Лучшие практики парсинга данных с использованием селена в Python

Селен для парсинга веб-страниц
Selenium - это библиотека автоматизации браузера. Чаще всего используется для тестирования веб-приложений, Selenium можно использовать для любых задач, требующих автоматизации взаимодействия с браузером. Это может включать веб-скрейпинг.
Следующее руководство будет руководством пользователя по передовому опыту веб-парсинга с использованием селена. Я перечислил свои 5 основных советов, которые помогут пользователям максимально эффективно очищать любые запрашиваемые данные, используя Python с минимальным объемом кода.
Цель:
Чтобы извлечь глобальные заголовки о коронавирусе из новостей BBC.
Предпосылки
Чтобы следовать этому руководству, вам необходимо:
- Загрузите selenium webdriver. Драйвер Chrome может использоваться для взаимодействия с Chrome и доступен здесь.
pip install selenium
5 лучших практических советов по использованию Selenium
Совет 1. Поместите исполняемый файл webdriver в PATH
Чтобы начать нашу задачу по парсингу, мы должны сначала перейти на следующую страницу https://www.bbc.co.uk/news. Этот шаг может быть выполнен всего за три строчки кода. Сначала мы импортируем webdriver из selenium, создаем экземпляр chrome webdriver и, наконец, вызываем метод get для объекта webdriver с именем driver.
Чтобы сделать этот код коротким и читабельным, исполняемый файл chromedriver может быть помещен в выбранную пользователем папку. Затем это место назначения можно добавить в PATH под вашими переменными окружения. Затем webdriver готов к работе, просто используя webdriver.Chrome () без аргументов, переданных в Chrome в круглых скобках.
Совет 2. Найдите любой веб-элемент с помощью консоли.
Когда мы перешли на веб-страницу, мы хотели бы найти поле поиска, щелкнуть по нему и начать вводить «глобальные обновления коронавируса».
Чтобы найти этот веб-элемент, мы можем просто щелкнуть правой кнопкой мыши хром и выбрать «Проверить». В верхнем левом углу страницы, которая открывается при просмотре, мы можем использовать курсор для наведения курсора и выбора интересующих веб-элементов. Как показано, в поле поиска есть тег ввода со значением id «orb-search-q».
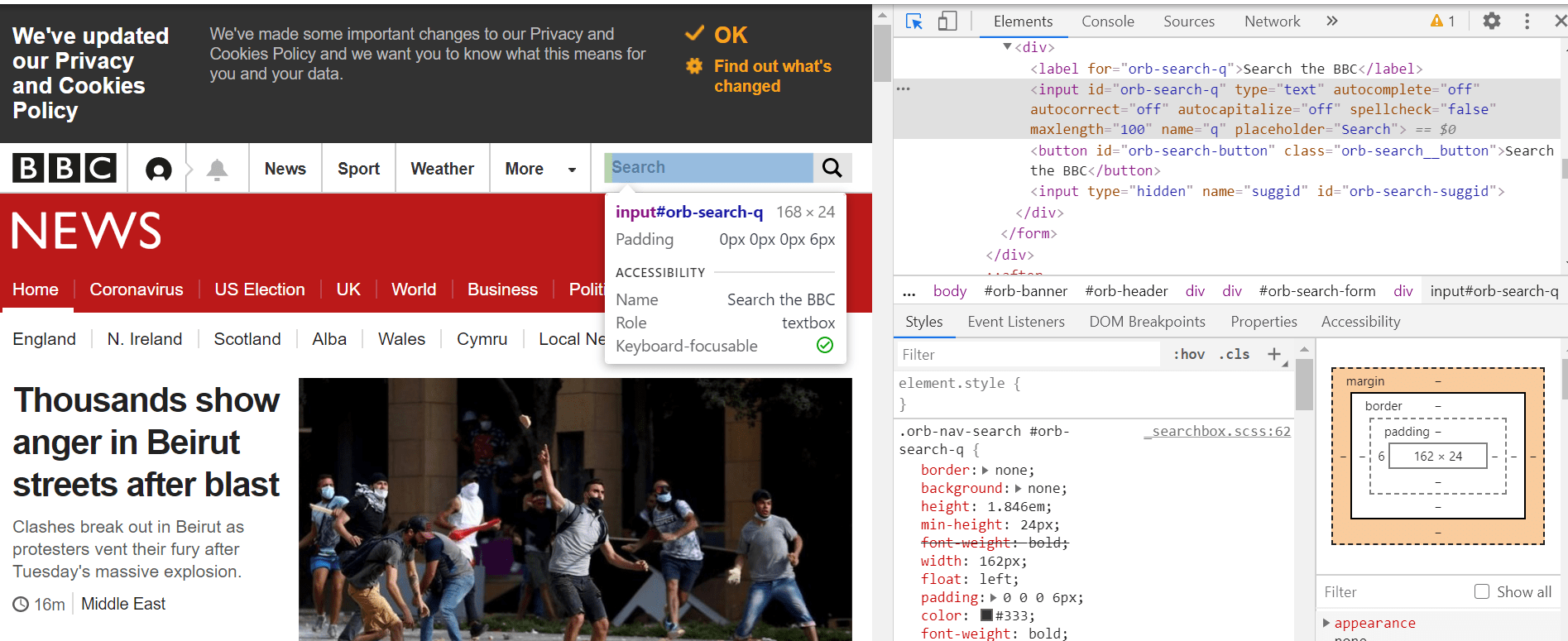
Как убедиться, что это единственный элемент поиска, который нас интересует?
