Это третья часть моего курса машинного обучения, ориентированного на искусство. Щелкните здесь, чтобы получить доступ к обзору, в котором есть ссылки на другие семинары этой серии.
В этом классе мы рассмотрим машинное обучение в его связи со звуком и музыкой. Многие из принципов, которые вы изучили на предыдущих занятиях, применимы и здесь, но проявляются по-разному.
Мы рассмотрим несколько конкретных примеров:
Обнаружение шага
Используя ML5, мы исследуем голос пользователя через микрофон компьютера и попытаемся правильно идентифицировать музыкальные ноты. Мы рассмотрим пример, который превращает это в игру, пытаясь заставить пользователя спеть правильную ноту, и создать виртуальное пианино, клавиши которого подсвечиваются в соответствии с спетой нотой.
AI Duet
Поскольку в настоящее время ML5 немного ограничен в своих предложениях Sound + Music, мы рассмотрим другие библиотеки, проанализировав примеры AI Duet Google, которые, как и ML5, используют Tensorflow под капотом, но включают проект под названием Magenta для облегчения звука. машинное обучение на основе. В этом примере пользователь будет играть на клавиатуре, чтобы делать музыкальные ноты, а ИИ будет пытаться сопровождать музыку пользователя собственными сгенерированными нотами в дуэте ИИ, сопоставляя похожие ритмы, тона и паттерны.
Текущее состояние машинного обучения в области звука и музыки
Мы рассмотрим несколько современных примеров того, что люди делают с ML в Sound + Music сегодня.
Давайте начнем…
История
Вы можете посмотреть на что-нибудь вроде Chines Wind Chimes или Aeolian Harp как на первое устройство, позволяющее автоматически генерировать музыку.

Алгоритмическая музыка
Музыка стала альгортмической в 1700-х годах с Musikalisches Würfelspiel, игрой в кости, которая определяла рекомбинацию произведений известных композиторов сегмент за сегментом.
В 1958 году Яннис Ксенакис использовал Марковские цепи, стохастический процесс, с помощью которого система может делать прогнозы на будущее на основе своего текущего состояния, чтобы составить Аналогику. Он использовал то, что он называл таблицей когерентности - вероятностей, основанных на текущих состояниях, что будет сгенерирована следующая записка.
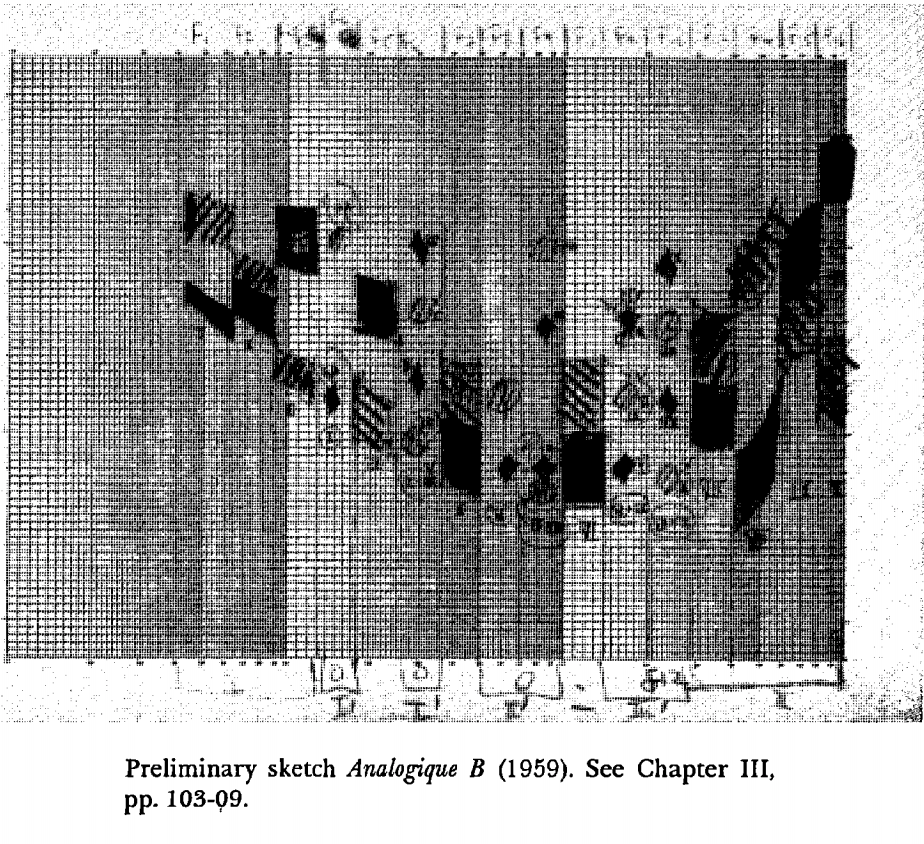
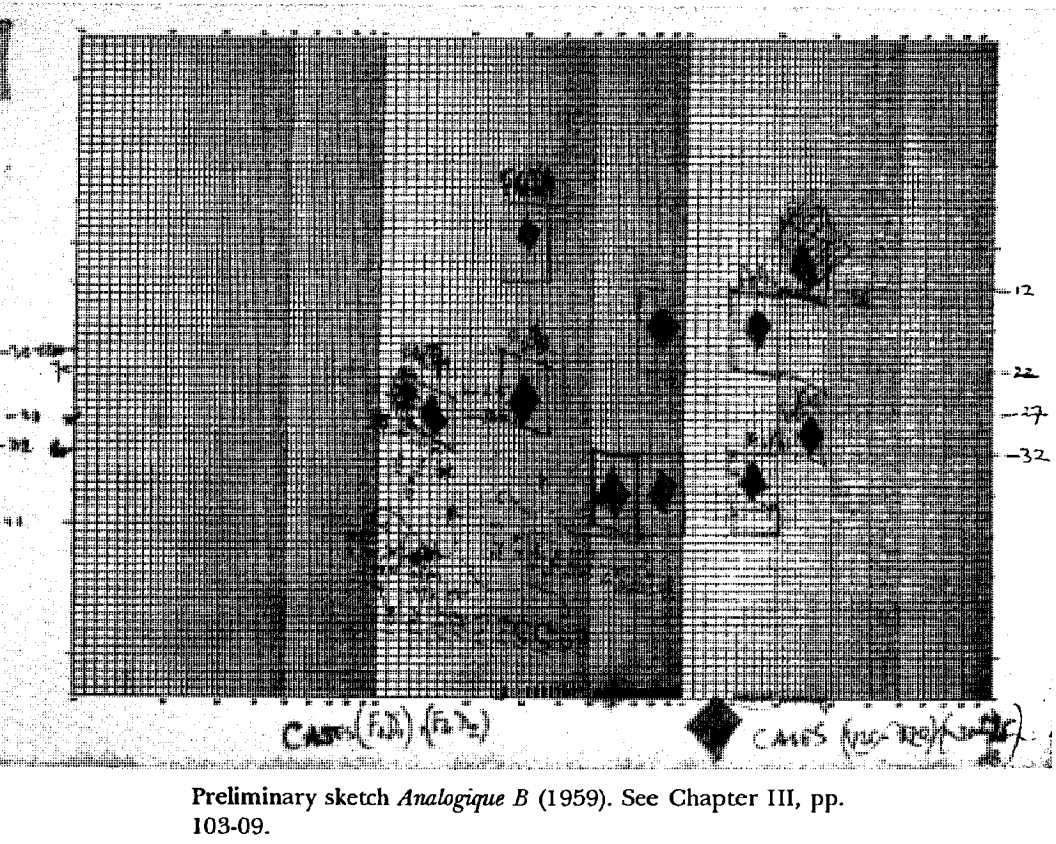
Https://www.youtube.com/watch?v=mXIJO-af_u8&
Цепи Маркова использовались Дэвидом Коупом в его «Экспериментах в области музыкального интеллекта» (или «Эмми»). Это были полуавтоматические системы с концепциями гармоник и музыкальной грамматики.
