В первом посте этой серии мы кратко рассказали о машинном обучении, подходе Revoke-Obfuscation для обнаружения запутанных сценариев PowerShell и моих усилиях по улучшению набора данных и моделей для обнаружения запутанного PowerShell. В итоге мы получили три модели: регуляризованную логистическую регрессию L2 (Ridge), классификатор LightGBM и архитектуру нейронной сети.
Во втором посте рассказывалось об атаке на эти модели с точки зрения белого ящика, т. е. когда у нас есть вся обученная модель, включая входные функции, архитектуру модели, параметры/веса модели и обучающие данные. . Я настоятельно рекомендую, по крайней мере, просмотреть эти первые два сообщения, прежде чем продолжить, чтобы убедиться, что все это имеет как можно больше смысла.
В этом посте мы рассмотрим более распространенную и сложную точку зрения черный ящик. Здесь мы знаем только, какие фичи извлекаются из каждого образца — даже архитектура останется для нас непрозрачной.

Фон
Прочитав сотни страниц академических исследований по состязательному машинному обучению, я могу с уверенностью сказать, что значительная часть исследований была проведена с точки зрения белого ящика. Помните наше определение атак белого и черного ящиков из второго поста этой серии:
- Атака белого ящика – это атака, при которой мы знаем все о развернутой модели, например, входные данные, архитектуру модели и определенные внутренние компоненты модели, такие как веса или коэффициенты.
- Атака черного ящика – это атака, при которой мы знаем только входные данные модели и имеем оракула, к которому можем запросить выходные метки или оценки достоверности. «Оракул» — это широко используемый термин в этом пространстве, который просто означает, что у нас есть какая-то непрозрачная конечная точка, на которую мы отправляем наши входные данные, а затем возвращает выходные данные модели.
Кроме того, большая часть исследований, похоже, была посвящена распознаванию изображений. Хотя это интересно, это определенно другая проблемная область, чем та, с которой мы имеем дело. В частности, изображения могут иметь несколько пикселей, искаженных на небольшую величину, при этом результирующее состязательное изображение не будет выглядеть измененным для человеческого глаза. Для многих проблем, с которыми мы сталкиваемся в области безопасности, например, для нашего пространства проблем запутывания PowerShell, мы более ограничены в а) количестве функций, которые мы можем изменить, и б) в какой степени мы можем изменить указанные функции. То есть у нас есть меньшее функциональное подпространство модификаций, которые мы можем внести в сценарии PowerShell, в отличие от изображений.
Ряд атак методом черного ящика включает в себя извлечение модели(см. следующий раздел) для создания локальной модели, иногда называемой замещающей или суррогатной моделью. Затем существующие атаки выполняются против локальной модели для создания враждебных образцов в надежде, что эти образцы также обойдут целевую модель. Это часто работает благодаря феномену переносимости атаки, о котором мы вскоре поговорим.
Атаки методом черного ящика также могут пропустить извлечение модели и непосредственно запрашивать входные данные для целевой модели. Эти атаки, при которых внутренняя конфигурация модели вообще не требуется, в академической литературе известны как атаки черного ящика. Однако, используя извлечение модели, мы потенциально можем применять атаки белого ящика против локальных клонов моделей черного ящика, где у нас есть только оракул для отправки входных данных и получения меток.
Извлечение модели
Извлечение модели, по словам Уилла Пирса и других, является одним из самых фундаментальных примитивов в состязательном ML. Хотя эта идея, вероятно, витала в воздухе некоторое время, я полагаю, что первой формализацией извлечения модели (или, по крайней мере, той, которая популяризировала этот метод) была статья 2016 года Переносимость в машинном обучении: от феноменов. к атакам черного ящика с использованием состязательных образцов»» и статье 2017 года Практические атаки черного ящика против машинного обучения» от Papernot et al. Общее резюме их подхода из статьи 2017 года таково:
Наша стратегия атаки состоит в обучении локальной модели для замены целевой DNN [глубокой нейронной сети], используя входные данные, синтетически сгенерированные противником и помеченные целевой DNN. Мы используем локальную замену для создания враждебных примеров и обнаруживаем, что они неправильно классифицируются целевой DNN.
