
В Disney Streaming очень серьезно относятся к опыту наших подписчиков. Наш сервис обслуживает более 100 миллионов подписчиков по всему миру. Мы хотим, чтобы у наших подписчиков были лучшие впечатления от просмотра нашего контента, и создать удобный процесс ежемесячной оплаты, чтобы упростить взаимодействие с пользователем при использовании платформы.
Платежная команда Disney + отвечает за разработку и поддержку платежной платформы, которая обеспечивает эффективные, беспроблемные, ежемесячные и ежегодные транзакции с высокой скоростью утверждения для более 100 миллионов клиентов по всему миру. Наша команда также помогает улучшить качество обслуживания подписчиков Disney Streaming за счет оптимизации обработки платежей.
В этом посте подробно рассказывается, как платежная команда разработала и реализовала структуру механизма правил для деструктуризации сложных бизнес-правил для уменьшения масштабных сбоев платежей.
Прежде чем мы погрузимся в
В статье делается попытка резюмировать проблему с точки зрения высокого уровня, но описаны некоторые решения по реализации, которые предполагают некоторое знание языка программирования Scala и чисто функциональных конструкций, предоставляемых библиотеками, такими как коты.
Проблема: спорадические сбои в оплате
Счета для подписчиков Disney + выставляются ежемесячно или ежегодно. Существует множество причин, по которым повторный платеж может не сработать, например, нехватка средств на балансном счете или истечение срока действия кредитной карты.
В случае сбоя платежа подписчик войдет в Disney + или ESPN + только для того, чтобы обнаружить, что он не может смотреть контент. Это плохой пользовательский опыт. Поэтому наша задача - сделать все возможное, чтобы этого не произошло, повторяя эти неудавшиеся платежи.
Первоначальная реализация логики повтора была одинаковой для всех подписчиков. Однако по мере того, как Disney + постепенно запускался в новых местах по всему миру, стало очевидно, что логика «один размер подходит всем» была неоптимальной, и что нам нужно было экспериментировать с различными реализациями, используя информацию, специфичную для пользователя, настроенную для каждой учетной записи.
Например, «если пользователь находится в стране X, повторите попытку в следующий понедельник».
Проблема ремонтопригодности
В связи с продолжающимися экспериментами с различными реализациями логики повторных попыток сложность поддержания каждого бизнес-правила возрастает в геометрической прогрессии. Некоторые части одной реализации могут пересекаться с другими, и инженеры вынуждены переписывать эти части, что может занять несколько дней тестирования и многочисленных сервисных выпусков, прежде чем реализация будет принята.
Чтобы решить эту проблему, мы создали микросервис, который отвечает за оптимизацию повторяющихся сбоев биллинга.
Служба включает в себя механизм интеллектуальной повторной попытки, который использует информацию о счете, например о стране проживания подписчика, для оптимизации повторяющихся сбоев.
Мы определили основные принципы сервиса:
- Оценка в реальном времени: мы хотим создать правила для оценки каждого расписания повторных попыток в реальном времени.
- Принимайте решения на основе ранее вычисленных значений. Система должна поддерживать принятие решений на основе динамически вычисляемых значений. Например, наличие правил, в которых упоминается: «Если транзакция принадлежит подписчику Disney +, система выбирает использование выполнения A. Если транзакция принадлежит подписчику ESPN +, система выбирает использование выполнения B.»
- Расширяемость. В связи с ростом экспериментов с различными бизнес-правилами в кросс-функциональной команде и соблюдением A / B-тестирования разработчики должны иметь возможность легко добавлять и удалять новые правила из системы.
- Возможность аудита: возможность отслеживать, какие расписания повторных попыток приводят к повышению скорости аутентификации пользователей, и повторно воспроизводить последовательность операций для устранения неполадок.
Пользовательская структура механизма правил
Создание масштабируемой оптимизационной платформы повторяющихся сбоев, которая позволяет быстро добавлять и изменять правила с минимальными инженерными усилиями, может оказаться сложной задачей. Полезно абстрагироваться от сложных бизнес-правил в структуре, которая позволяет инженерам быстро развиваться и меняться.
Мы создали нашу собственную внутреннюю библиотеку управления и оценки правил. Наш собственный механизм правил позволяет нам организовывать сложные бизнес-сценарии в составные правила.