Экстраполяция музыки
Но в то время как цепи Маркова могут создавать только подпоследовательности исходной композиции, RNN были реализованы, чтобы попытаться экстраполировать за пределы этого. После попыток Баха выявить стилистические закономерности в создании новых музыкальных последовательностей:
В 2002 году Doug Eck модернизировал эту модель, используя LSTM, которые могли дольше сохранять память о музыкальной последовательности. Вот немного LSTM Blues
Сейчас Дуг возглавляет инициативы Magenta в Google Brain, о которых мы поговорим чуть позже.
Музыка - это увлекательный вариант использования машинного обучения, поскольку это что-то вроде языка - в ней есть буквы, которые разворачиваются в композиции во времени, но в отличие от языка, одновременно можно воспроизводить несколько нот, их можно поддерживать в течение разных периодов времени, или могут быть периоды молчания, которые важны для всей композиции. Музыка - это одновременно искусство и язык.
Музыка, созданная с помощью машинного обучения
Вот пара современных примеров - автоматически сгенерированная песня, обученная (предположительно) в стиле Битлз (на самом деле есть гораздо лучшая песня под названием Баллада о мистере Шэдоу, написанная Гершвином и Коулом Портером)
Https://www.youtube.com/watch?v=LSHZ_b05W7o&
А вот IBM Watson Beat, который может создавать музыку на основе музыкальных подсказок:
Обратите внимание, что большая часть приведенной выше истории была взята из Средней статьи Кайла Макдональда.
Другой недавний подход заключался в использовании Audio Spectra для предсказания, а не основного языка музыки. Для этого используются сверточные нейронные сети. Вот более странный пример из Memo Akten:
Https://www.youtube.com/watch?v=htmVKWo7OXA&
Синтез речи
Синтез речи - это искусственное производство человеческой речи. Подумайте о том, что вы слышите, когда слушаете Siri или Alexa. Существуют различные реализации синтеза речи, некоторые из которых более успешны, чем другие:
Конкатенативный TTS (традиционный метод)
Запишите гигантскую базу данных предложений от одного голосового актера. Разделите их на части (например, слова или фразы), которые можно будет собрать в язык на основе того, что вы хотите сказать. Этот метод можно дополнить параметрическим TTS, который обеспечивает соблюдение грамматических правил.
Это реализация синтеза речи Google. Вместо того, чтобы смотреть на слова и грамматику, он смотрит на конкретные образцы аудио, очень похоже на то, как ИИ смотрит на изображение.
Он был обучен с использованием CNN для создания тонов со скоростью 24000 выборок в секунду с плавными переходами между этими тонами, чтобы сгладить промежутки между выборками. Он использует разрешение выборки в 16 бит (подумайте об этом как о плотности пикселей в изображении или DPI). Чем больше вы уменьшаете дискретизацию, тем больше тонкостей вы теряете.
На основе тональности: поскольку он основан на тональности, Wavenet может имитировать особенности человеческой речи, такие как шлепки губами, паузы и т. д., чтобы звучать более естественно.
На основе машинного обучения: вместо того, чтобы обеспечивать соблюдение правил, Wavenet позволяет алгоритмам машинного обучения выводить правила из записей. Попробуйте это с вашим собственным текстом.
Лирохвост
Программный запуск Speech Sythesis, который может записывать образцы вашего голоса для создания полностью автоматизированного голоса AI, который может говорить все, что угодно в вашем вокальном стиле. Это стало популярным, когда они имитировали голоса Дональда Трампа и Барака Обамы, по сути превратив их в марионеток, чтобы они говорили то, что Лирохвостик хотел, чтобы они сказали.

Https://soundcloud.com/user-535691776/dialog
Запишите свой голос с лирохвостом
Идеи для синтеза речи
- Создайте коллаж из голосов
- Запишите свой голос, имитирующий чужой голос
- Запишите свой голос, измененный по MIDI
- Измените голос Lyrebird с помощью MIDI / программного обеспечения
- Создавайте аудиоклипы со словами, записанными с ТВ / Музыка, чтобы обучить Lyrebird голосам другого человека (только для личного использования! См. Записи Трампа / Обамы для примера).
- Генерируйте текст с помощью LSTM / Predictive Writer, обученного на корпусе текста по вашему выбору, и озвучивайте его с помощью синтеза речи (Пример от Питера Берра).
ML за синтез речи
Хотя большая часть технологии является запатентованной, и поэтому ее очень сложно деформировать / реконструировать, в нашем распоряжении есть множество инструментов для компонентов синтеза речи! Типичный подход к анализу звука для использования в машинном обучении может быть следующим (чуть позже мы подробно рассмотрим каждый шаг):
Этапы анализа звука
- Запись аудио
- Вычислить аудио характеристики
- Частота MEL
- Оптимизировать
- Оценивать
- Разделите гармоники и перкуссию
- Определить питч-класс на Хромаграмме
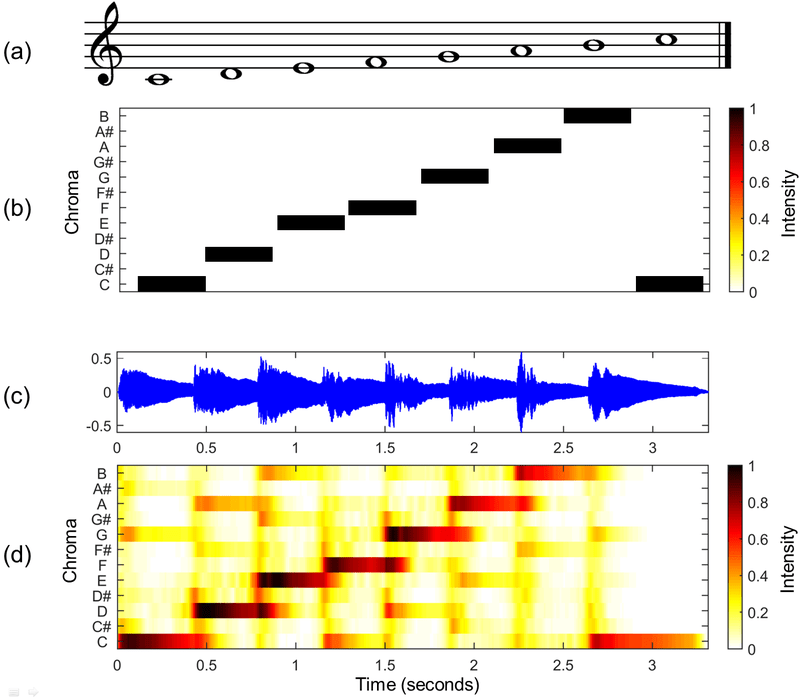
- Найдите события - когда в аудио происходят важные события
- Отслеживание ударов
- Вычисление функций - аналогично тому, как мы вычисляем функции на изображении.
- Выход
Соответствует реакции слуховой системы человека более точно, чем линейно разнесенные полосы частот в нормальном кепстре. MEL определяет характеристики звука и устраняет шум.
Единицей измерения является MFCC, который представляет текстуру или тембр звука.
Обратное искажение слова Spectrum (не спрашивайте меня…). Также известна как теорема обращения Фурье. Идея заключается в том, что если мы знаем частоту (количество повторений повторяющегося события в единицу времени) и фазу (положение в момент времени цикла формы волны) звуковой волны, тогда мы можем точно восстановить исходную волну. Это означает, что нам не обязательно иметь всю звуковую волну. Вот как мы можем создать что-то вроде Дональда Трампа, говорящего все, что мы хотим, чтобы он сказал.
Фурье?
Если вас вообще интересует звук, узнайте все, что можно, о БПФ (быстрое преобразование Фурье). Он разделяет сигнал на составляющие его частоты и позволяет нам делать всякие вещи (обратите внимание, что это относится к любому периодическому сигналу, а не только к звуку):
- Дифференциальные уравнения
- Спектрометрия
- Квантовая механика
- Обработка сигналов: Интернет, телефон, компьютер, Wi-Fi, спутники
По сути, БПФ позволяет нам преобразовать одну вещь в другую, а затем преобразовать обратно.
Спектр мощности: частота в непрерывном диапазоне. Человеческое ухо (улитка) вибрирует в разных точках в зависимости от частоты входящих звуков. В зависимости от частоты в мозгу возбуждаются разные нервы. Чем выше частота, тем сложнее мозгу различать.

Оптимизировать
Беря частоту и применяя логарифм. Мы не слышим громкость по линейной шкале. Чтобы удвоить воспринимаемую громкость звука, нам нужно вложить в него в 8 раз больше энергии. Итак, чтобы взять частоту и заставить ее звучать так, как мы на самом деле слышим, мы нормализуем ее по шкале MEL.
Оценка
Мы оцениваем траекторию частоты с помощью дельты. Это анализ спектра за определенный период времени.
Разделение вещей с высотой звука и вещей без них (например, битов). Для этого мы могли бы использовать анализ ритма, распознавание аккордов / тональности и т. Д. Или мы могли бы просто использовать преобразование Фурье.
Определите поля с помощью хроматограммы
Цветность - это набор всех высот, составляющих целое число октав. Хромаграмма отображает их для определения информации о классе высоты тона.
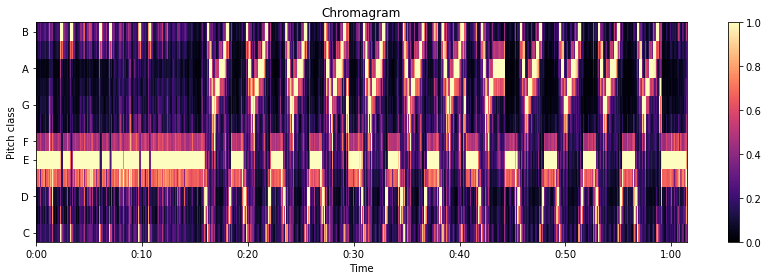
Отслеживание ударов
Возвращает BPM и индексы кадров ритмов.

После того, как мы определили доли, мы удаляем шум и оптимизируем
Вычислительные возможности
Возьмите MFCC вместе с их дельтами для каждого кадра в аудиоклипе, получите среднее значение и используйте его для создания вектора характеристик. Мы можем сделать это всего за одну секунду звука.
Приложения
Играть в Wolfenstein 3D с помощью голоса
Https://player.vimeo.com/video/207831279
Обнаружение высоты звука в ML5
Что такое Pitch?
Это характеристика музыкальных тонов, например длительность, громкость и тембр. Высота звука позволяет нам обозначать звук как более высокий или более низкий по частоте. Технически в ML5 мы определяем частоту.
В ML5 мы используем модель Crepe (расшифровывается как «представление свертки для оценки высоты звука»). Crepe, в отличие от предыдущих моделей, использует только информацию, полученную из данных, а не из оценки вероятности основного тона.
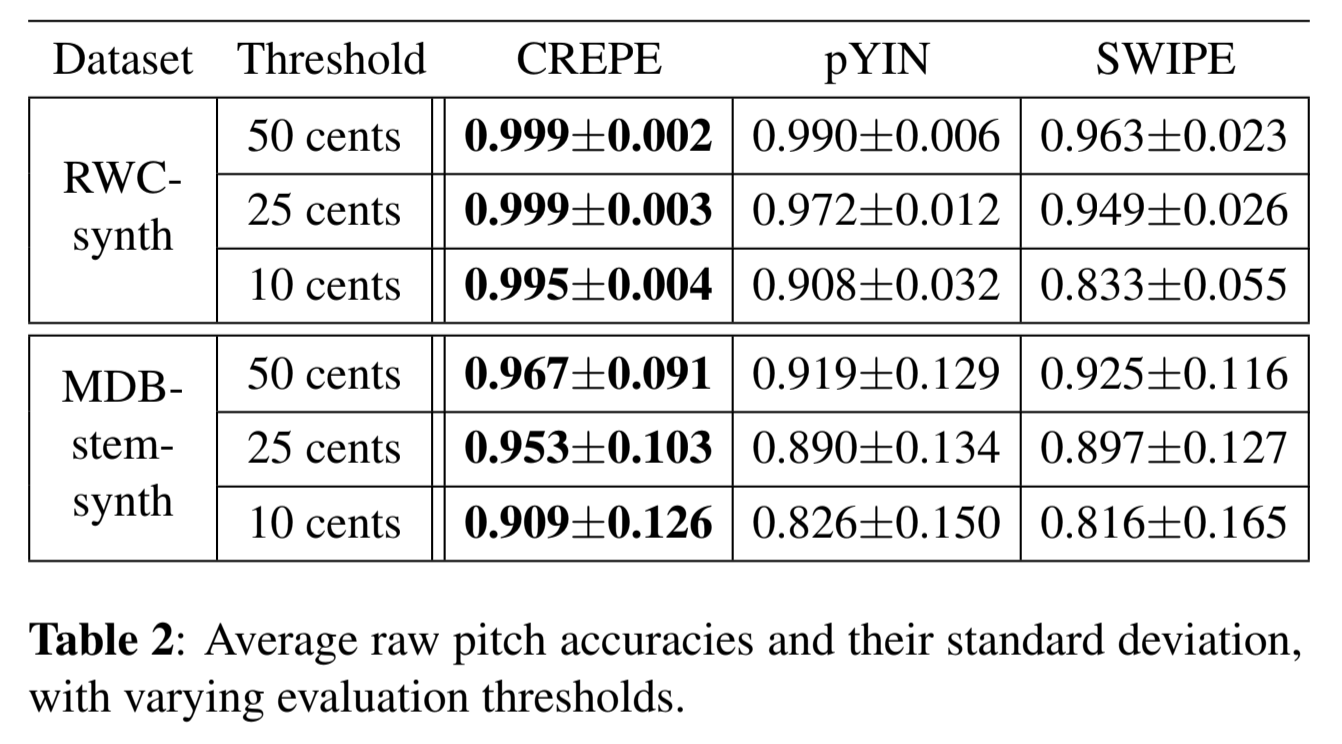
Цент - это единица, представляющая музыкальные интервалы относительно эталонной высоты звука в Герцах ( один цикл в секунду). Один цент = 10 Гц. Следовательно, чем больше центов, тем больше выборка, тем выше точность.
