Недавно я создал скрипт для очистки последних n соревнований пользователя, где n задается как вводимые пользователем данные. Затем я столкнулся с этим вопросом и подумал, что мне следует написать лучший сценарий, который может использоваться всеми пользователями Codeforces во всем мире.
Здесь я представляю вам VirtualCF - парсер Codeforces для конкретного конкурса, идентифицированного Id. Его можно использовать для непрерывного и беспрепятственного участия в виртуальном конкурсе, улучшении тренировочного или даже живого конкурса.
Вы когда-нибудь думали о том, чтобы попрактиковаться в конкретном раунде - скажем, Div3 и чувствовали себя ленивыми по поводу создания надлежащей структуры каталогов для конкурса, имея надлежащие файлы с названиями задач?
Вы когда-нибудь задумывались о том, чтобы получить визуальное представление принятого соотношения задач в соревновании CF, прежде чем фактически участвовать в нем или даже обычно практиковать его?
Если да, то мой скрипт Python в вашем распоряжении. В конце я предоставил ссылку на видео Youtube для того же.
Позвольте мне рассказать вам о запуске моего сценария на Codeforces Round # 588 (Div. 2), недавнем конкурсе Радевуша, который проводился 23 сентября 2019 года.
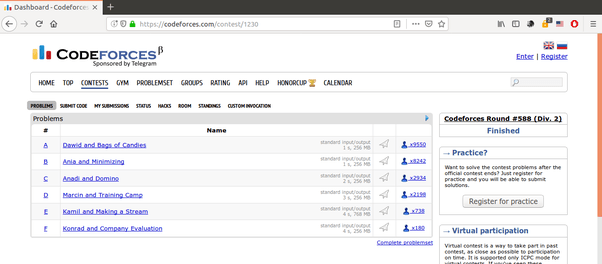
При запуске скрипта vir. py, который я сделал доступным ниже через свой github, он предложит две вещи:
- ID конкурса CF, который нужно проанализировать
- Какой предпочтительный язык программирования вы хотите
Но перед этим позвольте мне показать вам файлы, содержащиеся в моем репозитории Github.
После того как вы пометите мое репо и клонируете его, у вас будут 3 файла.
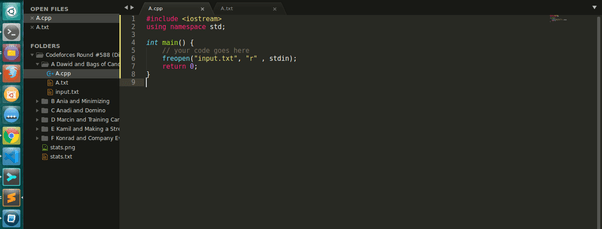
В файл template.txt необходимо вставить свой начальный код или, как они говорят, файл шаблона. Я показываю вам общий шаблон, который вы можете использовать на Codeforces.
#include <iostream> using namespace std; int main() { // your code goes here freopen("input.txt", "r" , stdin); return 0; }
Вставьте приведенный выше код в файл template.txt, и все готово.
Теперь просто запустите vir. py с вашего терминала.
В первом запросе скопируйте идентификатор конкурса из строки заголовка конкурса CF.

Выделенная часть - это ID. Затем выберите желаемый язык.
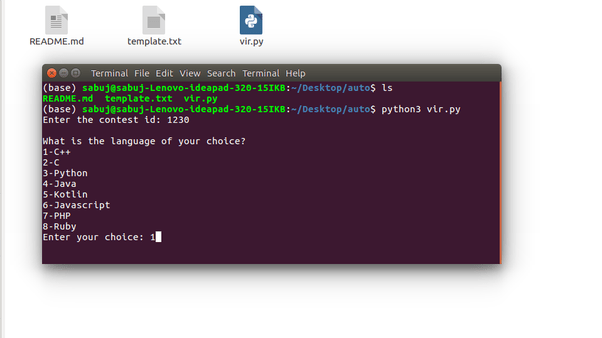
Я использую C ++, поэтому выбираю вариант 1.
Как только вы введете 1, начнется анализ и будет создана соответствующая папка с названием конкурса.
Внутри этой папки каждая проблема (A - E) будет иметь отдельные папки. Позвольте мне показать вам работающий терминал.
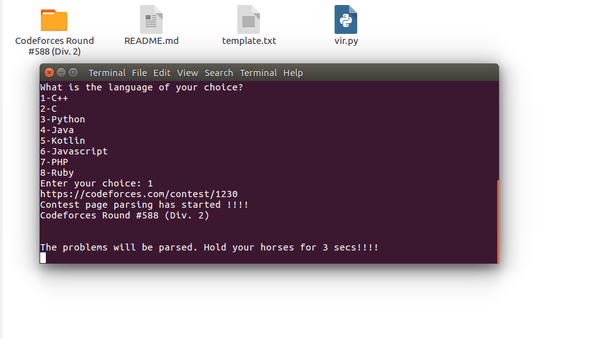
Родительская папка создана. Пойдем внутрь.