Мы можем просто выбрать окно вкладки консоли, а затем ввести два знака доллара, за которыми следуют круглые скобки и цитаты. Внутри кавычек мы пишем ввод тега, за которым следуют квадратные скобки. В этих квадратных скобках мы можем добавить идентификатор и его значение.
Format to find CSS selectors
$$('tag[attribute="attribute value"]')
Как показано, возвращается массив только из одного элемента. Мы можем быть уверены, что теперь у нас есть нужное окно поиска, по которому можно щелкнуть и начать вводить поисковые запросы.
Содержимое кавычек в консоли является допустимым селектором CSS, и мы можем использовать его в нашем скрипте для поиска веб-элемента.
Это приводит к следующему совету.

Совет 3. Мощный парсинг данных. Однострочники: ActionChains и Keys.
Теперь мы можем вызвать метод find_element_by_css_selector в драйвере объекта webdriver.
Мы хотим, чтобы наш веб-драйвер переместился на этот веб-элемент, щелкните по нему, введите поисковый запрос «Глобальные обновления коронавируса» и нажмите клавишу ВВОД.
Это легко сделать с помощью классов ActionChains и Keys из selenium. Мы просто передаем драйвер в ActionChains и цепочку методов, используя методы move_to_element, click, send_keys для ввода ввода и key_downwith Keys.ENTER для имитации ввода. Чтобы запустить эту команду, добавьте метод perform в конец ActionChain.
Запуск ActionChain приведет нас сюда:

Совет 4. Сбор данных
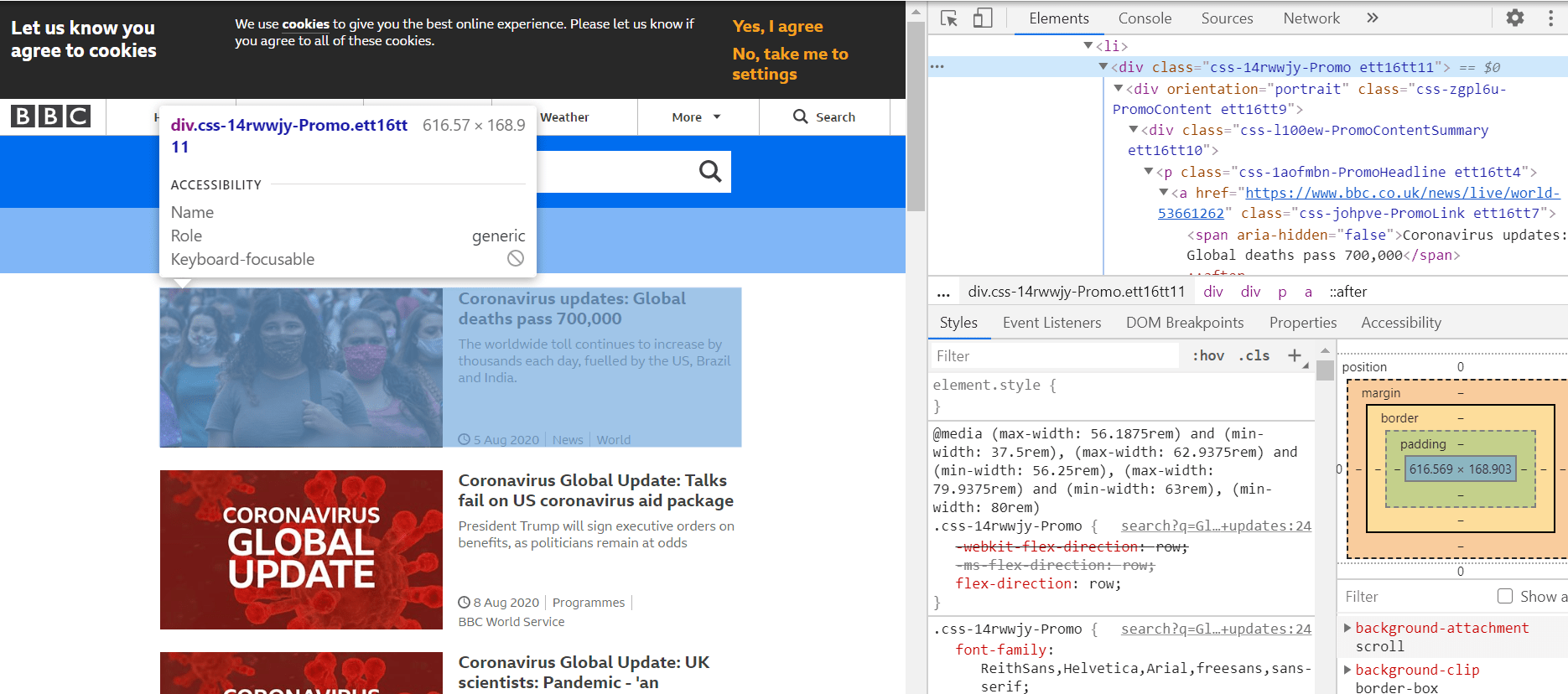
Показанный веб-элемент возвращает изображение, заголовок, подзаголовок и некоторую дополнительную информацию, например дату публикации.
Как мы можем уловить только заголовок каждой истории?
Если мы введем в консоль веб-элемент, показанный ниже, он вернет список из 10 веб-элементов. Мы хотим извлечь только заголовок из каждой из этих историй.
Для этого мы можем просто перебрать 10 историй. Для этого мы вызываем find_elements_by_css_selector с переданным веб-элементом. Этот метод возвращает объект в виде списка, который мы можем перебирать.