Механизм правил основан на декларативной композиции, поскольку мы обнаружили, что это лучший способ точно отразить бизнес-варианты использования. Короче говоря, механизм правил позволяет разработчикам заявлять: «Что делать?» вместо «Как это сделать?» Это позволяет разработчику ясно видеть: «Как система пришла к этому решению?» и «Как принималось каждое« решение »?»
В следующих разделах мы опишем отдельные компоненты, составляющие механизм правил.
Философия нашей библиотеки Rule Engine
В этом разделе кратко изложены основные технологии и философия двигателя. Он пропускает детали реализации кода каждого компонента.
Мы принимаем парадигму функционального программирования, чтобы декларативно определять наши бизнес-действия и использовать Scala для реализации. После того, как разработчики деструктурируют предложения в семантику механизма правил, называемую компонентами, они могут реализовать логику каждого компонента с помощью библиотеки. Разработчикам необходимо будет заполнить пробелы по каждому из компонентов (RuleF, RuleBuffer и RuleNode.)
RuleBuffer служит состоянием, при котором можно переходить от одного правила к другому. Во время выполнения каждое RuleF выполняет действие и изменяет состояние RuleBuffer. RuleNode запускает средство отслеживания результатов, чтобы добавить новый журнал результатов выполнения. Затем он передает обновленный RuleBuffer и средство отслеживания результатов условным анонимным функциям маршрутизатора, которые решают, какой RuleNode должен оценить текущую транзакцию следующей.
Мы абстрагируем сложные инструкции в сжатый конвейер, используя абстракцию Monad для размещения динамических последовательных операций.
Благодаря такому подходу мы можем избежать любых неожиданных побочных эффектов при выполнении каждого из наборов правил. Кроме того, абстракция Monad помогает унифицировать и абстрагироваться от шаблонного кода, необходимого для логики программы.
RuleF (функция правила)
Правила определяют логику выполнения одного бизнес-действия для определенных входных данных. RuleF - это case class, который определяет логику выполнения одного правила для определенного типа ввода.
case class RuleF[F[_]: Monad, RB, D: Monoid]( ruleDefinition: RB => F[RB], traceDefinition: RB => D)
Это состоит из :
- Определение правила, которое может быть основной бизнес-логикой приложения или серией действий, выполняемых при выполнении определенных условий. Это функция, которая принимает
RuleBuffer(который мы объясним в следующем разделе) и возвращает обновленныйRuleBuffer. - Определение трассировки отслеживает все промежуточные результаты для целей аудита. Это функция, которая принимает обновленный
RuleBufferи возвращает обновленные результаты трассировки.
Механизм правил будет оценивать RuleF, выполнять его определение правила и обеспечивать механизм отслеживания, вызывая определение трассировки. RuleF автоматически вызовет определение трассировки и объединит текущее выполнение функции с существующей системой отслеживания.
В качестве примера того, что может быть RuleF, в контексте повторных попыток платежа, мы могли бы захотеть избежать повторных попыток в пятницу, если текущая транзакция идет из Франции (из-за того, как там работает банковское дело). RuleF будет состоять из логики, которая будет отмечать пятницу как запрещенный список. Систему отслеживания результатов можно получить в конце оценки набора правил.
