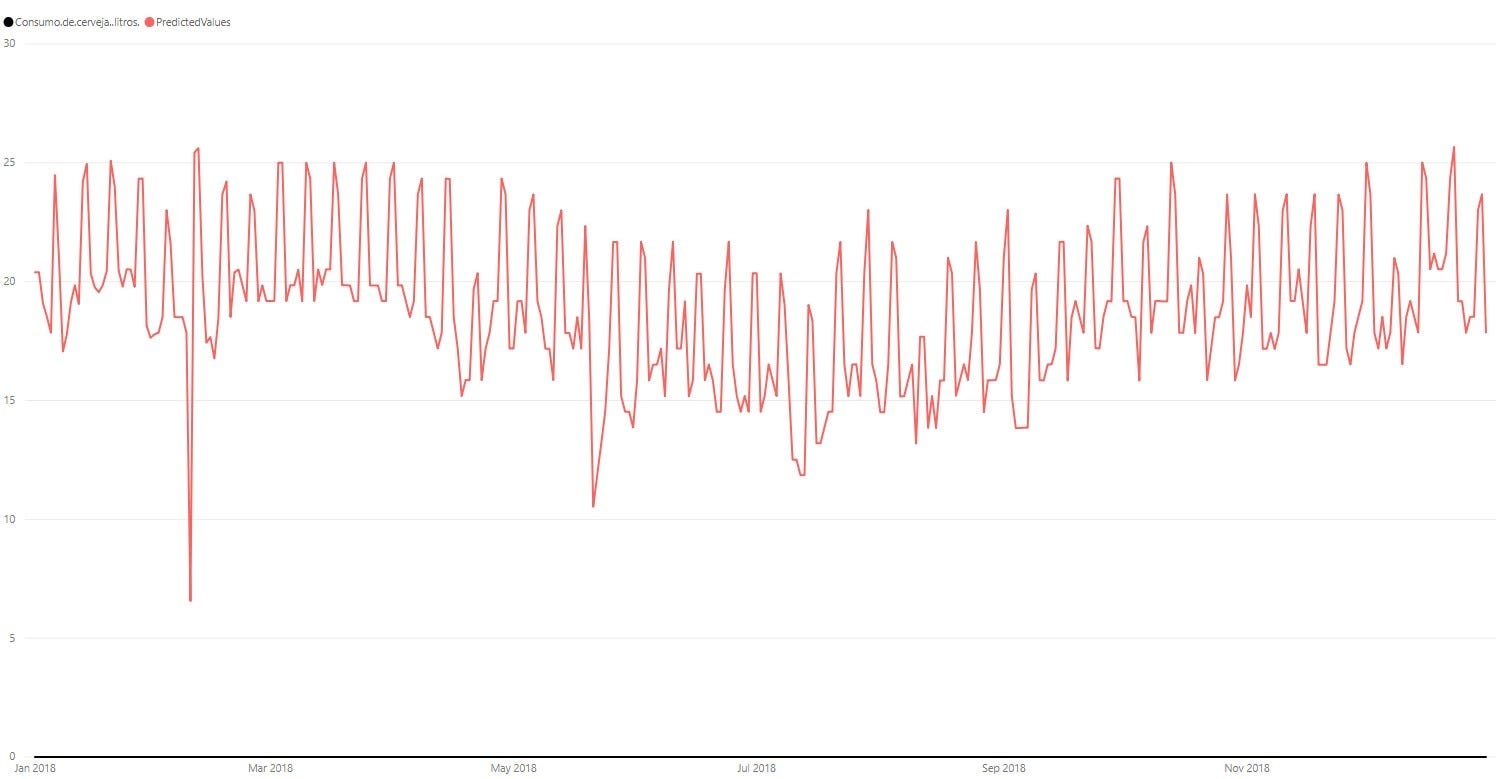
После обучения модели с данными 2015 года я попытался получить данные для вывода и получил набор данных 2018 года с данными о температуре и осадках для города Сан-Паулу.
Ниже отмечается, что значения, представленные выводом в данных за 2018 год, демонстрируют ту же закономерность, что и реальные данные, снижая потребление в середине года с понижением температуры и показывая пики в выходные дни.
