Это первая часть серии статей, посвященных анализу данных и машинному обучению на JVM с Scala с использованием таких библиотек, как Smile, Deeplearning4j и EvilPlot. Полный код этого сообщения в блоге можно найти на GitHub.
Как человек, который любит находиться на открытом воздухе, погода играет важную роль в моей жизни. Поскольку мне также очень нравится экспериментировать с данными и машинным обучением, я задавался вопросом, в какой степени методы машинного обучения можно применять для прогнозирования погоды. Конечно, любая серьезная попытка - и я уверен, что такие попытки предпринимаются в то время, когда я пишу эту статью, потребует доступа к большим объемам данных о погоде, а также значительных вычислительных ресурсов. Однако не в этом суть этой серии сообщений в блоге. Я хотел знать, насколько хорошо я могу справиться со своими довольно скромными ресурсами, используя данные, которые находятся в свободном доступе.
Поскольку я живу в Вене, для меня наиболее естественным делом было бы делать прогнозы для моего родного города. Однако затем я нашел очень подробные исторические данные о погоде от meteoblue для Базеля, которые находятся в свободном доступе, и решил, что это прекрасно послужит моей цели.
Для начала я решил загрузить CSV, содержащий одну строку для каждого дня, вплоть до января 1985 года. Также доступны данные с почасовым разрешением, но я хотел, чтобы они были простыми. Всего 45 столбцов, в том числе
- год, месяц и день
- температура (мин., среднее, макс.)
- суммарное суточное количество осадков и снегопадов
- давление (мин., среднее, макс.)
- влажность (мин., среднее, макс.)
- направление и скорость ветра (мин., среднее, макс.) на разной высоте
- высокая, средняя и низкая облачность (мин., среднее, макс.)
- продолжительность солнечного сияния
Я преобразовал этот файл в Seq[Map[String, Double]], где каждый Map[String, Double] содержит данные за один день, упорядоченные по именам столбцов.
Чтобы получить представление о данных, давайте воспользуемся EvilPlot, чтобы немного изучить их. Сначала давайте построим минимальную, среднюю и максимальную температуру для каждого дня в июле 2018 года:
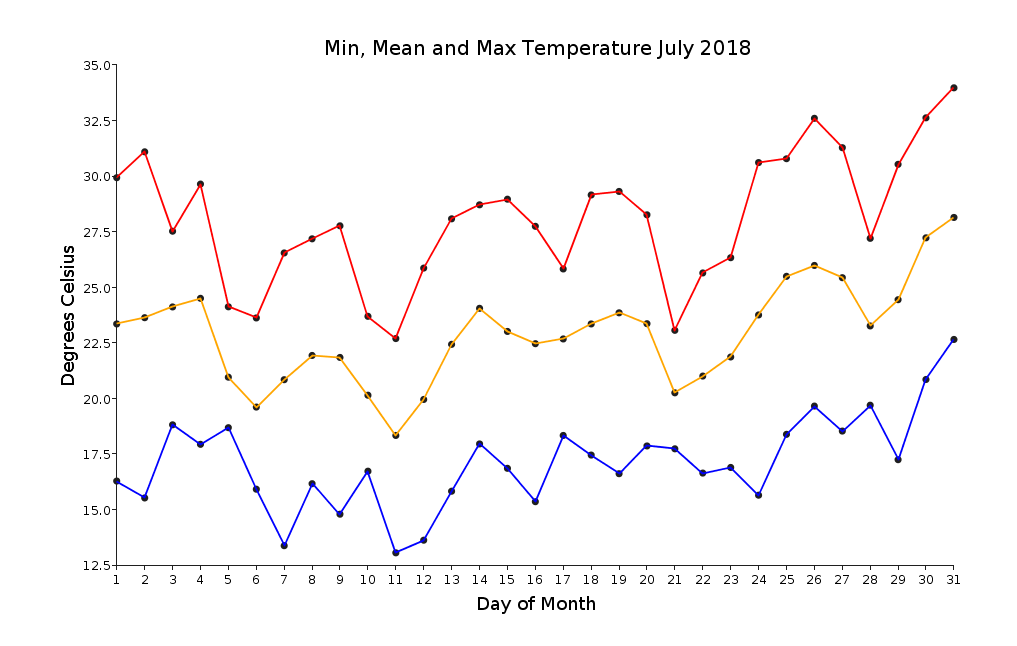
Выполнение этого с помощью EvilPlot - действительно полезный опыт, и это достигается с помощью следующего фрагмента кода:
Обратите внимание, что, поскольку я проанализировал CSV в Seq[Map[String, Double]], такие выражения, как r(Column), просто выбирают соответствующий столбец в строке r. Вот еще один график, на котором показаны минуты солнечного сияния и миллиметры дождя за июль 2018 года:
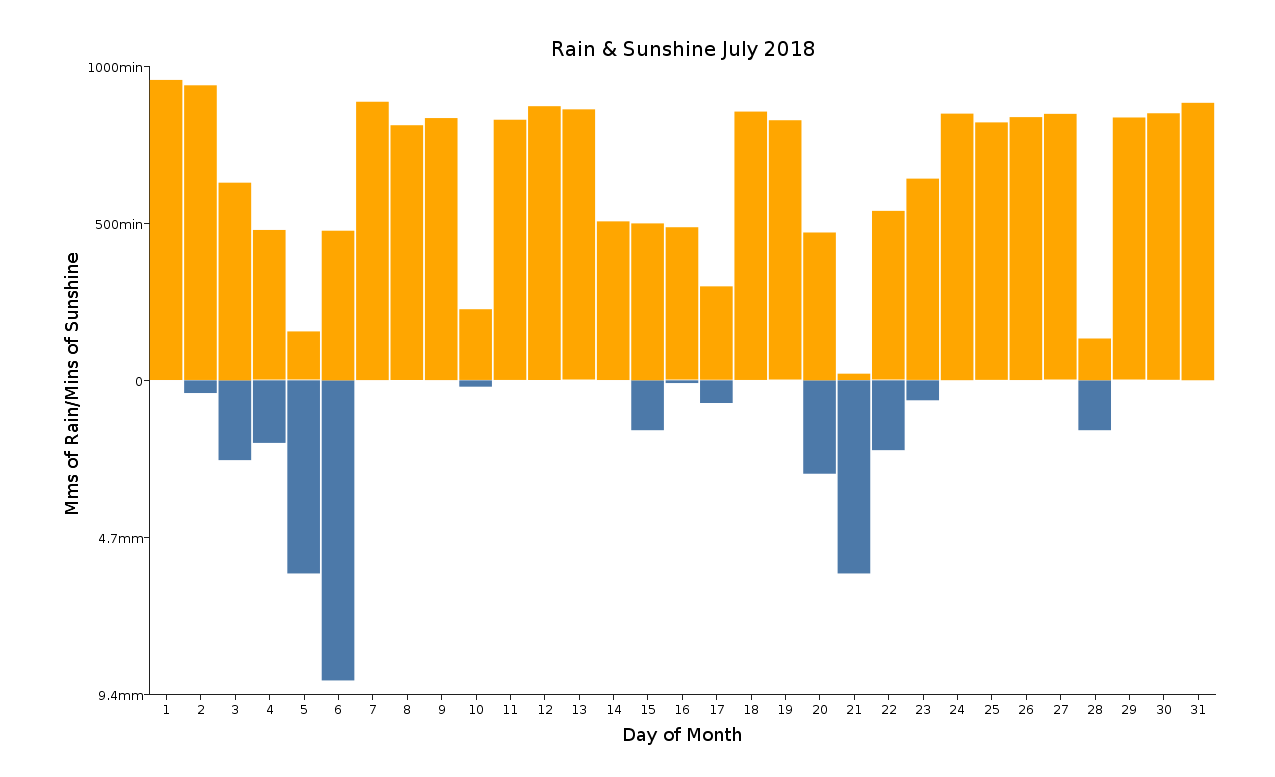
Этот график был создан с помощью следующего фрагмента:
Именно суточное количество осадков, представленное синими полосами на графике выше, мы хотим спрогнозировать, используя данные за предыдущие дни.
Прежде чем использовать сложные модели, давайте посмотрим на производительность некоторых очень простых базовых алгоритмов. Если мы не можем превзойти их со значительным отрывом, наши данные либо в основном представляют собой помехи, либо наши модели просто не стоят того. Если вас интересует некоторая предыстория, подумайте о прочтении Как (не) использовать машинное обучение для прогнозирования временных рядов.
Наши модели будут реализовывать следующий интерфейс:
Одна из самых простых моделей, которую можно себе представить, - это так называемая модель персистентности. Он просто предсказывает, что сегодня будет таким же, как вчера, в коде
Другой, очень простой алгоритм - просто все время прогнозировать постоянное значение:
Установка этой константы равной среднему из наблюдаемых целевых значений минимизирует ошибку обучения, если мы будем использовать среднеквадратичную ошибку в качестве меры производительности. Чтобы получить такой предиктор из обучающих данных, мы реализуем следующий признак, который позже также будет использоваться более интересными моделями:
Реализация, которая просто возвращает предсказатель постоянного значения для среднего значения обучающих данных, может выглядеть так:
Хотя на данном этапе это имеет лишь ограниченный смысл, это поможет при проведении сравнений позже, поэтому перед оценкой этих моделей мы разделяем наши данные на обучающие и тестовые наборы, используя разделение 80:20:
Используя это разбиение, мы получаем следующие результаты с нашими тривиальными алгоритмами, определенными выше (RMSE означает среднеквадратичную ошибку, а MAE означает среднюю абсолютную ошибку):
Обратите внимание, что RMSE этих моделей различаются, в то время как MAE почти идентичны. Это указывает на то, что модель постоянства делает меньше ошибок, но когда это так, эти ошибки более серьезны. В любом случае, эти цифры довольно высоки, если иметь в виду, что среднее дневное количество осадков в Базеле составляет около 2,5 мм, а медиана - 0,1 мм. В следующем посте этой серии мы увидим, сможем ли мы лучше использовать некоторые из алгоритмов регрессии от Smile.