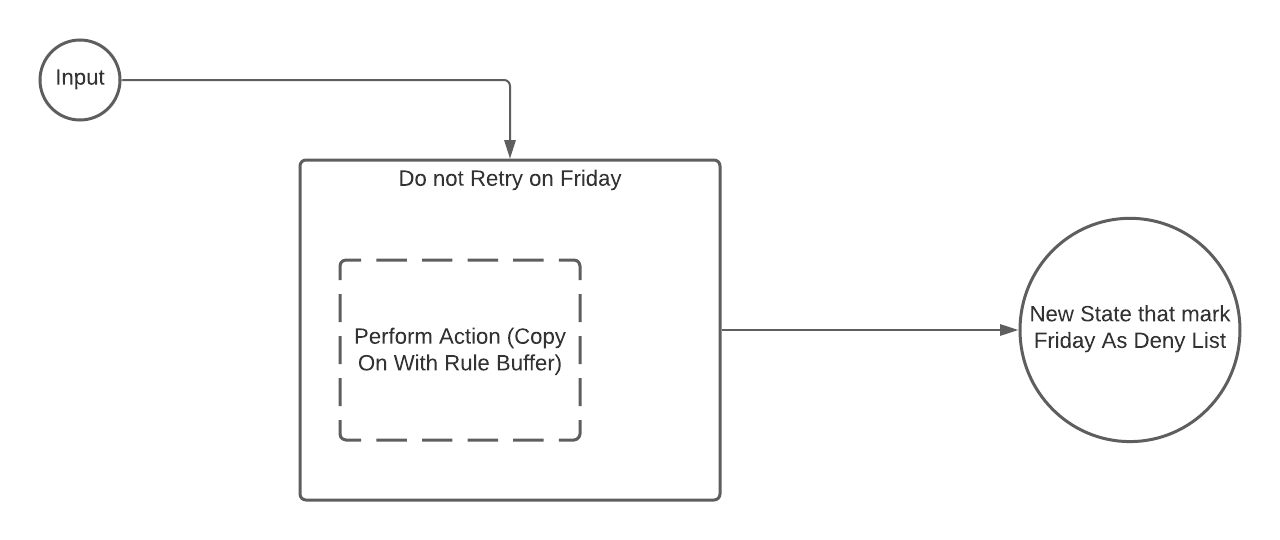
Пример кода Не повторять в пятницу RuleF:
val doNotRetryOnFridayRule =
RuleF(
ruleBuffer =>
denyList(ruleBuffer,Friday),
updatedRuleBuffer =>
List(s"updated ruleBuffer ${updatedRuleBuffer}")
)
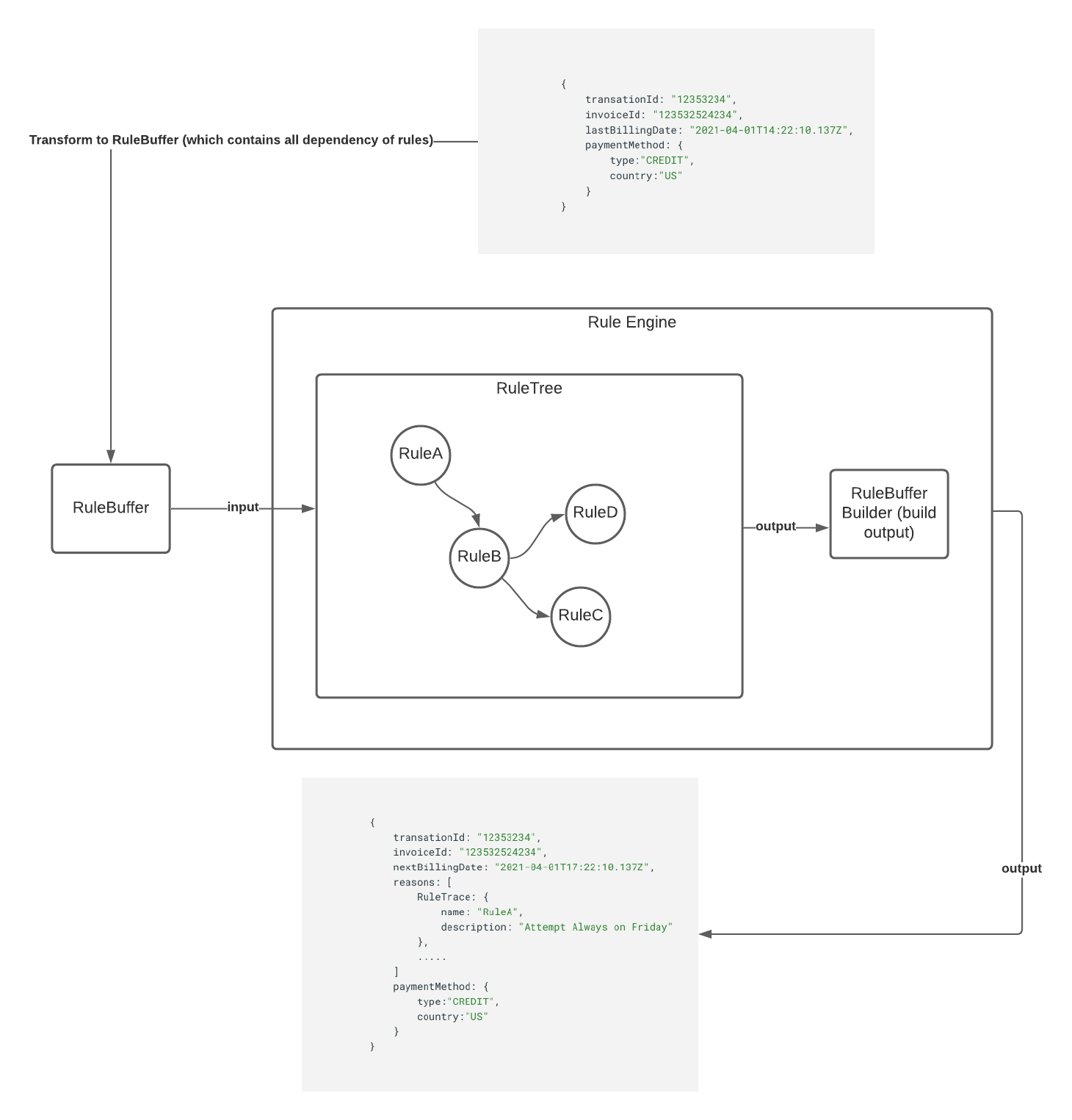
RuleBuffer
Чтобы позволить модели переходить от одного правила к другому, используется класс RuleBuffer для инкапсуляции потока данных между одним правилом и другим. Он предоставляет абстракцию для унификации модели ввода и вывода, чтобы каждый RuleF получил необходимую модель для выполнения бизнес-действий.
Объект RuleBuffer передается между узлами во время оценки правила. Узел обновляет состояние текущей оценки, выполняя неглубокую копию своего полученного ввода RuleBuffer.
В конце выполнения мы можем преобразовать существующий RuleBuffer в желаемую модель вывода.
Библиотека предоставляет BufOperation интерфейс, который разработчики должны реализовать.
trait BufOperation[RB, D, O] {
def build(buf: RB, d: D): O
}
build method выше принимает RuleBuffer типа RB и результат трассировки типаD и возвращает результат типа O.
Разработчики могут использовать любую фигуру в качестве RuleBuffer - при условии, что они реализуют интерфейс, описанный выше. На приведенной ниже диаграмме показаны общие концепции использования RuleBuffer в механизме правил.
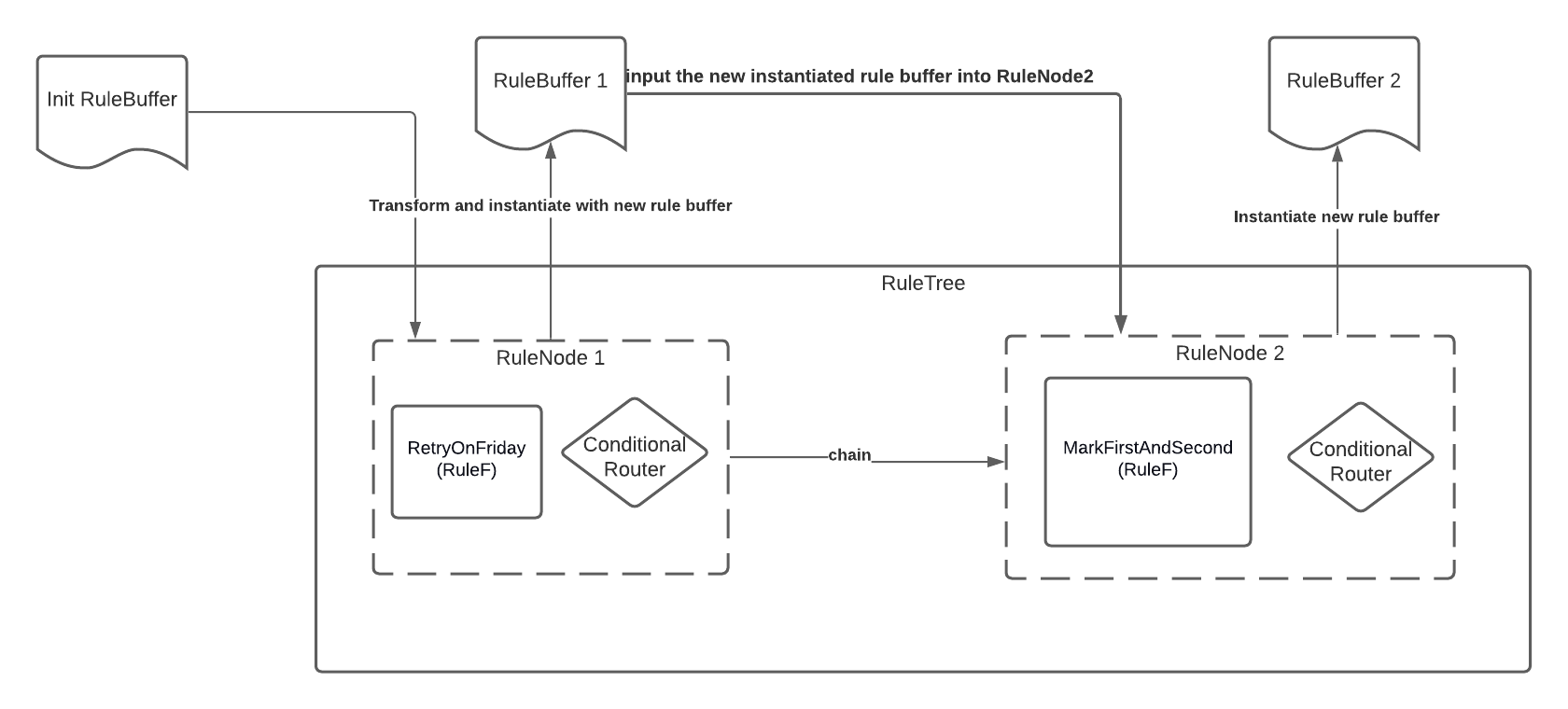
ПравилоДерево
RuleTree - это интерфейс, который инкапсулирует компонент маршрутизации, который помогает пользователям определять четкие условия настройки в модели вычислений. RuleTree содержит несколькоRuleF экземпляров.
Вместо этого разработчики могут создавать более сложные правила (в том числе условные), составляя существующие правила и используя сопоставление с образцом для динамической маршрутизации. В качестве гипотетического сценария бизнес-правила: «Не повторяйте попытку в пятницу, если текущая транзакция