Вся идея состоит в том, чтобы аппроксимировать границу решения целевой модели с меньшим количеством (и обычно других) данных, чем модель была первоначально обучена. По сути, извлечение модели включает в себя сначала отправку ряда известных помеченных образцов в модель, которая функционирует как оракул маркировки. Представьте, что вы отправляете кучу двоичных файлов на какой-то веб-сайт, который позволяет узнать, являются ли двоичные файлы вредоносными или нет. Или представьте, что наши адаптированные модели Revoke-Obfuscation являются своего рода внутренним API, куда мы можем отправить наши измерения функций и получить результат метки нормальный или obfuscated, или показатель вероятности обфускации. Имея достаточно входных данных, мы можем обучить локальную замещающую модель, которая работает аналогично целевой модели.
Рисунок 1 из статьи Активные атаки глубокого обучения при строгих ограничениях скорости для онлайн-вызовов API» Shi et al. хорошо описывает процесс:
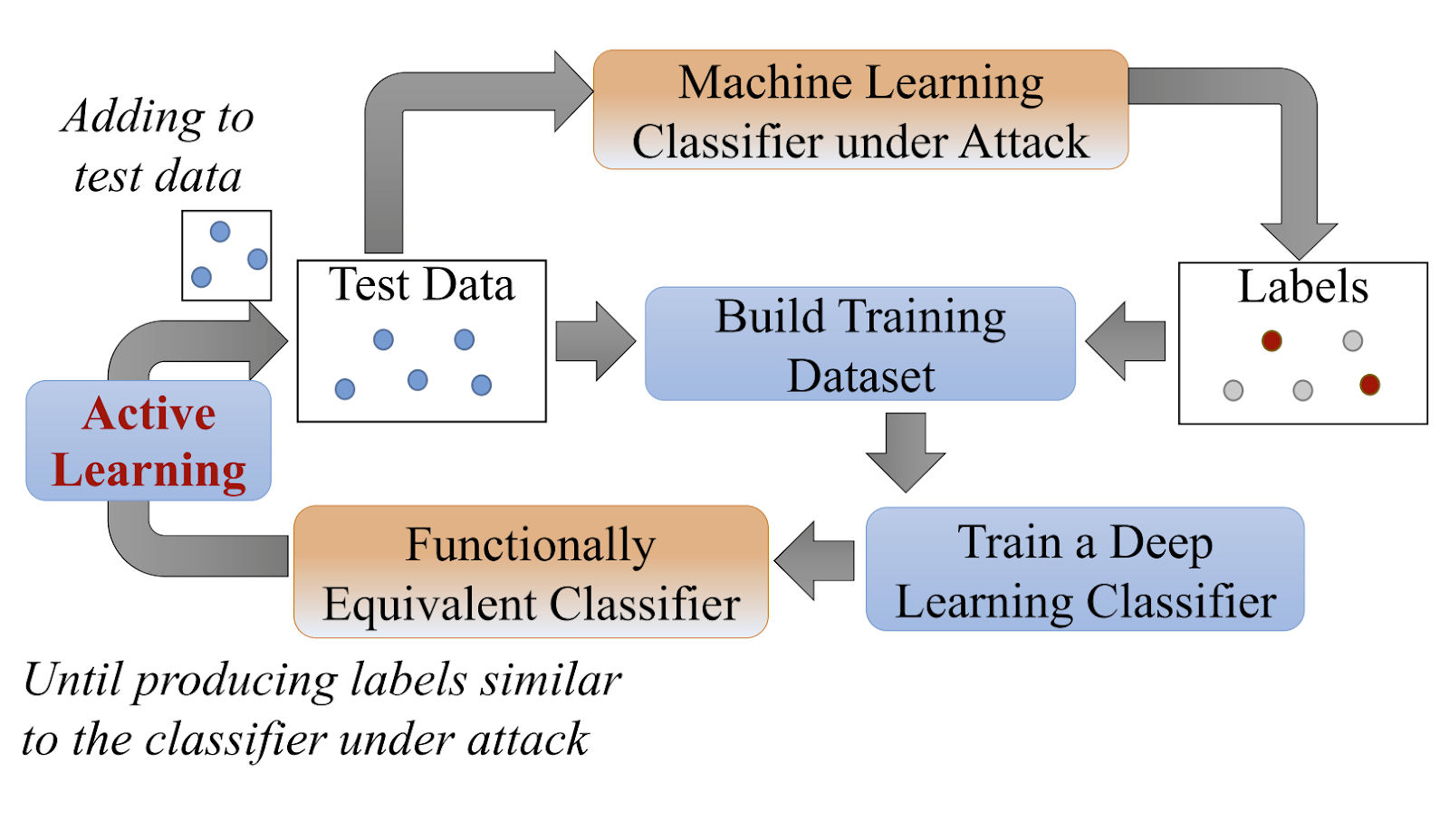
Разумная гипотеза состоит в том, что чем ближе мы сможем соответствовать исходной архитектуре модели, тем лучше будет функционировать наша локальная модель. Это то, что мы будем исследовать в этом посте.