Мы можем присвоить это имя переменной top_titles и перебирать их с помощью цикла for. В цикле for мы можем найти элемент, связанный с каждым заголовком, используя совет № 2, и извлечь текст, вызвав .text на веб-элементе.
Помимо печати в консоли терминала, мы также можем писать в файл .txt, чтобы у нас была постоянная копия заголовков всякий раз, когда мы запускаем скрипт.
Совет 5: веб-драйвер без головы
Когда мы запускаем скрипт для извлечения заголовков, появляется всплывающее окно браузера, как показано на видео ниже.
Хотя это может быть интересно наблюдать, по большей части это может быть нежелательно.
Чтобы удалить браузер, импортируйте класс Options из модуля selenium, создайте экземпляр этого класса и вызовите add_argumentmethod в этом экземпляре с переданным строковым аргументом ‘- headless’. Наконец, в webdriver в параметре options добавьте переменную, которая указывает на безголовый браузер.
Бонусный совет: добавьте ожидания для поиска элементов в случае медленного соединения
Webdriver wait, By и expected_conditions
Чтобы убедиться, что сканирование прошло успешно, мы можем ввести ожидание в наш скрипт. Эта функция может быть особенно полезна в случаях, когда веб-страницы загружаются медленно. Для этого мы импортируем три показанных класса.
Что хорошо во введении ожиданий, так это то, что когда они построены, их можно почти записать как предложение. Кроме того, они могут искать веб-элемент столько, сколько мы захотим. Если веб-элемент обнаружен раньше, сценарий просто также выполняется раньше.
Здесь мы передаем класс WebDriverWait, объект нашего драйвера, и говорим ему подождать не более 10 секунд, пока элемент не будет найден. В методе until мы передаем классExpectedConditons с псевдонимом EC и вызываем на нем метод присутствия элемента. Затем мы передаем этому методу кортеж локатора, подробно описывающий, какой элемент мы ищем (By.CSS_SELECTOR), и веб-элемент.
Ожидание сделает ваши скрипты более надежными и менее восприимчивыми к исключениям тайм-аута.