идет из Франции. Затем отметьте первый и второй день месяца как день повтора ». Мы отделим этот оператор бизнес-логики, реализовав его как два RuleF, инкапсулированных с двумя RuleTree.
val retryOnFridayRule = ??? // ruleF definition
val markFirstSecondRule = ??? // ruleF definition
val ruleTree = RuleTree(doNotRetryOnFridayRule) chain RuleTree(markFirstSecondRule)
// chaining with certain condition Example
RuleTree(doNotRetryOnFridayRule) chainWithCondition{rb =>
rb match {
case RuleBuffer("sunday") => someOtherRuleF
case _ => someOtherOtherRuleF
}
}
Давайте назовем первый RuleF как RetryOnFriday, который будет отмечать пятницу как список запрета, а другой RuleF как MarkFirstAndSecond, который будет отмечать первое и второе число месяца как список разрешений. Затем RuleTree вызывает условную функцию, которая переключает одно правило на другое. Вместе RuleTree принимает RuleF как соответствующее действие, выполняемое после выполнения условия.
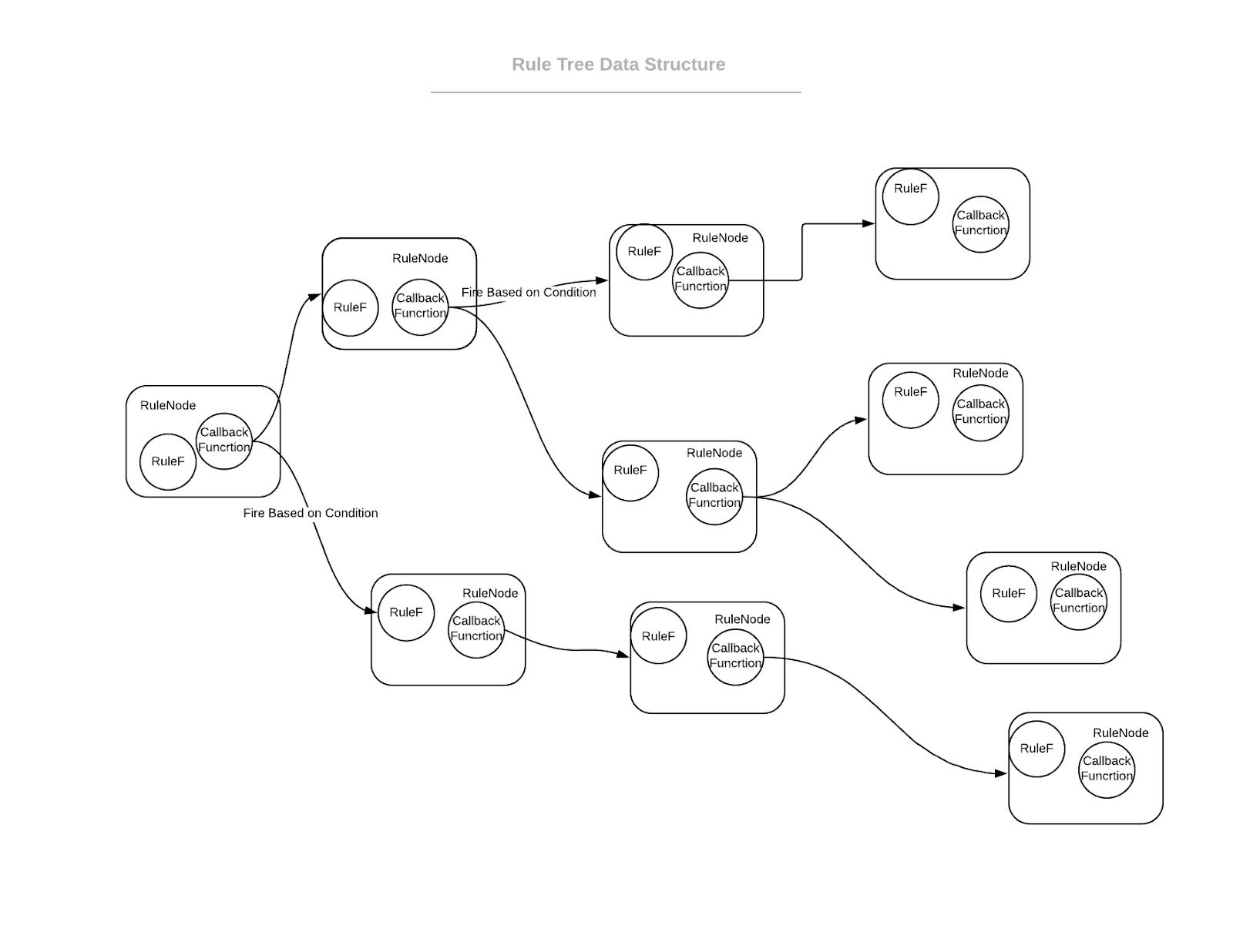
Пакет RuleEngine
RuleEngine управляет несколькими RuleTrees, используя хранилище ключей и значений. Коллекция этих хранилищ "ключ-значение" называется лесом.
val forest = Map(
"1" -> ruleTreeOne,
"2" -> ruleTreeTwo,
.... and so on
)
// getting specific ruletree
val ruleTree = RuleEngine[Map,String].get(forest)("1")
// running that ruletree
ruleTree.run(rb = exampleBuffer, traceInit = List.empty[String])
Контейнер, содержащий все RuleTree, также известный как Forest,, является обобщенным. Следовательно, RuleEngine требует указать тип Map в определении функции. Это позволяет разработчикам легко заменять хранилища в памяти постоянным хранилищем, когда они хотят выбрать компромисс между производительностью и долговечностью. Разработчики могут легко взаимодействовать с движком, предоставляя ввод и выбирая набор правил для выполнения. Вместе весь механизм правил образует древовидную структуру.