Обнаружение высоты тона в ML5
Файлы: 09-pitch-detect / 00-PitchDetection / sketch.js.
В этом примере можно получить звук только с микрофона компьютера.
Сначала устанавливаем шкалу:
const scale = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B'];
Затем включаем микрофон:
audioContext = getAudioContext();
mic = new p5.AudioIn();
mic.start(startPitch);
Загружаем Crepe Model и начинаем прослушивать высоту звука:
function startPitch() {
pitch = ml5.pitchDetection('./model/', audioContext , mic.stream, modelLoaded);
}
function modelLoaded() {
select('#status').html('Model Loaded');
getPitch();
}
Получив его, мы выводим частоту, полученную из ML5 / Tensorflow / Crepe, и назначаем ей ближайшую ноту на шкале:
pitch.getPitch(function(err, frequency) {
if (frequency) {
select('#result').html(frequency);
let midiNum = freqToMidi(frequency);
currentNote = scale[midiNum % 12];
select('#note').html(currentNote);
}
getPitch();
})
freqToMidi - это функция в ML5, которую мы вскоре рассмотрим.
Видишь этот% 12? Это называется оператором модуля, и в основном все, что он делает, это дает нам остаток от деления одного числа на другое. Таким образом, независимо от того, насколько высоко наш midiNum, он всегда будет соответствовать той шкале из 12 нот, которую мы определили в начале нашего кода.
Я понимаю это примерно так:

Чтобы лучше понять это, нам нужно заглянуть в код самого ML5.
Код за кулисами
Если мы посмотрим на исходный код библиотеки ML5, мы сможем более подробно изучить то, что происходит за кулисами. Большая часть обработки происходит в функции processMicrophoneBuffer:
const centMapping = tf.add(tf.linspace(0, 7180, 360), tf.tensor(1997.3794084376191));
Помните - центы - это доли шага. tf - это tensorflow, библиотека машинного обучения, выполняющая всю обработку за кулисами, и, изучив ее документацию, мы можем узнать, что linspace просто возвращает равномерно распределенную последовательность чисел.
Мы нормализуем данные, которые получаем с микрофона, чтобы оптимизировать их для более быстрой обработки:
const frame = tf.tensor(resampled.slice(0, 1024));
const zeromean = tf.sub(frame, tf.mean(frame));
const framestd = tf.tensor(tf.norm(zeromean).dataSync() / Math.sqrt(1024));
const normalized = tf.div(zeromean, framestd);
а затем сделайте прогноз частоты:
const activation = this.model.predict([input]).reshape([360]);
Почему 1024? Это наша частота дискретизации в герцах. Как только у нас есть прогноз, мы оцениваем достоверность, находим процент, в который попадает наша частота дискретизации (помните, что мы пытаемся уменьшить размеры), и вычисляем прогнозируемое значение в герцах для этой частоты.
const frame = tf.tensor(resampled.slice(0, 1024));
const zeromean = tf.sub(frame, tf.mean(frame));
const framestd = tf.tensor(tf.norm(zeromean).dataSync() / Math.sqrt(1024));
const normalized = tf.div(zeromean, framestd);
const input = normalized.reshape([1, 1024]);
const activation = this.model.predict([input]).reshape([360]);
const confidence = activation.max().dataSync()[0];
const center = activation.argMax().dataSync()[0];
this.results.confidence = confidence.toFixed(3);
const start = Math.max(0, center - 4);
const end = Math.min(360, center + 5);
const weights = activation.slice([start], [end - start]);
const cents = centMapping.slice([start], [end - start]);
const products = tf.mul(weights, cents);
const productSum = products.dataSync().reduce((a, b) => a + b, 0);
const weightSum = weights.dataSync().reduce((a, b) => a + b, 0);
const predictedCent = productSum / weightSum;
const predictedHz = 10 * (2 ** (predictedCent / 1200.0));
Затем, если наша уверенность превышает 50%, мы возвращаем результат. В противном случае мы продолжаем обработку.
const frequency = (confidence > 0.5) ? predictedHz : null;
this.frequency = frequency;
Откуда приходит freqToMidi? Библиотека звуков P5.js:
/**
* Returns the closest MIDI note value for
* a given frequency.
*
* @method freqToMidi
* @param {Number} frequency A freqeuncy, for example, the "A"
* above Middle C is 440Hz
* @return {Number} MIDI note value
*/
p5.prototype.freqToMidi = function (f) {
var mathlog2 = Math.log(f / 440) / Math.log(2);
var m = Math.round(12 * mathlog2) + 69;
return m;
};
AI Duet
Google AI Duet - это демонстрация с использованием Magenta, проекта искусственного интеллекта для обработки звука, в котором под капотом работает Tensorflow для машинного обучения аудио. Дуэт ИИ действует как виртуальное пианино, на котором мы будем играть, а ИИ будет пытаться аккомпанировать.

Откройте окно браузера и попробуйте пример. Попробуйте разные клавиши на клавиатуре - они будут играть разные ноты. Чем дольше вы их держите, тем дольше они выдержат. ИИ будет проверять, какие клавиши вы нажимаете и как долго вы их нажимаете. Затем он будет сопровождать ваши записи собственными нотами, пытаясь сопровождать (но не сопоставлять) ноты, которые вы сыграли.
Компоненты AI Duet
AI Duet состоит из ряда компонентов:
- Tensorflow - фреймворк машинного обучения, выполняющий всю обработку (как показано в ML5)
- Magenta - исследовательский проект компании Google Brain по созданию инструментов искусственного интеллекта для Art + Music.
- Nsynth - синтезатор Neural Audio, созданный на основе Magenta. Это состоит из:
- Набор музыкальных нот
- Волнообразная модель автоэнкодера, которая, по сути, узнает о себе и своих собственных вложениях. Они не являются причинными, как Wavenet, поэтому они видят весь блок данных:

- Tone.js - JavaScript-фреймворк для API веб-аудио, который делает музыку в браузере.
- Модели ML:
- Attention RNN - позволяет модели более легко получить доступ к прошлой информации без необходимости хранить эту информацию в состоянии ячейки RNN. Это позволяет модели более легко изучать долгосрочные зависимости и приводит к созданию мелодий с более длинными темами архивации. Чтобы получить обзор того, как работает механизм внимания, и услышать некоторые сгенерированные образцы мелодий, ознакомьтесь с сообщением в блоге.
- Pianoroll RNN-NADE - в отличие от мелодических RNN, эта модель должна быть способна моделировать несколько одновременных нот. Это достигается путем представления NoteSequence в виде пианино, названного в честь носителя, используемого для хранения партитуры для пианино игроков.
- Performance RNN - эта модель создает музыку на языке, аналогичном самому MIDI, с событиями note-on и note-off вместо явной продолжительности. Модель также поддерживает события скорости, которые устанавливают текущую скорость, используемую для последующих событий включения ноты.
- Drum Kit RNN - В отличие от мелодий, барабанные дорожки полифоничны в том смысле, что можно играть одновременно по нескольким барабанам. Несмотря на это, мы моделируем дорожку ударных как единую последовательность событий: а) отображая все различные MIDI-барабаны на меньшее количество классов ударных, и б) представляя каждое событие как одно значение, представляющее набор классов ударных, которые ударил.
Локальный запуск AI Duet
Одно дело запускать AI Duet в браузере. Но если мы хотим изменить его для наших собственных целей или взглянуть на его исходный код, нам нужно будет настроить его для локального запуска.
Во-первых, вам нужно убедиться, что у вас есть некоторые из основных зависимостей:
- Python 2.7. Если вы используете Python 3 или хотите иметь возможность запускать несколько версий python, вы можете подумать о загрузке Anaconda Navigator или использовать Conda, если вы разбираетесь в командной строке.
- PIP - менеджер пакетов Python (вроде как менеджер плагинов)
- NodeJS
- Загрузите код с github (нажмите зеленую кнопку клонирования или загрузки и загрузите zip-файл). Разархивируйте файл в папку по вашему выбору.
В этой папке нам потребуется запустить локальный сервер, чтобы использовать пурпурный, тензорный поток и модели машинного обучения, которые они приносят с собой. Из командной строки перейдите в каталог сервера:
cd сервер
и запустите команду
pip install -r requirements.txt
Помните, что PIP - это менеджер пакетов, который позволяет python устанавливать все необходимые плагины для проекта. Если мы посмотрим на файл requirements.txt в редакторе кода, то увидим следующее:
tensorflow==0.12.1
magenta==0.1.8
Flask==0.12
gunicorn==19.6.0
ipython==5.1.0
Мы знаем о тензорном потоке и мадженте. Flask имеет набор инструментов, полезных для создания веб-сайтов, Gunicorn полезен для запуска веб-серверов, а iPython - это фреймворк для Jupyter, очень распространенной среды для программирования Python и машинного обучения.
Предполагая, что у вас нет ошибок при установке требований к серверу, вы сможете запустить
python server.py
который запускает локальный веб-сервер по адресу http: // localhost: 8080 /.
Затем, чтобы действительно просмотреть опыт, нам нужно установить все клиентские зависимости (код, отвечающий за то, что мы можем видеть в браузере). Для этого выполните следующий код:
cd static
npm install
npm run build
В статическом каталоге живет весь наш внешний код. NPM - это менеджер пакетов node.js. Это похоже на PIP в Python: упрощает установку плагинов, расширяющих возможности нашей кодовой базы. NPM. Так что он устанавливает? А что это за строительство?
NPM ищет файл package.json для установки своих зависимостей, так же, как PIP использовал файл requirements.txt. Если мы посмотрим на этот файл, мы увидим список из целого ряда зависимостей:
"autoprefixer-loader": "^3.2.0",
"babel-core": "^6.17.0",
"babel-loader": "^6.2.5",
"babel-polyfill": "^6.20.0",
"babel-preset-es2015": "^6.16.0",
"buckets-js": "^1.98.1",
....
Изучение того, что делает каждая из этих вещей, может выходить за рамки этого курса. Мы здесь не для того, чтобы изучать интерфейсную веб-разработку, мы здесь, чтобы разбираться в машинном обучении. Но хорошо видеть, что происходит, чтобы знать, где искать, если мы хотим изменить код для наших собственных целей. В данном случае это все пакеты кода npm, написанные другими людьми и предоставленные нам для использования в целях создания отличного опыта.
Однако есть еще одна вещь, на которую мы должны обратить внимание в этом файле:
"scripts": {
"build": "webpack -p",
"watch": "webpack -w"
},
Это наша команда сборки, которую мы выполнили при запуске npm run build. Мы поговорим об этом чуть позже, но для упрощения эта команда оптимизирует наш код и сохраняет файл Main.js в каталоге сборки. Как только мы запустим его, мы можем открыть наш браузер по адресу http: // localhost: 8080 / и просмотреть опыт. Все должно работать так же, как и во время эксперимента с хромом, описанного выше.
Чтобы понять, что происходит под капотом, нам нужно посмотреть, что происходит на стороне сервера (серверная часть) и браузера (интерфейсная часть).
Сервер AI Duet
Если мы посмотрим на server.py, мы сможем лучше понять, за что он отвечает:
from predict import generate_midi
import os
from flask import send_file, request
import pretty_midi
import sys
if sys.version_info.major <= 2:
from cStringIO import StringIO
else:
from io import StringIO
import time
import json
from flask import Flask
app = Flask(__name__, static_url_path='', static_folder=os.path.abspath('../static'))
Эти первые несколько строк импортируют все зависимости, необходимые для файла сервера. Вы можете заметить несколько вещей, которых мы раньше не видели, например, от predic import generate_midi. В этом случае предикция ссылается на файл pred.py нашего каталога, который мы рассмотрим через секунду. generate_midi - это имя функции в этом файле.
Нам не нужно понимать все, что здесь происходит, но полезно знать, что на основе импорта мы будем использовать некоторые midi, каким-то образом отслеживать время, получать доступ к данным в форме json и т. Д. последняя строка сообщает Flask, что мы будем обслуживать наше приложение из статического каталога.
@app.route('/predict', methods=['POST'])
def predict():
now = time.time()
values = json.loads(request.data)
midi_data = pretty_midi.PrettyMIDI(StringIO(''.join(chr(v) for v in values)))
duration = float(request.args.get('duration'))
ret_midi = generate_midi(midi_data, duration)
return send_file(ret_midi, attachment_filename='return.mid',
mimetype='audio/midi', as_attachment=True)
Этот маршрут на самом деле является URL-адресом. Если мы отправим какие-либо данные по пути / predicter нашего базового URL (в данном случае localhost), этот маршрут загрузит эти данные и вызовет функцию в библиотеке pretty_midi, чтобы вернуть midi как фактический пригодный для использования звуковой файл, а не чем просто данные с веб-сервера. Помните, что функция generate_midi находится в файле predic.py.
@app.route('/', methods=['GET', 'POST'])
def index():
return send_file('../static/index.html')
if __name__ == '__main__':
app.run(host='127.0.0.1', port=8080)
Этот / route - это просто корневой каталог по умолчанию. Когда мы вводим его в строку URL, он обслуживает файл index.html, который отвечает за отображение всего веб-контента, который мы видим в браузере. Ниже мы видим, что хост нашего сайта - 127.0.0.1, который является адресом по умолчанию для localhost, а порт - 8080.
