
Цель этого эксперимента — исследовать применение процесса обработки данных в ведущих в отрасли облачных аналитических инструментах.
Цель эксперимента — оценить возможность проведения точного эксперимента по машинному обучению с помощью инструмента Analytics Cloud без ввода кода. Возможность выполнения этой задачи показывает, насколько легко конечный пользователь с небольшими знаниями в области кодирования или вообще без них, смогут подобрать инструмент и применить методы машинного обучения к своим данным.
Эксперимент пытается предоставить доказательства, подтверждающие или опровергающие следующую гипотезу:
«Я считаю, что пользователь с минимальным опытом работы с наукой о данных и машинным обучением может создавать продукты простого сквозного процесса обработки данных без написания сложного кода непосредственно в инструменте облачной аналитики Oracle, OACS — в два раза быстрее. время, необходимое для написания кода на Python»
Для этого эксперимента я использовал инструмент Oracle, я не предпочитаю его другим, существует множество технологий, способных достичь аналогичных результатов.
Любой окончательный анализ будет напрямую связан с этим заявлением.
Многие из ведущих в отрасли поставщиков программного обеспечения для бизнес-аналитики адаптировали свои инструменты визуализации данных, чтобы соответствовать отраслевой тенденции использования передовых методов аналитики и обработки данных, что позволяет клиентам получить представление о своих данных, что было невозможно в прошлом.
Многие из облачных предложений BI-лидеров в настоящее время стремятся «преодолеть разрыв» между BI — традиционной бизнес-аналитикой и ИИ — машинным обучением и расширенной аналитикой. В этом эксперименте была предпринята попытка доказать концепцию OACS.
Базовый уровень
Базой для эксперимента будет сценарий кода, разработанный на Python. Наборы экспериментальных данных извлекаются из конкурса машинного обучения Kaggle, предназначенного для проверки способности ученых данных прогнозировать цены на жилье с использованием моделей машинного обучения и методов обработки данных.

Вот эксперимент на Python — как ссылка на оригинальное ядро.
Наборы обучающих и тестовых данных доступны на Kaggle.
Подсчет очков
Модели, обученные с использованием технологий Python и Cloud-Analytics, будут оцениваться Kaggle независимо друг от друга. Дополнительную информацию о конкурсе, включая описание данных и особенности, можно найти здесь.
Сгенерированные прогнозы для тестового набора данных будут оцениваться с использованием среднеквадратичной ошибки.
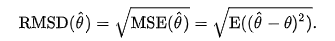
Дополнительная информация о среднеквадратичном отклонении
Технологические соображения
- Базовый уровень закодирован на Python 3.6 в Jupyter NoteBook.
- Инструмент Cloud Analytics — это Oracle Cloud Analytics Services v18.

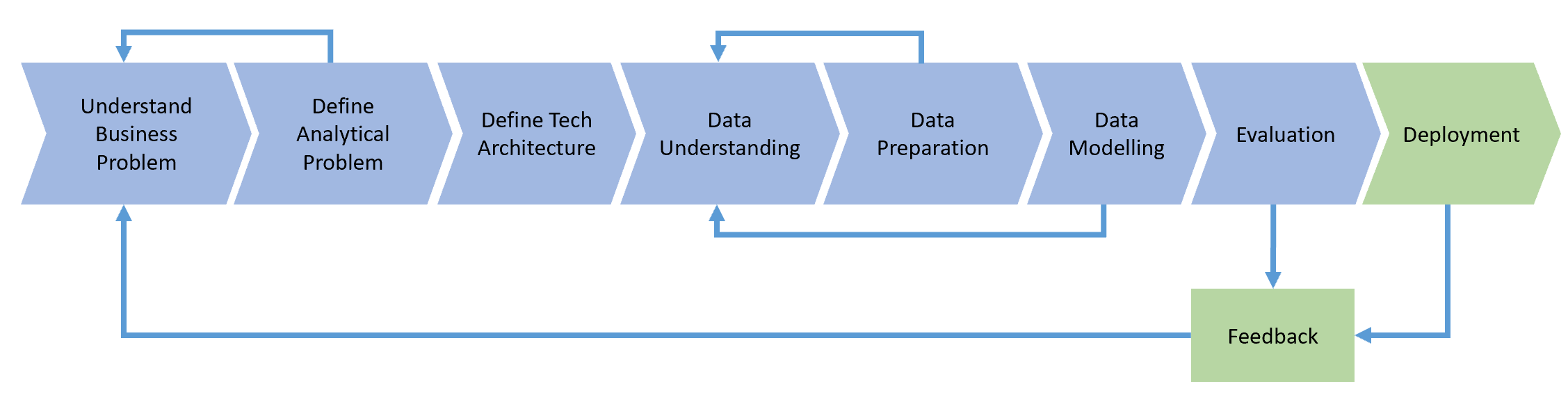
Процесс
Последующий процесс обработки данных показан ниже.
Исследование данных
Первый этап эксперимента заключался в том, чтобы провести некоторый анализ, чтобы узнать больше о представленном наборе данных.
Корреляционная матрица
Первым шагом было обеспечение понимания набора данных в целом. Начать с этого лучше всего с создания матрицы корреляции, чтобы помочь понять взаимосвязь между показателями.