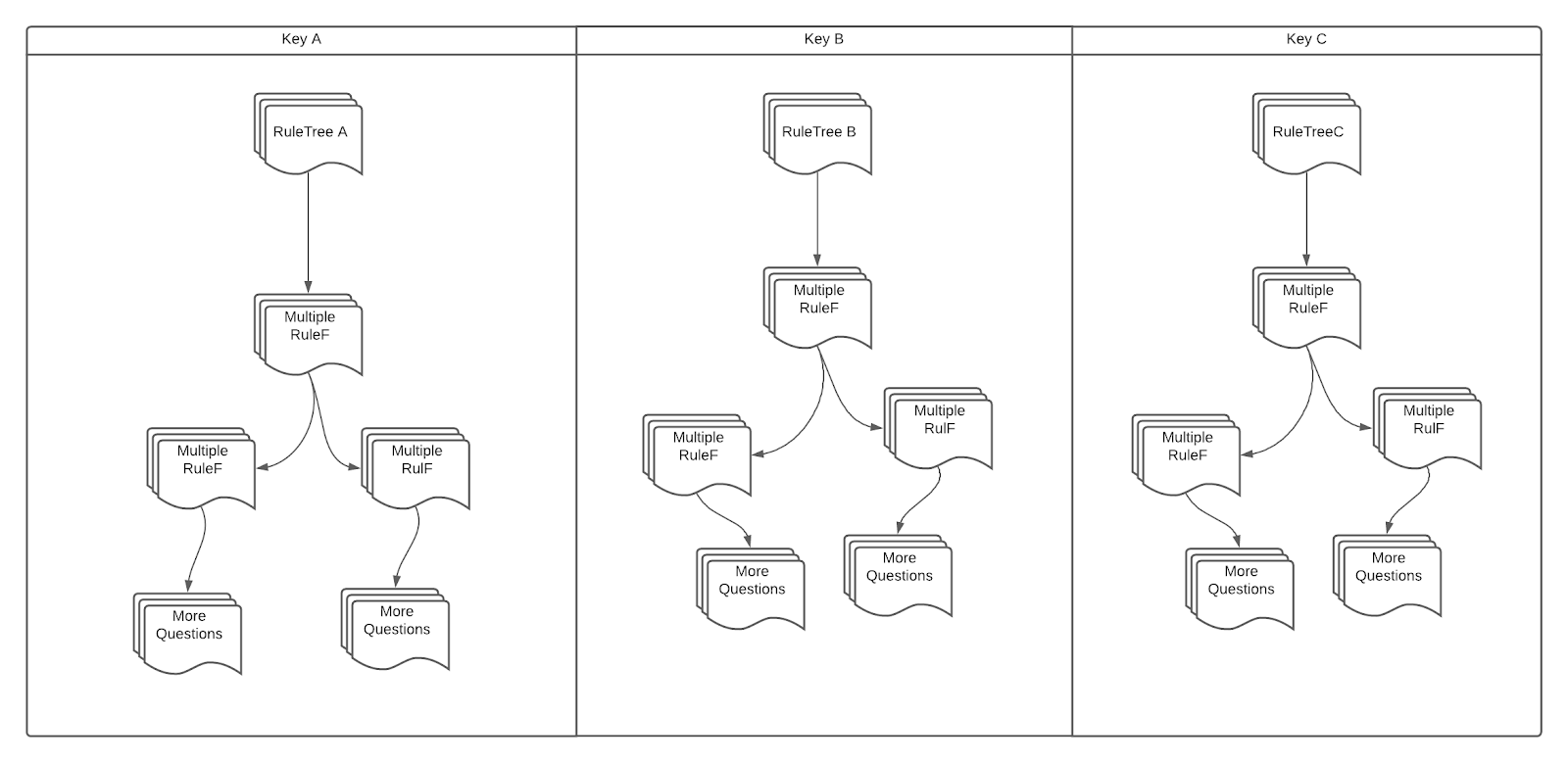
Резюме рабочего процесса разработки
Вкратце, структура поможет клиентам разбить описания бизнес-логики на серию компонентов:
- Разработчики могут построить RuleF для каждого предиката в предложении.
- Разработчики могут построить RuleTree для каждого условного оператора в предложении.
- Несколько предложений образуют лес.
- Фреймворк инкапсулирует описание леса в механизм правил.
Что следующее
Наша библиотека Rule Engine Library имела огромный успех, помогая разработчикам создавать сервис. Инженерная эффективность значительно выросла, что позволило кросс-функциональным командам проводить эксперименты по A / B-тестированию, переключать различные правила в наборе правил и оптимизировать определенные наборы правил с помощью моделей машинного обучения.
В качестве следующего шага мы хотим внести больше улучшений в нашу библиотеку механизма правил, создав универсальный пользовательский интерфейс для управления правилами. Инженеры и менеджеры по продуктам могут создавать правила на основе бизнес-прецедентов и непрерывно оценивать возможности других платежных доменов для принятия решений на основе правил.
Ознакомьтесь с другими нашими статьями, чтобы узнать больше о нашей работе по созданию масштабной потоковой инфраструктуры. Наконец, мы обычно ищем таланты. Загляните сюда, чтобы увидеть наши открытые роли в Disney Streaming!