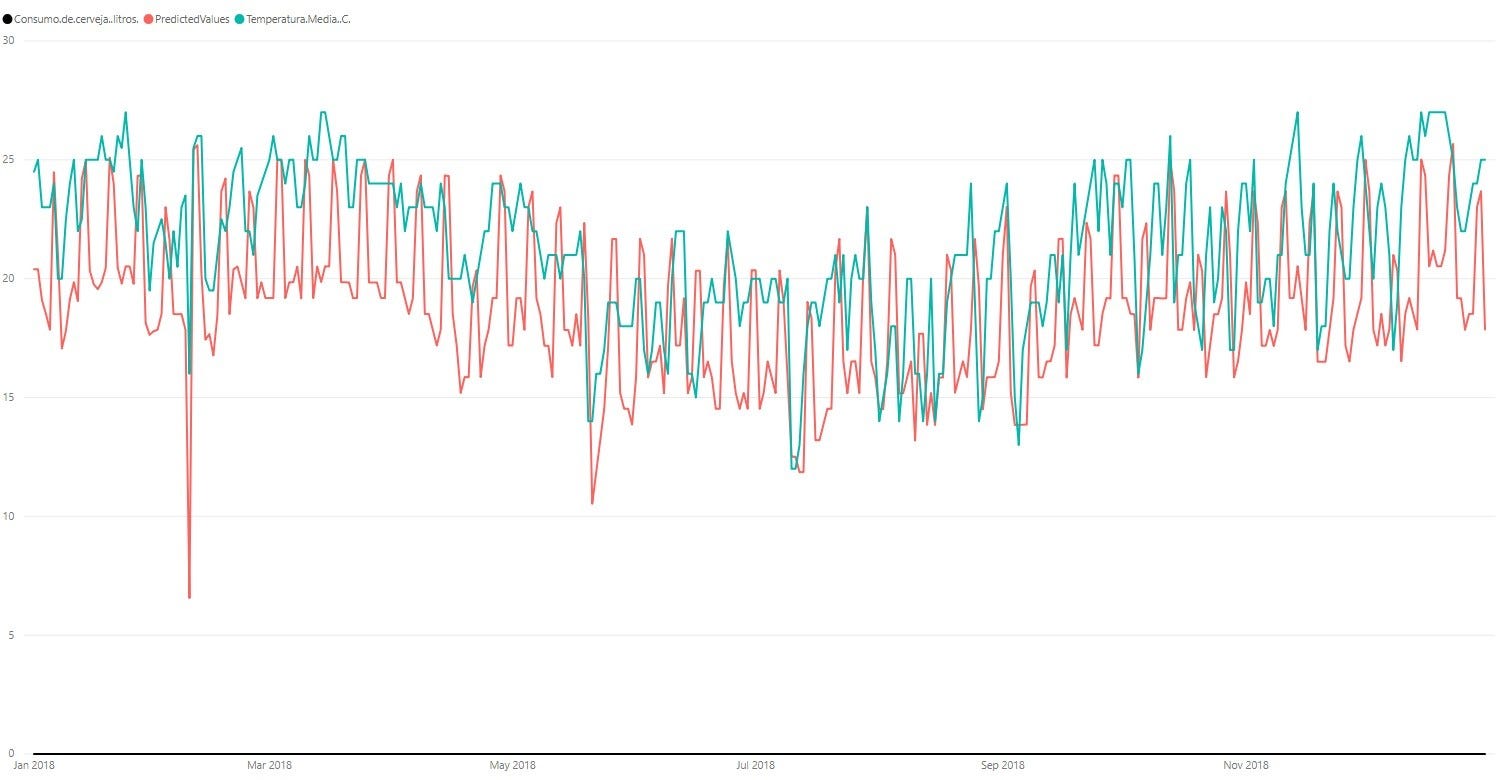
4.3.1 Корреляция с температурой
Затем значения, нанесенные синим цветом вместе с температурой, подтверждают корреляцию между потреблением и температурой и демонстрируют ее динамику в течение года также в данных вывода.
4.3.2 Сезонность выходных
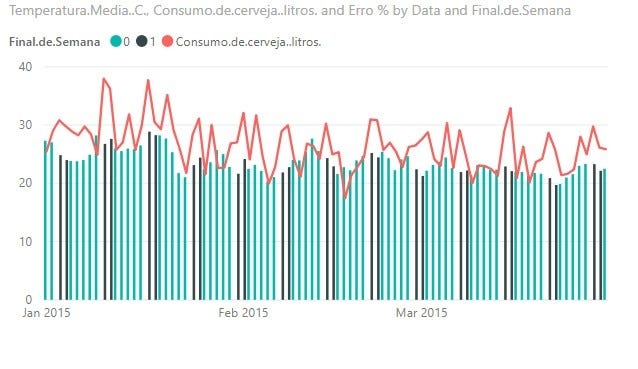
Одним из способов объяснения сезонных циклов является увеличение потребления пива в выходные дни, мы можем видеть ниже график потребления по средней температуре, где черные полосы представляют дни выходных, субботу и воскресенье.
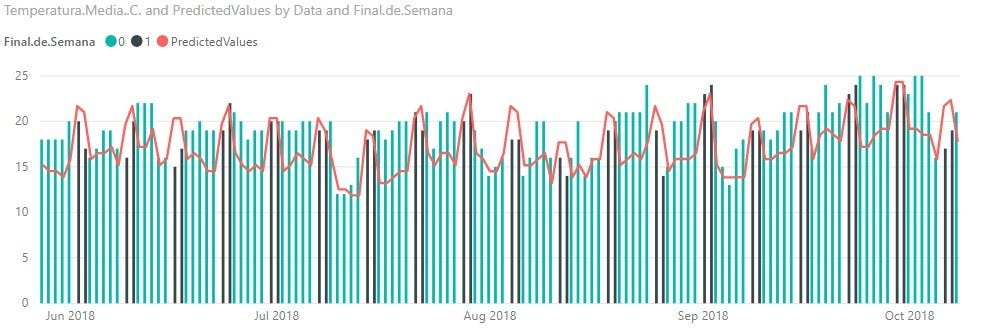
Эта сезонность также проявляется в реальных данных: когда мы строим график реального потребления за 2015 год, модель высокого потребления повторяется по выходным, что показывает, что модель, хотя и простая, была хорошо адаптирована к динамике данных.
5. Заключение
Power BI как графический инструмент обеспечивает большую гибкость и скорость разработки аналитической визуализации на основе выходных данных модели машинного обучения, помимо возможности одновременно представить исследовательский вид самой базы данных. Включение возможностей моделей машинного обучения в инструмент бизнес-аналитики, несомненно, является большим достижением для разработчиков, работающих в аналитических секторах, и PowerBI предоставляет эту функциональность простым и функциональным способом.
Наконец, любые вопросы или предложения по статье или темам машинного обучения, PowerBI, R, Python и других, не стесняйтесь обращаться ко мне в LinkedIn: https://www.linkedin.com/in/octavio-b-santiago /