Определите взаимосвязи и выбросы
Затем были определены сильно коррелированные показатели и нанесены на график в виде отдельных анализов, чтобы лучше понять их; ключевая цель - представить любые линейные отношения и выявить любые выбросы в наборе данных.
Одной из особенно полезных функций здесь была возможность быстро выбрать точку данных и изменить ее цвет на диаграмме рассеивания. Это позволило легко выделить выбросы на самой левой диаграмме рассеяния (красным цветом).
Функция аннотирования Oracle DV здесь также оказалась полезной, особенно если анализ должен был быть представлен позднее.

Опрос целевой переменной
Следующим шагом в процессе обработки данных было узнать больше о нашей целевой переменной, это было очень просто, набор данных был открыт в визуализаторе данных, наша метрика была идентифицирована и щелкнута правой кнопкой мыши. Было выбрано «Объяснить». OACS проделал здесь всю тяжелую работу. OACS, лежащие в основе алгоритмов машинного обучения, исчезли, и, несмотря на все взаимосвязи, которые могут быть заметными, он автоматически выполняет целый ряд анализов, которые могут быть запрошены.

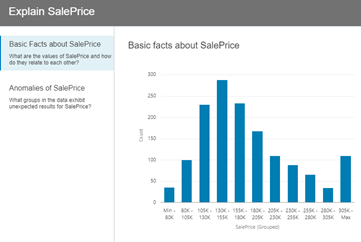
Можно было выбрать отдельные анализы и перенести их на холст DV для дальнейшего изучения.
Эта функциональность исключительна, она сократила значительное количество времени в процессе и упростила идентификацию шаблонов в наборе данных одним нажатием кнопки.
Распределение целевой переменной
После анализа, который был автоматически представлен OACS и добавлен на холст, в диаграмму были внесены незначительные изменения, чтобы изменить степень детализации по оси X, чтобы более точно визуализировать распределение данных в целевой переменной.
Примечание: не удалось найти способ закодировать идентификацию пустых значений во всем наборе данных в OACS. В python мы можем взять фрагмент кода и написать ЦИКЛ FOR, повторяющий код по всем столбцам в наборе данных. В OACS мы можем добавить собственный код Python, но это противоречит гипотезе.
В течение нескольких кликов был представлен крайний левый график (ниже). Из этой визуализации ясно, что данные искажены. Была создана пользовательская метрика, применяющая LOG() к переменной, чтобы график отображался в соответствии с правой диаграммой — чистой формой колокола.

Это требует дальнейшего изучения. В настоящее время пользователю необходимо написать индивидуальную логику для определения нулей в каждом столбце. Это займет много времени.
Подготовка данных с помощью Oracle Data Flows
Следующим этапом была подготовка данных, чтобы их можно было использовать для обучения модели. Приведенный ниже поток данных был создан для выполнения ранее определенных действий с данными.
- Удалите выбросы, которые были ранее идентифицированы
- Добавьте вычисляемый столбец, который может быть полезен (Общая площадь поверхности), который был создан путем сложения вместе других столбцов в наборе данных.
- Добавьте столбец log() в набор данных (если он не был завершен на предыдущем шаге).
- Удалите столбец подсчета, который был бесполезен для прогнозирования.

Набор данных был сохранен (здесь последний узел в потоке данных). Здесь также можно было изменить типы данных набора выходных данных. Это полезно, поскольку означает, что нам не нужно писать код для разработки этих функций.
Было что-то автоматическое, что происходит с нулями, когда мы конвертируем между текстом и числом, требует дальнейшего изучения.
Вменитель для нулей и NA
Из-за отсутствия возможности итерации по столбцам NA в этом наборе данных не были импутированы по отдельности, так как это потребовало бы отдельного описания случая для каждого столбца. Вместо этого выбранный алгоритм имел функцию ввода; Это позволило пользователю выбрать метод вменения для категориальных или непрерывных переменных.
Ограничение здесь заключалось в том, что пользователь должен был использовать один и тот же метод ввода для всех столбцов одного типа. то есть было невозможно иметь NA в непрерывной переменной A как среднее значение и NA в непрерывной переменной B как медиану.
Выбор модели и обучение
В категории моделей «числового прогнозирования» было доступно 4 различных модели.
Примечание: мы можем добавить собственные скрипты Python, содержащие пользовательские модели, эта функциональность будет оценена позже.