Несколько иной подход включает в себя обучение изначально плохой модели с несколькими образцами и использование некоторых методов атаки белого ящика, описанных во втором посте, для создания враждебных образцов. Эти образцы прогоняются через классификатор, и как описано этим постом:
… состязательные примеры — это шаг в направлении градиента модели, чтобы определить, будет ли модель черного ящика классифицировать новые точки данных так же, как замещающая модель. Дополненные данные помечаются моделью черного ящика и используются для обучения лучшей заменяющей модели. Как и ребенок, модель-заменитель получает более точное представление о том, где находится граница принятия решений модели черного ящика.
Конечный результат в любом случае? У нас есть локально обученная модель, которая приближается к границе решения целевой модели. Благодаря этому мы можем выполнять различные алгоритмы атак на основе белого ящика, которые используют градиенты внутренней модели, в дополнение к любым атакам черного ящика.
Примечание: входные данные и архитектура моделей
Если входными данными для модели, которую вы атакуете, являются изображения или текст, в некотором смысле вам повезло, поскольку вы, вероятно, можете угадать базовую архитектуру целевой модели. Существуют установленные рекомендации для этих типов входных данных, т. е. сверточных нейронных сетей для изображений и LSTM/преобразователей (или наивного байесовского метода в определенных случаях) для текста. В этих примерах мы будем работать с табличными данными, то есть данными, отображаемыми в столбцах или таблицах. Мы надеемся вернуться к атакующим текстовым моделям в другой раз!
Переносимость атаки
Вы можете спросить: Правда? Могут ли атаки на дерьмовые локально клонированные модели сработать против реальных производственных моделей? Ответ — ДА, из-за феномена, называемого переносимостью атаки. Документ 2019 года Почему состязательные атаки передаются? Объясняя переносимость атак уклонения и отравления» Демонтиса и соавт. исследует это с академической точки зрения, но я сделаю все возможное, чтобы объяснить эту концепцию. Кроме того, учитывая, что этой статье всего несколько лет, и нет единого мнения относительно того, почему состязательные атаки переносятся, помните, что этот вопрос все еще остается открытым.
Основополагающей работой, которая представила эту концепцию, является ранее упомянутая статья 2016 года Переносимость в машинном обучении: от явлений к атакам черного ящика с использованием состязательных образцов» Пейпернота, Макдэниела и Гудфеллоу. Первые несколько предложений из аннотации дают хороший обзор концепции (выделено мной):
Многие модели машинного обучения уязвимы для враждебных примеров: входные данные, специально созданные для того, чтобы модель машинного обучения выдавала неправильный результат. Враждебные примеры, влияющие на одну модель, часто влияют на другую модель, даже если две модели имеют разную архитектуру или были обучены на разных обучающих наборах, при условии, что обе модели были обучены выполнять одну и ту же задачу. Поэтому злоумышленник может обучить свою собственную модель заменителя, создать враждебные примеры против заменителя и перенести их в модель жертвы, имея очень мало информации о жертве.