Прогнозирование AI Duet
Файл predic.py содержит много кода, который мы используем, чтобы делать прогнозы о том, какие ноты играть, на основе того, какие ноты играл пользователь. Судя по импорту в верхней части файла, вы заметите, что файл будет иметь пурпурный цвет:
import magenta
from magenta.models.melody_rnn import melody_rnn_config_flags
from magenta.models.melody_rnn import melody_rnn_model
from magenta.models.melody_rnn import melody_rnn_sequence_generator
from magenta.protobuf import generator_pb2
from magenta.protobuf import music_pb2
Один из вариантов импорта - из melody_rnn. Если бы мы исследовали исходный код этой модели, мы бы узнали, что он отвечает за создание мелодий. Помните РНС? Чтобы сделать мелодию, нам понадобится более одной ноты. Мелодия RNN является повторяющейся, то есть она может оглядываться на то, что игралось раньше, чтобы знать, что играть дальше.
def generate_midi(midi_data, total_seconds=10):
primer_sequence = magenta.music.midi_io.midi_to_sequence_proto(midi_data)
# predict the tempo
if len(primer_sequence.notes) > 4:
estimated_tempo = midi_data.estimate_tempo()
if estimated_tempo > 240:
qpm = estimated_tempo / 2
else:
qpm = estimated_tempo
else:
qpm = 120
primer_sequence.tempos[0].qpm = qpm
generator_options = generator_pb2.GeneratorOptions()
# Set the start time to begin on the next step after the last note ends.
last_end_time = (max(n.end_time for n in primer_sequence.notes)
if primer_sequence.notes else 0)
generator_options.generate_sections.add(
start_time=last_end_time + _steps_to_seconds(1, qpm),
end_time=total_seconds)
# generate the output sequence
generated_sequence = generator.generate(primer_sequence, generator_options)
output = tempfile.NamedTemporaryFile()
magenta.music.midi_io.sequence_proto_to_midi_file(generated_sequence, output.name)
output.seek(0)
return output
Наконец, вот функция generate_midi. Это довольно сложно, поэтому мы не будем вдаваться в подробности, но если мы попытаемся изучить его, мы увидим, что он использует функцию Estimation_tempo () Pretty MIDI, чтобы анализировать данные и угадывать, насколько быстро ноты были сыграны. Пока этот темп составляет менее 240 (уд / мин), он воспроизводится с расчетной скоростью. В противном случае значение по умолчанию составляет 120 ударов в минуту.
Он вызывает generator.generate (), чтобы получить последовательность заметок, где генератор был определен в верхней части файла как:
generator = melody_rnn_sequence_generator.MelodyRnnSequenceGenerator(
model=melody_rnn_model.MelodyRnnModel(config),
details=config.details,
steps_per_quarter=steps_per_quarter,
bundle=bundle_file)
и записывает это как фактический файл через функцию пурпурного sequence_proto_to_midi_file (). Теперь мы можем воспроизвести этот файл в нашем браузере. Чтобы посмотреть, что происходит в браузере, давайте рассмотрим статическую папку, в которой находится весь код для интерактивных компонентов AI Duet Live.
Взаимодействие AI Duet
Лучше всего начать с index.html. Помните, что это файл, который сервер загружает по умолчанию. Как правило, для любой веб-страницы index.html является файлом по умолчанию, который обслуживается каждый раз, когда вы вводите адрес в адресную строку браузера. Давайте посмотрим на это:
<!DOCTYPE html>
<html>
<head>
<title>A.I. DUET</title>
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<meta name="description" content="AI DUET">
<link href="https://fonts.googleapis.com/css?family=Quicksand:400,700" rel="stylesheet">
<script type="text/javascript" src="build/Main.js"></script>
<link rel="icon" type="image/png" href="./images/AIDuet_16.png" sizes="16x16">
<link rel="icon" type="image/png" href="./images/AIDuet_32.png" sizes="32x32">
<link rel="icon" type="image/png" href="./images/AIDuet_152.png" sizes="152x152">
<link rel="icon" type="image/png" href="./images/AIDuet_196.png" sizes="196x196">
</head>
<body>
</body>
</html>
Это действительно просто! За кулисами должно происходить гораздо больше событий, о которых мы не знаем, потому что по большей части этот код ничего не делает. Самая полезная информация здесь - это строка:
<script type="text/javascript" src="build/Main.js"></script>
Здесь загружается наш файл javascript. Этот файл должен отвечать за создание всего того, что мы видим в браузере. Но попробуйте открыть Main.js из каталога / build…
Ого, это бесполезно. Это миниатюрный код. Он разработан как можно более компактным и лаконичным, чтобы загружать его быстрее и работать лучше. Если бы мы действительно хотели увидеть, что делает этот файл, нам понадобился бы исходный код.
К счастью, наша загрузка содержит именно это. В папке src есть еще один файл Main.js, из которого был сгенерирован файл build / Main.js. Этот намного понятнее.
Если честно, то и в этом файле мало что происходит. Так почему же другой файл Main.js был таким большим? Главное отметить, что этот исходный файл импортирует множество других файлов:
import {Keyboard} from 'keyboard/Keyboard'
import {AI} from 'ai/AI'
import {Sound} from 'sound/Sound'
import {Glow} from 'interface/Glow'
import {Splash} from 'interface/Splash'
import {About} from 'interface/About'
import {Tutorial} from 'ai/Tutorial'
Вы увидите, что они соответствуют другим папкам и файлам в каталоге src. И эти файлы могут импортировать собственный код. Это начинает быть довольно глубокой кроличьей норой. На данный момент все, что нас интересует, это тот факт, что когда мы запускаем npm run build - он берет Main.js и весь код, который он импортирует, и весь код, который он импортирует, и объединяет его в один file mumbo jumbo файл, который будет обслуживаться при загрузке вашего веб-браузера.
Внесение изменений в AI Duet
Итак, как бы нам перепрофилировать этот код или внести изменения, которые мы действительно могли бы увидеть в браузере? Файл javascript, который ищет браузер, - это файл build / Main.js. Но мы, очевидно, не можем этого изменить. Мы с трудом можем это прочитать. Все наши изменения должны происходить в каталоге src, где все имеет смысл.
После внесения изменений мы можем снова собрать наш код с помощью npm run build, обновить браузер и увидеть, как эти изменения отражаются.
Придется ли нам создавать код каждый раз, когда мы вносим крошечные изменения? Если мы хотим увидеть это в браузере, да. К счастью, есть кое-что, что нам поможет. Помните часть скриптов в нашем файле package.json? Прямо под сборкой находится еще одна команда, смотри. Если бы мы открыли другое окно терминала и запустили npm run watch - эта команда будет искать изменения, которые мы вносим в каталог src, и автоматически компилировать их каждый раз, когда что-то меняется. Итак, все, что нам нужно сделать, это обновить браузер.
Так делается самая современная корпоративная веб-разработка, и AI Duet не исключение. Итак, помимо машинного обучения, вы можете сказать, что немного узнали об одной из самых передовых концепций веб-разработки!
Итак, теперь, когда мы знаем, как изменить код, что нам следует изменить? Возможности безграничны, но вот несколько идей:
- Изменение внешнего вида полос
За отображение полосок отвечает файл Roll.js.
Если мы посмотрим на этот файл, то увидим, что цветные полосы, выходящие из фортепиано, были отрисованы с помощью Three.js, библиотеки webGL / 3D для javascript. Если вы уже разбираетесь в 3D или у вас есть желание учиться, вы могли бы сделать из-за этого некоторые довольно интересные вещи. А пока посмотрите, можете ли вы изменить цвет полос.
- Измените сами звуковые файлы
Прямо сейчас у нас есть довольно стандартная MIDI-клавиатура. Но звуки могут быть любыми, даже собственным голосом. Как? Перебирая исходные файлы, мы видим файл под названием Sound.js. Кажется, это хорошее место для начала.