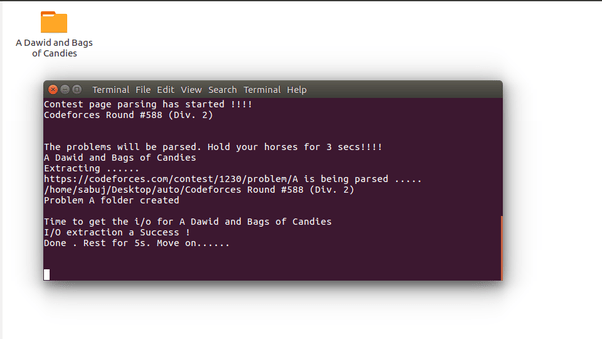
Папка проблемы A создана. Пойдем дальше.
B был создан. Давайте перейдем непосредственно к F, чтобы сэкономить место.
Все проблемы разобраны.
Теперь создаются два дополнительных файла - stats.png и stats.txt.
Он содержит информацию об уровне сложности и степени принятия каждой задачи.
На этом мы подошли к концу разбора.
Позвольте мне показать вам stats.png.
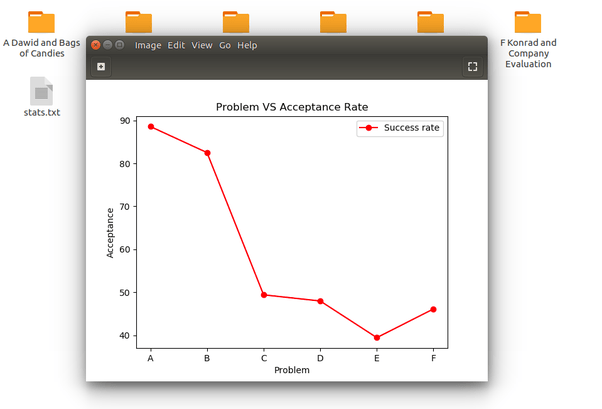
stats.txt - это, по сути, письменный формат графика, который вы можете увидеть сами. Он помогает пользователю оценить сложность каждой задачи и конкурса в целом.
Позвольте мне показать вам структуру каталогов, которая поможет вам понять полезность этого синтаксического анализатора.
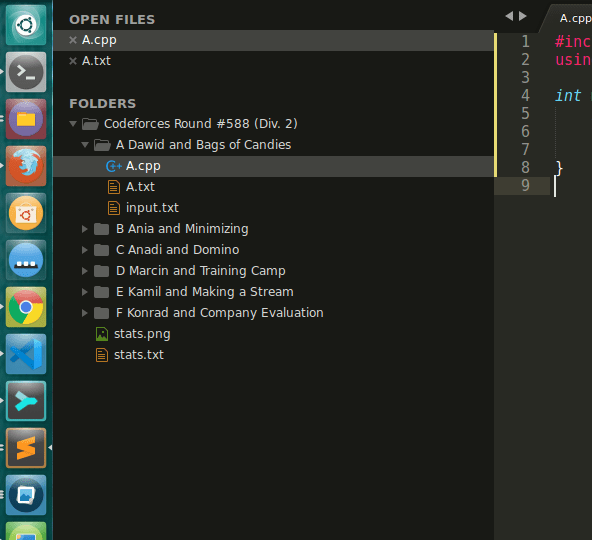
Слева вы можете увидеть, что для каждой проблемы есть отдельная папка.
В каждой такой папке есть
- файл кода A.cpp, который необходимо отправить
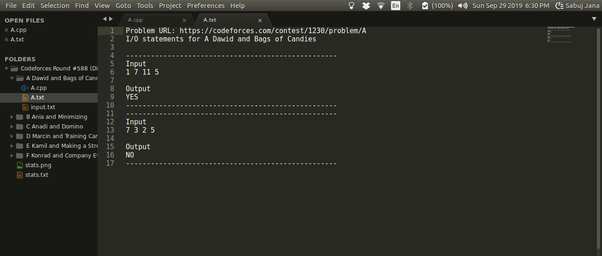
- файл .txt, содержащий все примеры ввода и вывода, представленные на странице проблемы CF. Ниже вы можете увидеть файл A.tx t, в котором есть ввод-вывод для проблемы A.
- файл input.txt, который я буду использовать лично для связи с моим файлом кода A.cpp. Это из-за оператора freopen в моем начальном коде.
Вот файл A.cpp с желаемым шаблоном.
Это все! Теперь вы можете беспрепятственно тренироваться при CF!
Вот как это можно использовать:
- Разберите конкурс, в котором вы хотите участвовать виртуально.
- Разберите конкурс, который вы просто хотите разрешить.
- Анализируйте текущий конкурс, получая идентификатор конкурса сразу после его начала. В таком сценарии будут недоступны только файлы stats.png и stats.txt.
Вот моя ссылка на репо на Github: VirtualCF
Вот демо Youtube Video:
Первоначально опубликовано на http://quora.com.