В их статье ставится задача доказать две гипотезы, а именно, что переносимость выборок как внутри, так и между методами — постоянно сильные явления во всем пространстве методов машинного обучения и что черный -box-атаки возможны в практических условиях против любого неизвестного классификатора машинного обучения. В их статье приведены убедительные доводы в пользу каждого, а также демонстрируется переносимость различных классов моделей, резюмированная на рисунке 3 на странице 5 документа. »:
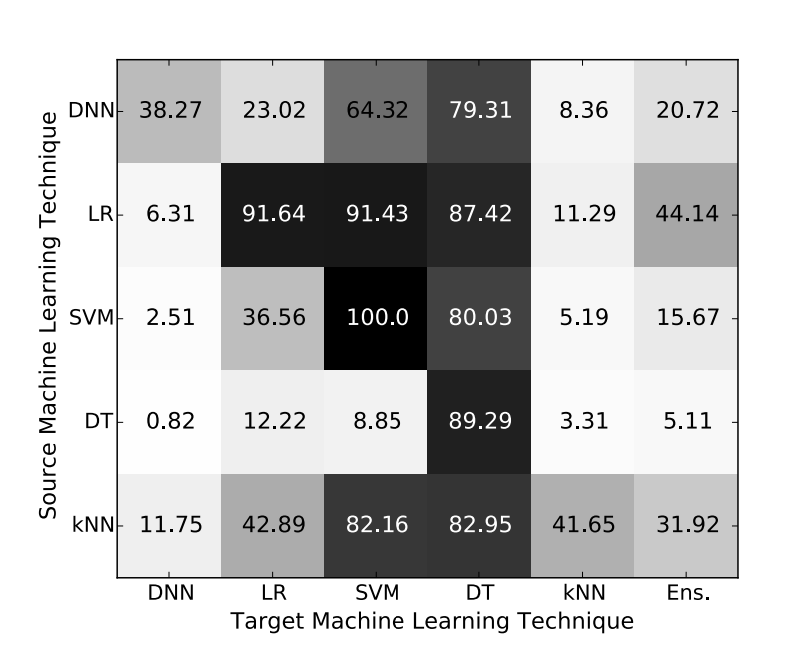
Значения в каждой ячейке представляют собой процент выборок (здесь — образы MNIST, де-факто тестовый пример для состязательных атак), созданных для обхода определенной архитектуры модели, которые при применении к другой архитектуре модели также изменили свою классификационную метку. То есть процент успешных локально созданных враждебных образцов, которые также обманывают целевую модель. Обратите внимание, что этот рисунок не включает ансамбли Random Forest или Boosted Decision Tree (столбец Ens представляет собой пользовательский ансамбль из 5 существующих методов). Тип замещающей модели указан слева, а тип модели цель находится внизу. Мы можем увидеть некоторые закономерности:
- В общем, чем ближе вы соответствуете архитектуре, тем лучше будет уклонение.
- Модели логистической регрессии (LR) хорошо заменяют другие модели логистической регрессии, машины опорных векторов (SVM) и деревья решений.
- Деревья принятия решений являются наиболее уязвимыми для атак, причем атаки любой архитектуры хорошо переносятся.
- Наиболее устойчивой архитектурой является глубокая нейронная сеть (DNN).
Исходя из этого, моя теория заключается в том, что если вы можете в целом соответствовать архитектуре целевой модели, у вас больше шансов, что ваши атаки на замену будут перенесены.
Как это будет соответствовать нашим примерам наборов данных?
Атака на черный ящик
Наша цель здесь — воссоздать локальную замещающую модель, имея доступ только к модели как к оракулу маркировки (т. е. к обученным целевым моделям из первого поста). Затем выполним атаки белого ящика со второго поста против нашего заместителя, надеясь на достаточную переносимость атаки. Хотя это очень похоже на процессы в первых двух сообщениях, у нас есть пара дополнительных шагов.
Во-первых, нам нужен новый набор данных для извлечения модели. Я выбрал 1500 случайных файлов из PowerShellCorpus и прогнал каждый через случайный набор обфускаций из Invoke-Obfuscation, что дало мне всего 3000 образцов. Затем я запустил код извлечения признаков для каждого скрипта и сгенерировал файл BlackBox.ast.csv, который теперь обновляется в ./datasets/ в репозитории Invoke-Evasion.