Этот файл тоже довольно интуитивно понятен. Похоже, что большая часть работы выполняется здесь:
keyDown(note, time=Tone.now(), ai=false){
if (note >= this._range[0] && note <= this._range[1]){
this._piano.keyDown(note, time)
if (ai){
this._synth.volume = -8
this._synth.keyDown(note, time)
}
}
}
keyUp(note, time=Tone.now(), ai=false){
if (note >= this._range[0] && note <= this._range[1]){
time += 0.05
this._piano.keyUp(note, time)
if (ai){
this._synth.keyUp(note, time)
}
}
}
Особый интерес представляет то, что задействованы два инструмента: _piano и _synth. Эти инструменты определены в коде вверху файла:
this._piano = new Sampler('audio/Salamander/', this._range)
this._synth = new Sampler('audio/string_ensemble/', this._range)
и справочные каталоги этих семплеров: audio / Salamander и audio / string_ensemble. Если мы найдем эти каталоги, то мы обнаружим кучу файлов .mp3, названных в соответствии с примечаниями, которые они представляют: A0.mp3, C4.mp3 и т. Д.
Поэтому, если мы хотим изменить воспроизводимые ноты, мы могли бы просто заменить эти звуковые файлы. Если вы посмотрите на файл string_ensemble_README, вы увидите, что эти заметки были созданы как часть звукового шрифта:
- Fluid-Soundfont
- Generated from [FluidR3_GM.sf2](http://www.musescore.org/download/fluid-soundfont.tar.gz)
Звуковые шрифты - это форматы для упаковки и воспроизведения MIDI-нот, и вы можете легко найти их в Интернете. Обычно они бывают в формате sf2 или sfz. Для их преобразования мы можем использовать такую программу, как Полифон.
В Polyphone вы должны нажать значок «Открыть папку» и выбрать файл звукового шрифта, который вы используете. В этом файле должны быть образцы, которые вы можете прослушать. Выберите нужные образцы и нажмите «Файл» ›« Экспортировать образцы », чтобы экспортировать выбранные образцы в виде файлов .wav.

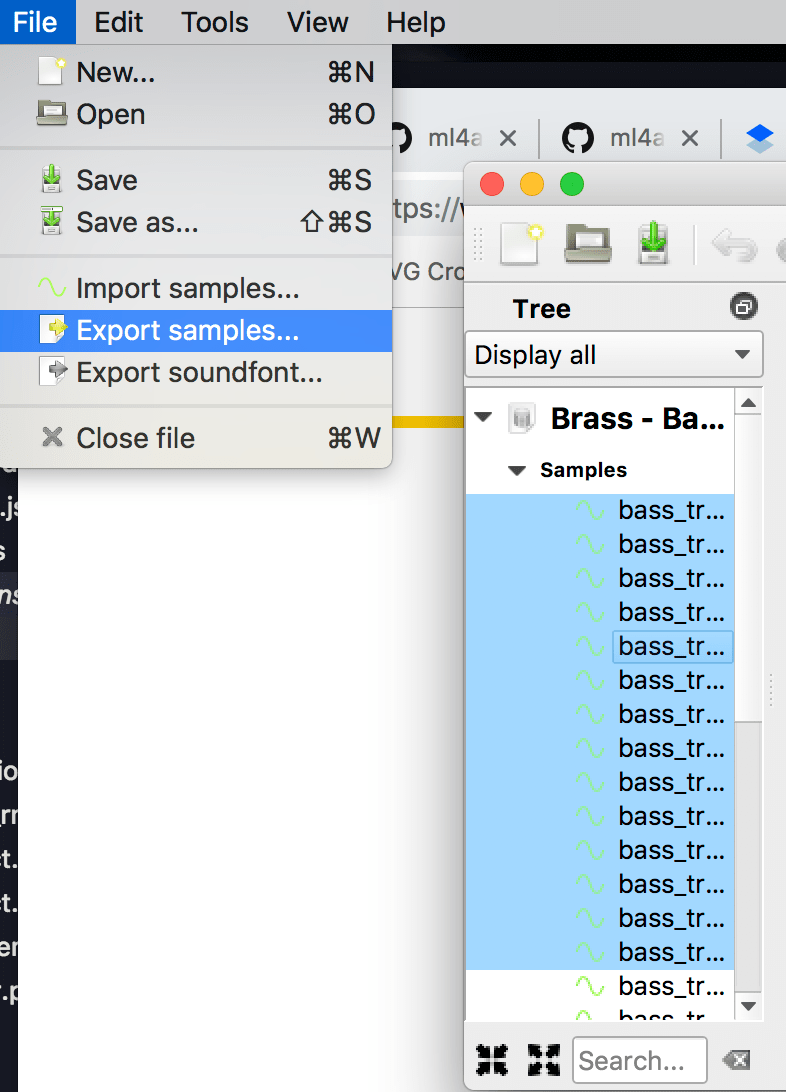
Конечно, AI Duet нужны файлы .mp3, которые мы можем сгенерировать с помощью такой программы, как Audacity. У него даже есть возможность конвертировать файлы в пакетном режиме с помощью (без интуитивно понятного названия) Файл ›Применить цепочки› Преобразование в MP3. Найдите свои файлы WAV, нажмите ОК, и ваши преобразованные MP3-файлы будут созданы в каталоге, который называется (также не интуитивно) очищенным.
Когда у нас есть новые файлы, нам просто нужно дать им имена в соответствии с примечаниями, которые они представляют, а затем поместить их в папку проекта. Мы могли бы просто перезаписать существующие файлы в одном из каталогов или создать новую папку и изменить ссылку на папку в коде:
this._piano = new Sampler('audio/[YOUR_FOLDER]/', this._range)
- Изменение поведения самого ИИ
Все это полезно, но что, если мы хотим изменить поведение самого ИИ? Папку ai имеет смысл посмотреть. В этом файле не происходит настоящего искусственного интеллекта, как следует из названия, но есть метод отправки, который может нам помочь.
request.load(`./predict?duration=${endTime + additional}`, JSON.stringify(request.toArray()), 'POST').then((response) => {
...
})
Он вызывает маршрут ./predict. Мы увидели это, когда впервые начали просматривать файлы. Это в server.py:
@app.route('/predict', methods=['POST'])
def predict():
now = time.time()
values = json.loads(request.data)
midi_data = pretty_midi.PrettyMIDI(StringIO(''.join(chr(v) for v in values)))
duration = float(request.args.get('duration'))
ret_midi = generate_midi(midi_data, duration)
return send_file(ret_midi, attachment_filename='return.mid',
mimetype='audio/midi', as_attachment=True)
Теперь, видите эту функцию generate_midi ()? Мы уже смотрели на это раньше. Здесь мы просим модель дать нам несколько заметок. generate_midi () определен во втором просматриваемом нами файле, predic.py.
