Использование совместного встраивания текста и кода для поиска.

Вы когда-нибудь искали фрагмент кода в Google, потому что вам было лень писать его самостоятельно? Большинство из нас сделали! Тогда как насчет создания собственного инструмента поиска по коду с нуля? Это то, что мы постараемся сделать в этом проекте. Мы будем использовать параллельный набор вопросов StackOverflow и соответствующие образцы кода, чтобы построить систему, способную ранжировать существующие фрагменты кода с учетом того, насколько они «соответствуют» поисковому запросу, выраженному на естественном языке.
В конце блога есть ссылка на блокнот Colab, если вы хотите попробовать этот подход.
Описание системы:
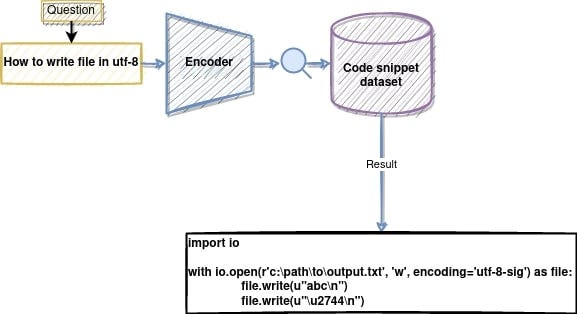
Мы пытаемся создать систему, способную принять вопрос, выраженный на естественном языке, а затем вернуть фрагмент кода, который лучше всего соответствует этому вопросу из набора сотен тысяч фрагментов кода Python.
Как это работает?
Система будет основана на обучающих вложениях для фрагментов кода и встраиваниях для вопросов «Как сделать». Часть поиска будет использовать Annoy, приблизительную реализацию ближайших соседей на Python/C++.
Данные:
Мы будем использовать набор данных StaQC, в котором есть пары (вопрос, фрагмент кода), добываемые автоматически из переполнения стека.
Образцы из набора данных выглядят так:
Вопрос: Как получить один случайный документ из миллиарда документов в MongoDB с помощью Python?
Код:
import random
collection = mongodb[""collection_name""]
rand = random.random() # rand will be a floating point between 0 to 1.
random_record = collection.find_one({ 'random' => { '$gte' => rand } })
Набор данных содержит 85 294 ответа с одним кодом и 60 083 ответа с несколькими кодами.
Предварительная обработка:
И код, и вопрос являются строками, поэтому нам нужно разбить их на токены, прежде чем вводить в модель. Поскольку мы работаем с кодом, мы не можем использовать обычные предварительно обученные токенизаторы и поэтому должны создавать свои собственные.
Во-первых, нам нужно, чтобы наш токенизатор разбивал специальные символы, такие как «_» или «=», и правильно разбивал имена переменных camelCase.
Делаем это в два этапа:
- Добавьте пробел вокруг специальных символов и добавьте пробел вокруг слов в camelCase.
- Обучите токенизатор обнимающего лица с предварительной токенизацией пробелов.
Это дает следующий результат:
Вопрос -›
Как получить случайный один документ из 1 миллиарда документов в MongoDB с помощью python?
Токенизированный вопрос -›
['[CLS]', 'как', 'к', 'получить', 'а', 'случайный', 'одиночный', 'документ', 'от', '1', 'счет', '## ion», «документы», «в», «mongo», «db», «использование», «python», «?», «[SEP]»]
Фрагмент кода -›
class MyLabel(Label): pass
class AwesomeApp(App):
def build(self):
return MyLabel()
Токенизированный код -›
['[CLS]', 'класс', 'мой', 'метка', '(', 'метка', ')', ':', 'проход', 'класс', 'круто', 'приложение' , '(', 'приложение', ')', ':', 'def', 'сборка', '(', 'я', ')', ':', 'возврат', 'мой', ' метка', '(', ')', '[SEP]']
МЛ часть:

В этой части мы обучим модель, способную сопоставлять строку (фрагмент кода или вопрос) с вектором фиксированной размерности размером 256. Ограничение, которое мы будем применять к этому выходному вектору, заключается в том, что мы хотим сходства между вектором вопроса и вектором соответствующего ему фрагмента кода должно быть высоким, а во всех остальных случаях иметь низкое сходство.
Мы используем билинейную меру подобия:
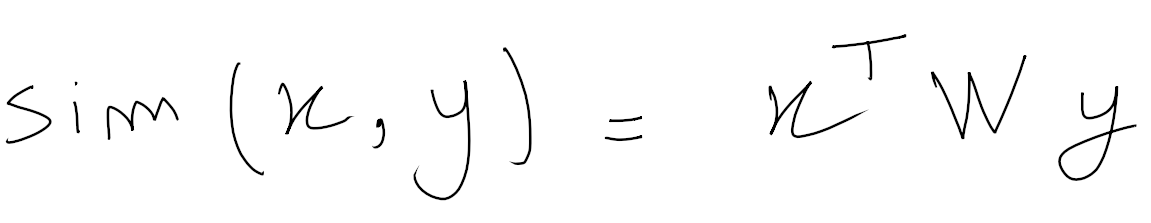
Где W — обучаемый параметр. Подробности см. в разделе Контрастное изучение аудиопредставлений общего назначения.
Чтобы изучить полезные встраивания, нам нужны положительные примеры, которые представляют собой пары вопросов «Как сделать» и соответствующие им фрагменты кода. Нам также нужен отрицательный пример, которым будут все остальные векторы в пакете. Это означает, что представления положительной пары будут переведены на более высокий показатель сходства, в то время как сходство между вектором выборки и всеми несвязанными векторами в пакете будет снижено.

Мы хотим, чтобы матрица партии была как можно ближе к идентичности.
Этот способ проведения сопоставительного обучения взят из статьи, упомянутой выше. Это позволяет в некотором роде получать отрицательные примеры «бесплатно», так как они уже вычисляются как часть пакета. Он также имеет большое преимущество по сравнению с другими подходами, такими как потеря триплетов, в том, что вместо того, чтобы иметь только один отрицательный пример для каждого положительного, мы можем получить отрицательные примеры batch_size -1, что заставляет кодировщик изучать более дискриминационные вложения.
Весь смысл сопоставления ввода текста с фиксированными тусклыми векторами заключается в том, что это делает часть поиска намного более эффективной за счет использования приблизительных алгоритмов ближайших соседей.
Поисковая часть:
Когда у нас есть все фрагменты кода, закодированные в векторы, и модель для кодирования нового вопроса таким же образом, мы можем начать работать над поисковой частью системы. Мы будем использовать библиотеку под названием Annoy.
Использование Annoy позволит нам запросить набор данных из n фрагментов кода за время O(log(n)).
# We define the Annoy Index
t = AnnoyIndex(len(samples[0]["vector"]), "angular")
# We add all the vectors to the index
for i, sample in enumerate(samples):
t.add_item(i, sample["vector"])
# We then build the trees for the approximate search
t.build(100)
# We can use it to query the NN of a question vector
indexes = t.get_nns_by_vector(search_vector, n=3, search_k=-1)
Пример результатов для поисковых запросов:
Как экранировать специальные символы HTML?
# Search Result 1 -->
raw_html2 = raw_html.replace('\\n', '')
# Search Result 2 -->
def escape(htmlstring):
escapes = {'\"': '"',
'\'': ''',
'<': '<',
'>': '>'}
# This is done first to prevent escaping other escapes.
htmlstring = htmlstring.replace('&', '&')
for seq, esc in escapes.iteritems():
htmlstring = htmlstring.replace(seq, esc)
return htmlstring
# Search Result 3 -->
mytext.replace(r"\r\n", r"\n")
# Query encoded in 0.010133743286132812 seconds
# Search results found in in 0.00034046173095703125 seconds
Как сделать список уникальным?
# Search Result 1 -->
seen = set()
L = []
if 'some_item' not in seen:
L.append('some_item')
seen.add('some_item')
# Search Result 2 -->
def is_duplicate(a,b):
if a['name'] == b['name'] and a['cost'] == b['cost'] and abs(int(a['cost']-b['cost'])) < 2:
return True
return False
newlist = []
for a in oldlist:
isdupe = False
for b in newlist:
if is_duplicate(a,b):
isdupe = True
break
if not isdupe:
newlist.append(a)
# Search Result 3 -->
>>> L = [2, 1, 4, 3, 5, 1, 2, 1, 1, 6, 5]
>>> S = set()
>>> M = []
>>> for e in L:
... if e in S:
... continue
... S.add(e)
... M.append(e)
...
>>> M
[2, 1, 4, 3, 5, 6]
M = list(set(L))
# Query encoded in 0.006329536437988281 seconds
# Search results found in in 0.0003654956817626953 seconds
Мы видим, что эта система может за несколько миллисекунд найти соответствующие фрагменты кода среди 145 тысяч возможных ответов.
Заключение
В этом небольшом проекте мы обучили модель-трансформер прогнозировать встраивание как текста, так и кода. Затем эти встраивания использовались для построения поискового индекса KNN с использованием приблизительного ближайшего соседа в Annoy.
Этот подход можно еще улучшить, используя еще больший набор данных вопросов/кодов или сравнив различные стратегии обучения.
Вы можете запускать свои собственные запросы, клонируя репо:
Или запустив этот блокнот colab:
Использованная литература: