Чтобы добиться успеха с глубоким обучением в масштабе, часто необходимо преобразовать необработанные обучающие данные в формат, который больше подходит для обучения моделей глубокого обучения. Один из наиболее распространенных паттернов, с которыми мы сталкивались, — это пользователи, применяющие пакетные ETL-системы, такие как Apache Spark, для предварительной обработки своих данных перед их перемещением в детерминированную для ускоренного обучения. В этой записи блога мы подробно расскажем, как обеспечить плавный переход между Spark и Defined для создания сквозных масштабируемых конвейеров для глубокого обучения. В частности, мы покажем, как вы можете использовать:
- Распределенная предварительная обработка данных с помощью Spark
- Управление версиями данных с помощью Delta Lake
- Простой интерфейс с решимостью читать и отслеживать версионный набор данных из Delta Lake.
- Распределенное обучение с детерминированным
- Пакетный вывод с помощью Spark
Посмотрите код для этого примера здесь.
Ценность управления версиями данных
Прежде чем мы начнем с примера кода, стоит рассмотреть, почему версионные наборы данных так полезны. По мере роста групп глубокого обучения они часто сталкиваются с постоянным потоком новых данных, которые маркируются, перемаркируются и перерабатываются в новые обучающие данные. Исследователи данных часто сталкиваются с тем, что их данные, модель и гиперпараметры меняются одновременно. Может быть трудно отнести изменения в производительности модели к какой-либо одной части этой системы. Если у вас нет четкого понимания того, какие именно данные использовались для обучения модели, понимание производительности вашей модели безнадежно. Вы будете летать вслепую, пытаясь внести улучшения (или, что еще хуже, рассказывая своему аудитору, что ушло на обучение модели!).
Такие системы, как Delta Lake, Pachyderm и DVC, существуют для отслеживания данных, которые меняются с течением времени. Поскольку Delta Lake тесно интегрирована с экосистемой Spark, мы будем использовать ее в этом примере для отслеживания версий наших данных.
Предварительная обработка данных с помощью Spark
Нашей целью предварительной обработки будет обработка большого набора данных изображений (в данном случае изображений и меток, хранящихся в корзине S3) в версионный набор данных с помощью Delta Lake. «В этом простом примере мы берем необработанные изображения JPEG из корзины S3 и упаковываем их в эффективно хранящиеся версионированные записи паркета. В более сложных рабочих процессах инженеры данных часто выполняют такие действия, как изменение размера изображений, кодирование функций или даже используют глубокое обучение для расчета вложений для последующих задач. Spark упрощает масштабирование этих операций для быстрой обработки массивных наборов данных.

Добавление управления версиями данных оказывается простым — Delta Lake просто отражает формат записи Parquet в Spark, а это означает, что все, что вам нужно сделать, это сохранить свою таблицу так, как вы привыкли, и вы получите дополнительные функции, такие как управление версиями данных и ACID-транзакции практически без дополнительных усилий. Это позволит нам легко использовать версионные наборы данных с детерминированным.
Простая интеграция с детерминированным
Хотя в Spark 3.0 добавлена первоклассная поддержка графических процессоров, чаще всего рабочие нагрузки, которые вы будете выполнять в Spark (например, ETL на кластере ЦП из 1000 узлов), по своей сути отличаются от требований глубокого обучения. Если вы серьезно относитесь к глубокому обучению, вам понадобится специализированная учебная платформа со всеми инструментами, необходимыми для быстрого повторения моделей глубокого обучения.
Две сильные стороны Defined прекрасно дополняют крупномасштабную обработку данных и управление версиями, предоставляемые Spark и Delta Lake: быстрое распределенное обучение и автоматическое отслеживание экспериментов. Мы можем построить соединитель между детерминированным и Delta Lake, который позволит нам:
- Изменить версию набора данных одной строкой в файле конфигурации
- Отслеживайте, какая версия данных использовалась для обучения каждой модели
По своей сути этот коннектор действительно прост — мы читаем метаданные из Delta Lake, скачиваем файлы Parquet, связанные с конкретной версией, и читаем их с помощью PyArrow. В этом примере мы затем загружаем эти файлы в набор данных PyTorch, который мы можем легко использовать с детерминированным для обучения модели.
В приведенном примере выбор набора данных и версии заканчивается так же просто, как изменение строки в файле конфигурации:
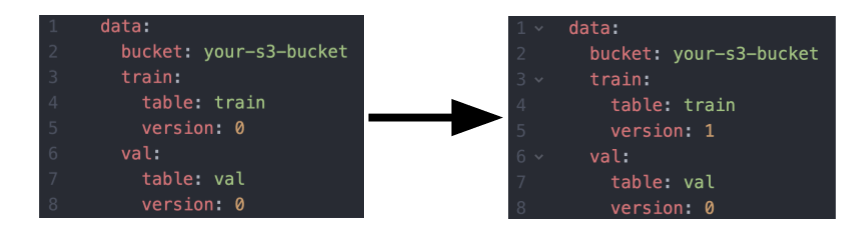
Быстро обучите модель с определенным
Spark позволяет быстро обрабатывать огромные наборы данных, используя эффективные методы распределенных вычислений, но в основном он предназначен для ускорения рабочих нагрузок ЦП. Решительный берет верх над Spark, позволяя вам обучать модели глубокого обучения с десятками и сотнями графических процессоров, чтобы значительно ускорить обучение. Это позволяет масштабировать конвейер обучения вместе с конвейером данных, чтобы постоянно обучать модели на новых версиях данных.
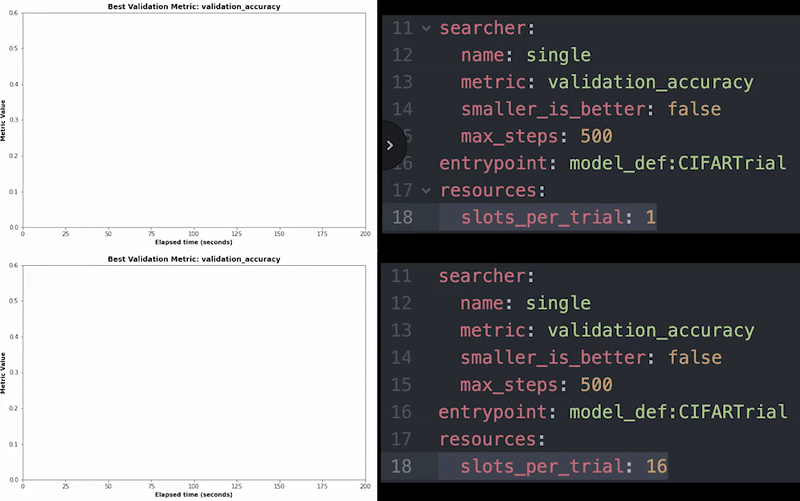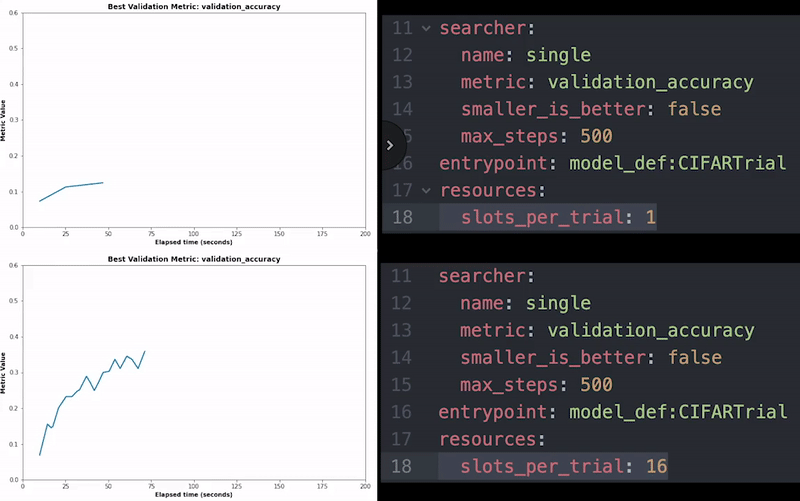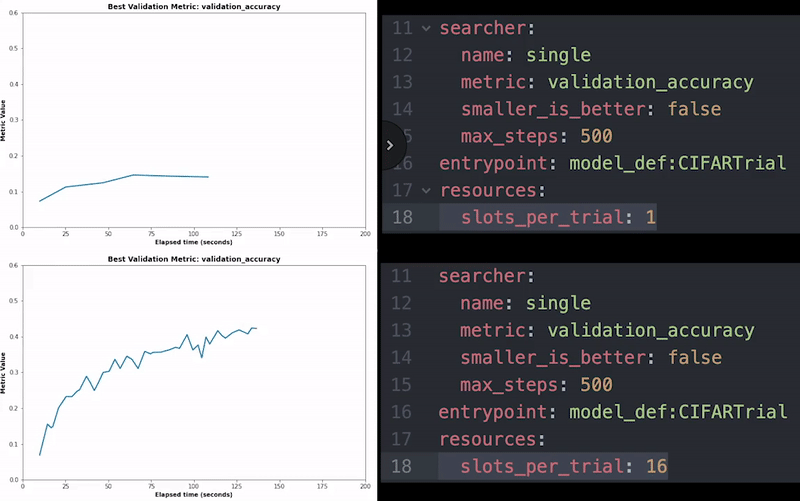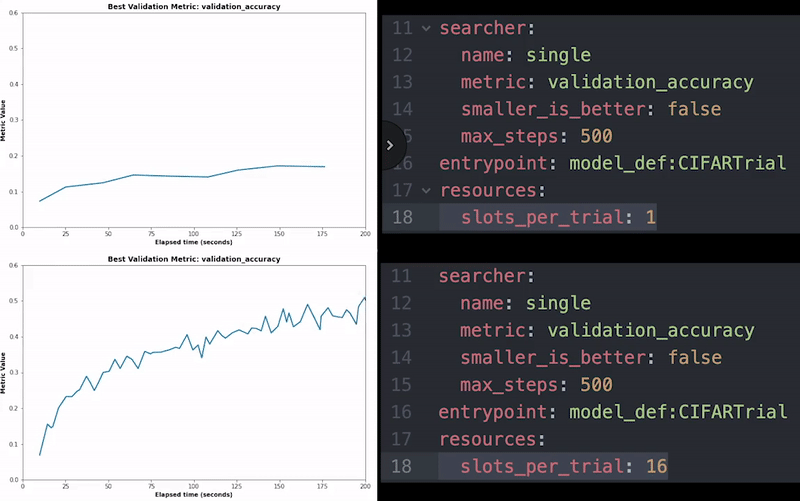
С детерминированным использовать распределенное обучение очень просто. Все, что вам нужно сделать, это настроить еще одну строку в файле конфигурации, чтобы указать, сколько графических процессоров вы хотите использовать, и вы сможете ускорить свое обучение с помощью лучших доступных распределенных алгоритмов обучения.
Вывод с помощью искры и решимости
Когда вы обучаете модель с помощью Defined, все артефакты и метрики, связанные с этим обучающим запуском, отслеживаются и доступны программно. Это позволяет легко получить обученную модель из детерминированного для логического вывода. В коде это выглядит так:
from determined.experimental import Determined experiment = Determined().get_experiment(experiment_id) checkpoint = experiment.top_checkpoint() model = checkpoint.load(map_location='cpu')
Чтобы сделать вывод о Spark, все, что нам нужно сделать, — это передать эту модель каждому из рабочих процессов Spark и применить ее к нашим тестовым данным. В справочном примере вывода мы используем API экспорта Defined Checkpoint для загрузки нашей модели в Spark, а затем применяем ее как UDF Pandas к новым данным. Spark позволяет беспрепятственно масштабировать вывод на максимальное количество доступных ядер.
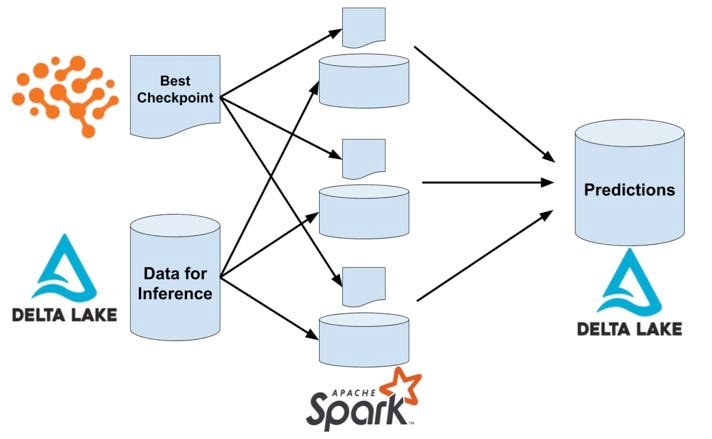
Вывод
Если вы являетесь пользователем Spark и хотите ускорить свои рабочие процессы глубокого обучения, вы можете начать работу с Defined здесь или присоединиться к нашему сообществу Slack, если у вас есть какие-либо вопросы!
Написано Дэвидом Херши (David Hershey), инженером по решениям в компании Defined AI. Дэвид провел последние два года, работая над созданием корпоративных платформ машинного обучения, ранее возглавляя проект платформы машинного обучения Ford. Не стесняйтесь обращаться к нему напрямую.
Первоначально опубликовано на https://determined.ai 11 августа 2020 г.