Вверху этого файла есть полезная информация:
generator = melody_rnn_sequence_generator
Итак, melody_rnn - это то, что генерирует музыку. И это часть пурпурного:
from magenta.models.melody_rnn import melody_rnn_model
И мы видим здесь пурпурный исходный код. Это требует некоторых усилий, но иногда это именно то, что необходимо, чтобы получить уникальные результаты и по-настоящему понять, что происходит в ИИ. Если мы прочитаем README для Melody RNN, мы узнаем, что он может использовать несколько моделей: базовую, ретроспективную и внимательную. И мы пользуемся вниманием:
BUNDLE_NAME = 'attention_rnn'
config = magenta.models.melody_rnn.melody_rnn_model.default_configs[BUNDLE_NAME]
bundle_file = magenta.music.read_bundle_file(os.path.abspath(BUNDLE_NAME+'.mag'))
Итак, мы могли бы попробовать использовать другую модель:
BUNDLE_NAME = 'lookback_rnn'
Но, как мы видим выше, ретроспективный анализ требует наличия файла .mag. Мелодия РНН предоставляет таковые в ридми. Загрузить ретроспективный обзор. Куда мы его положим? Ну а где Внимание_rnn.mag? Выполните поиск в редакторе кода. Если вы используете VSCode, вы можете нажать CMD + P и ввести .mag. Он находится в папке сервера. Также поместите туда lookback_rnn.
Поскольку это на стороне сервера, нам нужно будет остановить и перезапустить сервер. Откройте окно терминала, в котором вы запустили сервер, и нажмите ctrl + c. Затем снова запустите python server.py. Если вы когда-нибудь захотите запустить команду, которую выполняли в прошлом, и забудете, что это было, вы можете нажать стрелку вверх в приглашении терминала, чтобы прокрутить назад свои команды. Или вы можете нажать CTRL + R и начать вводить биты того, что вы могли набрать, и терминал будет искать самое последнее, что вы ввели, что соответствует.
Обновите страницу в браузере и попробуйте сыграть сейчас. Заметили разницу? Я тоже, это может быть незаметно. Но это не значит, что это была пустая трата времени. Если мы хотим получить более заметные результаты, мы можем обучить нашу собственную модель на наших собственных звуковых файлах. Или мы могли бы поменять мелодии на другую предварительно обученную модель. Может быть, Drums_RNN для битов?
Возможно, это выходит за рамки этого курса, но, надеюсь, это дало вам представление о том, как машинное обучение используется в музыке, а также о том, как взять существующий код и использовать его в своих целях.
Еще примеры ML в музыке
"код"
С помощью Google Cloud Vision Камера определяет то, что видит на вашем телефоне, записывает об этом песню с помощью синтеза речи и создает вокальные интонации с помощью MaryTTS. Tone.js помогает с битами.

Код | "Играть"
"код"

Код | "играть"
Домашнее задание
- Найдите несколько интересных примеров ML в Audio / Music. Придумайте проект, который вы могли бы реализовать, используя уже полученные знания.
- Обучите ИИ определенным звукам с помощью oFX Audio Classifier и используйте этот вывод для управления приложением, которое может работать с OSC.
- Будьте в курсе машинного обучения! Он быстро развивается ...
Будущее машинного обучения в музыке
В то время как такие вещи, как Wavenet, медленно обучаются, но очень убедительны в своей музыкальной продукции, а DeepMind Tacotron генерировал быстро, но не мог ответить на некоторые из шумов и полифонических звуков в музыкальных записях, Tacotron2 будет использовать сети с медленным обучением. чтобы научить быстро генерируемые архитектуры.
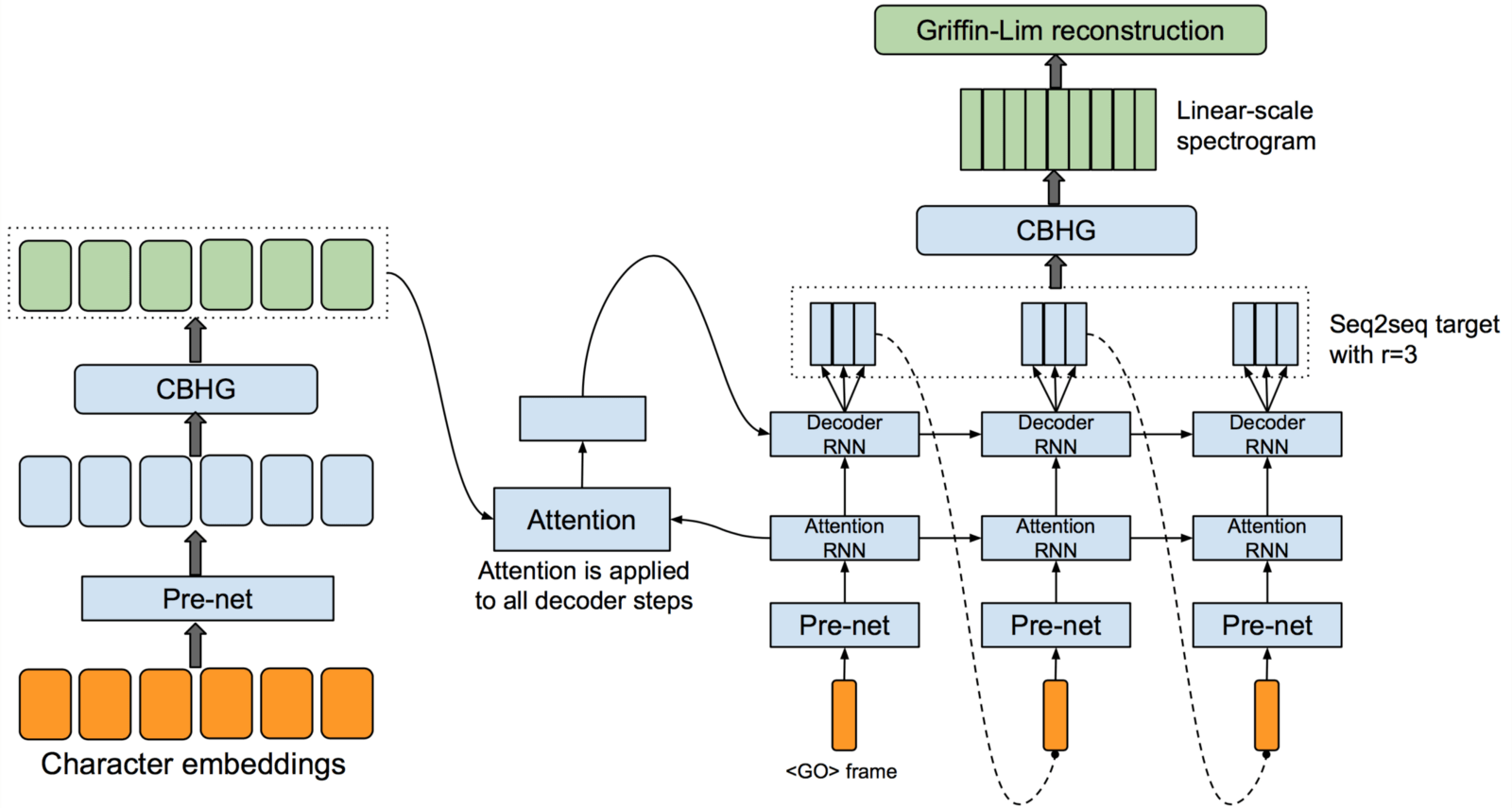
Будущее машинного обучения музыки может включать в себя нейронные сети, генерирующие хитовые песни. Но он также имеет огромный потенциал для сотрудничества с артистами, становясь еще одним инструментом в распоряжении артиста, способным к гранулированному количественному анализу и крупномасштабному синтезу музыки, который мы только интуитивно понимаем.