Скрипт для этих примеров полностью показан здесь.
Превращение скрипта автоматизации в класс
Класс заголовков о коронавирусе
Когда мы уверены, что веб-автоматизация работает должным образом, мы можем преобразовать код в класс. Чтобы не усложнять задачу для потенциальных пользователей этого класса, я решил назвать класс CoronaVirusHeadlines.
В initconstructor я установил атрибут драйвера в объекте, который указывает на веб-драйвер Chrome.
Код в точности совпадает с процедурным кодом, показанным в предыдущих разделах (за исключением того, что я удалил вариант без головы). Единственное исключение - драйвер установлен как атрибут в объекте. Драйвер инициализируется в методе инициализации и используется в get_headlinesmethod для получения заголовков.
Чтобы получить заголовки, я просто создаю экземпляр этого класса с именем virus_data. Затем я вызываю метод get_headlines этого класса, чтобы получить заголовки в файле .txt.
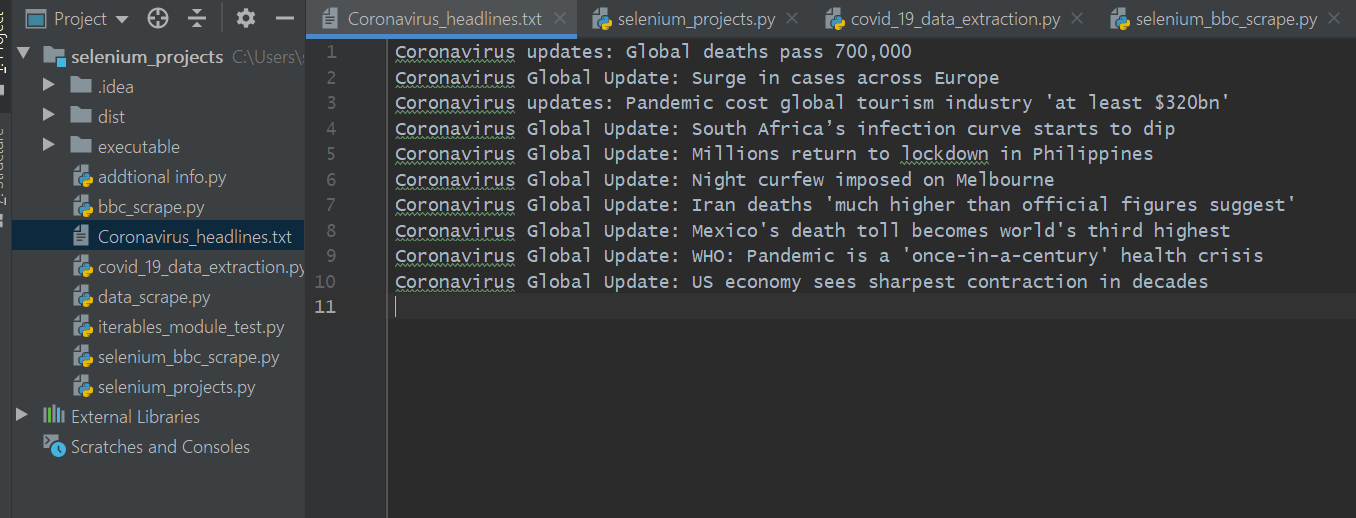
Теперь в моем локальном каталоге я могу проверить файл с именем Coronavirus_headlines.txt.
Как показано ниже, заголовки скопированы в файл .txt. Имейте в виду, что если вы запустите код самостоятельно, заголовки, конечно же, будут другими, поскольку пандемия коронавируса постоянно развивается, и новые статьи публикуются на BBC ежедневно.
Резюме и дополнения
Это одни из моих лучших советов по очистке селеном. Некоторые советы, включая цепочку действий и подсказки по ожиданию, могут быть очень удобочитаемыми и легко понятными для тех, кто тоже может читать ваш код.
Скрипт легко можно было расширить. Вы также можете перейти на вторую страницу, чтобы получить следующие 10 заголовков. Или, может быть, вы хотите, чтобы заголовки были отправлены по электронной почте или преобразованы в исполняемый файл, чтобы заголовки можно было передать вам и вашим заинтересованным коллегам / друзьям, которые не обязательно используют Python. Этого можно добиться с помощью модулей smtplib или PyInstaller соответственно.
Спасибо за прочтение.