
Пример: узкие места в сети на сервере Linux: часть 2 - ядро
В предыдущей статье я рассмотрел некоторые потенциальные узкие места, связанные с самой сетевой картой. В этой статье мы рассмотрим некоторые полезные настройки ядра и их влияние на сетевой трафик.
Сериал разделен (скорее всего) на эти четыре части:
- Часть 1: NIC
- Часть 2: Ядро (эта статья)
- Часть 3. Прерывания
- Часть 4. Дальнейшие шаги
В первой части мы увидели, что такое кольцевой буфер сетевого адаптера и как его можно настроить. В нашем случае эти настройки решили только первую часть нашей проблемы, а после исправления выявили еще одно узкое место, расположенное ниже (вверх?) Модели OSI. У нас все еще было узкое место, поэтому следующий вопрос был: Так что же происходит с нашими пакетами после NIC?
Наблюдение
После проблем с сетевыми адаптерами, которые мы рассмотрели в предыдущей статье, следующим наблюдением стала корреляция между обрывом соединения в пиковое время и увеличением количества пакетов, о которых сообщалось как о «свернутых» и «сокращенных». Спад обычно начинался нарастать примерно за час до обрезки. При отслеживании Grafana это выглядело примерно так для свернутых пакетов:

И для обрезанных пакетов:

Два приведенных выше графика относятся к разным дням и показывают разные временные масштабы; они не предназначены для того, чтобы показать корреляцию между ними, а только для того, чтобы показать, что они оба указали на рост в какой-то момент времени.
Если вы погуглите, чтобы лучше понять, что означает концепция сворачивания и отсечения пакетов, вы можете оказаться на странице Википедии о контроле за перегрузкой, что (для меня) не имело большого смысла. Ниже я опишу это в соответствии со своим собственным пониманием.
Буфер сокета ядра
Следующее место, где хранятся пакеты, - это буфер сокета ядра. В основном это выполняется следующим образом:
- Сетевая карта помещает новый полученный пакет в свой собственный кольцевой буфер,
- Затем ядро выполняет нечто, называемое «прерыванием» (тема следующей части этой серии), которое является своего рода запросом ядра у сетевого адаптера, есть ли какие-либо необработанные пакеты в кольцевом буфере сетевого адаптера, и если они:
- Ядро копирует пакетные данные из кольцевого буфера сетевого адаптера в часть ОЗУ машины, выделенную для ядра, в так называемый «буфер приема сокета»,
- В конце концов, сетевая карта удалила пакет из собственного кольцевого буфера, чтобы освободить место для будущих пакетов.
Вероятно, вышеперечисленное зависит от того, какую систему вы используете, но в основном это происходит именно так.
Фактически имеется два буфера сокета; один буфер приема и один буфер записи. Здесь можно увидеть простую визуализацию двух разных машин, которые разговаривают друг с другом:
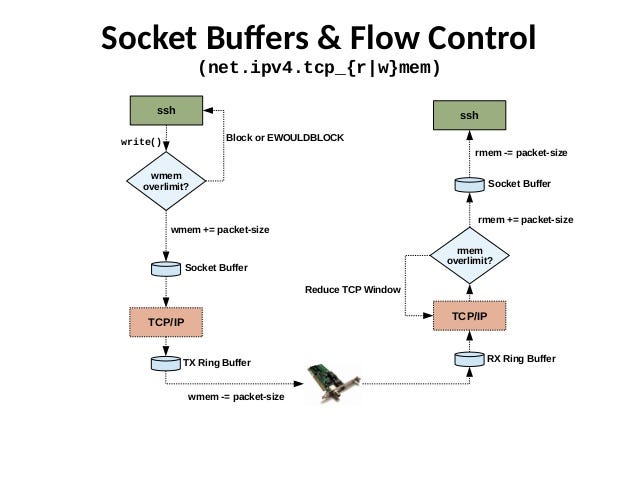
Размер этих двух буферов можно изменить, но мы не можем просто установить размер буфера на огромное число, так как это может привести к тому, что «сборка мусора» займет достаточно много времени, чтобы вызвать другие проблемы, такие как случайные всплески задержки.
Если при поступлении новых данных буфер полностью заполнен и сборщик мусора больше не может быть выполнен, новые данные будут отброшены.
Сворачивание
Когда буфер сокета ядра приближается к своему максимальному размеру, выполняется процедура, называемая сворачиванием, которая похожа на сборку мусора. Ядро пытается идентифицировать сегменты в буфере, которые имеют идентичные метаданные, и пытается объединить их, чтобы не иметь идентичных метаданных, заполняющих буфер. Размер буфера должен быть достаточно большим, чтобы не происходило слишком частое сворачивание, но достаточно маленьким, чтобы, когда это произойдет, он не блокировал другие операции надолго.
Обрезка
Когда коллапс больше не может происходить, начинается процесс «обрезки». Отсечение - это процесс отбрасывания новых пакетов, поскольку они не помещаются в буфер.
В Руководстве по настройке производительности Red Hat это описывается следующим образом:
Это своего рода хозяйственная деятельность, при которой ядро пытается освободить место в очереди приема, уменьшая накладные расходы. Однако эта операция требует затрат центрального процессора. Если при свертывании не удается освободить достаточно места для дополнительного трафика, данные «обрезаются», то есть данные удаляются из памяти и пакет теряется. Следовательно, лучше настроить это условие и избежать полного разрушения и сокращения буфера. Первый шаг - определить, происходит ли сворачивание и сокращение буфера.
Мониторинг сворачивания и обрезки
Файловая система / proc / дает очень много информации при устранении неполадок на машинах Linux. При исследовании сети можно использовать два удобных инструмента: netstat и ethtool. Чтобы проверить, действительно ли мы наблюдаем сворачивание / обрезку:
[root@host ~]# netstat -s | egrep "(collapse|prune)" 10051 packets pruned from receive queue because of socket buffer overrun 343734 packets collapsed in receive queue due to low socket buffer
Эти числа говорят вам, сколько пакетов было свернуто и сокращено с момента перезапуска системы или перезагрузки драйвера. Подождите немного и снова запустите команду. Если значения увеличиваются, что-то может работать не так, как задумано (свертывание - это нормально; обрезка нам не нравится).
Совет - настроить мониторинг этих номеров и отправлять его на панель управления.
Настройка того, как происходит сворачивание и обрезка
В некоторых случаях узким местом может быть размер буфера сокета. Обычно размера может хватить для вашего приложения, но внезапный всплеск трафика может ненадолго вызвать переполнение. С другой стороны, установка слишком высокого значения может привести к тому, что процедура свертывания займет слишком много времени для завершения, и вызовет таймаут для других частей оборудования.
Проверьте текущие размеры буферов чтения / записи:
[root@host ~]# sysctl -a | egrep "tcp_(r|w)mem" net.ipv4.tcp_rmem = 4096 1048576 4194304 net.ipv4.tcp_wmem = 4096 1048576 4194304
Эти числа говорят ядру выделить от 4 КиБ до 4 МБ для приемного буфера с начальным размером по умолчанию 1 МБ. Отличный подробный отчет от ребят из Cloudflare показывает, как они использовали такие инструменты, как stap, чтобы аналитически показать, как подобные изменения повлияли на ситуацию. Они завершили свое обсуждение этой конкретной обстановки следующими словами:
Поскольку размеры приемного буфера довольно велики, сборка мусора может занять много времени. Чтобы проверить это, мы уменьшили максимальный размер rmem до 2 МБ и повторили измерения задержки. […] Теперь эти цифры намного лучше. С измененными настройками tcp_collapse никогда не занимал больше 3 мс!
Вывод здесь состоит в том, чтобы не слепо копировать числа, которые работали для кого-то другого, а вместо этого сначала измерить вашу текущую ситуацию, чтобы иметь базовый уровень, и проверить любые изменения, которые вы вносите в соответствии с этим.
Отслеживание подключений
Каждое соединение «отслеживается» ядром даже после его завершения. Это может привести к тому, что отслеживаемая информация станет слишком большой для выделенной памяти, если сервер обрабатывает большой трафик. Однако размер этой таблицы можно изменить на лету. Чтобы проверить текущее значение, отметьте sysctl:
[root@host ~]# sysctl -a | egrep "netfilter.nf_conntrack_(max|cou)" net.netfilter.nf_conntrack_count = 46853 net.netfilter.nf_conntrack_max = 2097152
count показывает текущий размер, используемый в таблице отслеживания, а max показывает текущий установленный верхний предел. Если максимальное значение мало по сравнению с количеством, возможно, стоит его увеличить. Откройте /etc/sysctl.conf и добавьте эту строку (найдите подходящее значение для вашего варианта использования; удвоение текущего максимума может быть хорошей отправной точкой):
net.netfilter.nf_conntrack_max = 2097152
Если вы используете команду syctl для установки значения, оно не будет запомнено после перезапуска, поэтому добавьте его в файл конфигурации (/etc/sysctl.conf) .
Еще одна вещь, которую мы должны сделать при изменении максимального размера, - это изменить размер хеша. Размер хэша должен быть пропорционален максимальному значению и может быть рассчитан следующим образом:
hashsize = nf_conntrack_max / 8
Это нельзя установить в sysctl.conf, но вместо этого необходимо установить в файле конфигурации для модуля ядра nf_contrack:
echo 262144 > /sys/module/nf_conntrack/parameters/hashsize
И добавьте его в файл /etc/modprobe.conf, чтобы сделать его постоянным и не менять после перезагрузки:
options ip_conntrack hashsize=262144
Вывод
В следующей части мы рассмотрим прерывания, называемые SoftIRQ и HardIRQ, с помощью которых пакеты перемещаются из кольцевого буфера сетевого адаптера в буфер сокета ядра и из буфера сокета ядра в приложение, для которого они предназначены. Наконец, мы рассмотрим, как отслеживать и настраивать эти процессы.
Спасибо за чтение, не стесняйтесь комментировать и задавать вопросы!