Для целей этого эксперимента была выбрана «Линейная регрессия для обучения модели», это предлагало метод регрессии Лассо, который соответствует коду Python, созданному в качестве основы.
Эта область в OACS требует некоторых знаний о том, как выбрать модель машинного обучения. Если OACS действительно пытается сделать науку о данных доступной для всех, должна быть ссылка на справку, содержащая информацию о том, как пользователь выбирает свою конкретную модель, или, по крайней мере, описание уровня того, в чем каждая модель или группа моделей в целом хороша/плоха. Наша обученная модель была сохранена, она живет в разделе «Машинное обучение» OACS, доступном из главного меню.
Применить модель
Когда у нас есть обученная модель, нам нужно применить ее к нашему набору тестовых данных. Набор тестовых данных загружается в OACS и сохраняется как набор данных. Затем мы создаем еще один поток данных, в котором выбираем «применить модель». Как только мы выбираем «применить модель», нам предоставляется список моделей, в котором заполняется модель, которую мы только что обучили. Мы применяем нашу новую модель и выбираем имя столбца, содержащего прогноз.

Прибраться и отправить
У нас остался набор данных, который содержит только идентификатор и отправку.

«Я считаю, что пользователь с минимальным опытом работы с наукой о данных и машинным обучением может создавать продукты простого сквозного процесса обработки данных без написания сложного кода непосредственно в инструменте облачной аналитики Oracle, OACS — в два раза быстрее. время, необходимое для написания кода на Python»
На изображении показано, что два эксперимента по линейной регрессии были очень близки по точности. Код Python просто опережает OACS по точности, однако OACS потребовалось значительно меньше времени, чтобы добраться туда.

Возвращаясь к гипотезе:
- В OACS не добавлялся пользовательский код для создания необходимых артефактов.
- Чтобы пользователь мог следовать инструкциям, не требуется серьезного обучения машинному обучению, достаточно базового понимания того, как работает общий процесс обработки данных, например, в каком порядке выполнять задачи и что делают разные модели.
- Вся работа велась непосредственно в OACS.
- Воспроизведение в OACS заняло менее половины времени.
Я считаю, что это доказано и эксперимент удался, хотя и с некоторыми оговорками, которые потребуют дальнейшего изучения. Они перечислены ниже.
Дальнейшее расследование
Сотрудничество онлайн
Это идет рука об руку с возможностью добавлять в продукт собственные скрипты. PowerBI имеет отличную платформу, на которой пользователи могут создавать визуальные элементы в R и делиться ими с онлайн-сообществом. Как только пользователь найдет визуальный элемент в Интернете, он может указать и щелкнуть его, чтобы добавить его в свой экземпляр. Что-то вроде этого — возможность совместной работы и обмена кодом в Интернете действительно сделала бы инструмент более привлекательным. Интересно, не поэтому ли Oracle недавно приобрела DataScience.com?
Добавление собственных скриптов в OACS
Эта функциональность требует практических знаний Python и XML, она определенно не для пользователя с минимальными способностями, поэтому исключена из эксперимента. Эта функциональность требует, чтобы пользователь определил функцию в python (или R) и поместил ее в общую XML-оболочку перед загрузкой.
Что было бы очень привлекательно, так это усовершенствование продукта, избавляющее от необходимости использовать XML-оболочку, чтобы пользователи могли брать чужой код с других сайтов и эффективно опробовать его в среде OACS.
Модели стекирования
Кажется, это возможно, для этого потребуется несколько потоков данных и несколько наборов данных, но это не проблема, это может значительно повысить точность и эффективность модели.
Итерация по столбцам
Как упоминалось ранее, если бы продукт мог взять фрагмент простого кода OACS (например, оператор CASE), а затем запустить его, повторяя каждый или выбранную группу столбцов в наборе данных, это сэкономило бы огромное количество времени.
Последовательности
Все потоки данных, упомянутые в эксперименте, можно объединить в последовательности и запустить один за другим, чтобы создать один конвейер в стиле «ETL». Эксперимент не затронул эту функциональность.
Первоначально опубликовано на http://drunkendatascience.com 5 мая 2019 г.