Следующим шагом является извлечение модели, когда мы обучаем суррогатную локальную модель на наборе данных, помеченном целевой моделью. Для этого я использовал каждую целевую модель для создания соответствующего набора меток для нового набора данных. Хотя эти ярлыки не являются точной истиной, поскольку ни одна из наших моделей не была идеальной, ярлыки отражают границы решений самой целевой модели. Я разделил набор данных на стандартный поезд/тест с соотношением 80/20, как мы сделали в первом посте.

В предыдущем разделе я упомянул, что чем лучше вы сопоставите свою локальную модель с архитектурой целевой модели, тем выше вероятность того, что созданная вами атака обманет цель. Я хотел посмотреть, какие шаги «разведки модели» могут помочь пролить свет на архитектуру целевой модели. На мой взгляд, большой вопрос заключается в том, чтобы определить, является ли цель линейной, древовидной, нейронной сетью или каким-то третьим вариантом. Алгоритмы на основе деревьев часто очень хорошо работают практически с любым набором данных, поэтому моя гипотеза состоит в том, что случайные леса и деревья с усилением градиента будут хорошо сочетаться с каждым набором данных целевой модели. Из-за этого мы в идеале хотим сначала определить, является ли модель нейронной сетью или линейной, с древовидным результатом процесса исключения.
Это, безусловно, открытый вопрос, и я не думаю, что он широко обсуждался в академических кругах. Тем не менее, я хочу еще раз повторить, что я не являюсь экспертом в этой области - если есть работа в этой области (или у кого-то есть дополнительные идеи), пожалуйста, дайте мне знать!
Две мои основные идеи, которые я подробно изложу в ближайшее время:
- Обучение нескольких замещающих моделей для каждого целевого помеченного набора данных, генерация состязательных выборок с использованием атаки HopSkipJump из Adversarial Robustness Toolbox. Я подробно расскажу об этом в следующем разделе, но пока знайте, что это способ генерировать состязательные выборки для любой модели черного ящика.
- Тестирование серьезной модификации одной важной функции по отношению к цели, чтобы увидеть, может ли модель быть линейной.
Я начал с подгонки следующих моделей к каждому целевому набору данных, выполнив базовый случайный поиск с перекрестной проверкой (используя RandomizedSearchCV) для общих гиперпараметров для неглубоких алгоритмов (т. е. всего, кроме нейронной сети):
- Логистическая регрессия
- Классификатор опорных векторов с ядром радиальной базисной функции (rbf)
- Гауссовский наивный байесовский метод
- Случайный лес
- Повышенные деревья (XGBoost)
- Однослойная нейронная сеть с отсевом (базовая архитектура, без настройки гиперпараметров)
Затем я использовал HopSkipJump для создания состязательных образцов для каждой модели. По какой-то причине я не смог заставить нейронную сеть правильно генерировать достаточное количество образцов с помощью HopSkipJump, поэтому вместо этого я использовал атаку Fast Gradient Method (FGM). Зачем выбирать именно эти архитектуры в качестве локальных моделей? Я хотел выбрать ряд вещей, которые фактически используются в производстве, и хотел охватить линейную (логистическая регрессия), ансамбли деревьев (случайные леса/ускоренные деревья) и нейронные сети.

Эти враждебные выборки были сопоставлены с каждой локальной моделью и целевой моделью, чтобы получить сопоставимую точность. Однако, что более важно, я вытащил конкретные образцы, неправильно классифицированные каждой локальной моделью. Эти образцы были сопоставлены с целевой моделью, что дало процент враждебных образцов, созданных для локальной модели, которые также обманули целевую модель. Это переносимость идея, о которой мы говорили ранее. Хотя общая эффективность всех локальных враждебных выборок против целевой является интересным моментом данных, нас действительно волнует, насколько эффективна локальная суррогатная модель при создании враждебных выборок, которые обманывают целевую модель.
Затем я взял наиболее эффективную модель логистической регрессии, которая является линейной, и сильно изменил один коэффициент для выборки, чтобы увидеть, повлияло ли это на выходные данные модели. Цель здесь состояла в том, чтобы увидеть, является ли модель потенциально линейной для другой точки отсчета.
Целевая модель 1 (логистическая регрессия)
Вот результат нашего процесса поиска возможности уклонения от передачи по первой модели:

Эти результаты интересны. Моделью, которая наиболее точно соответствовала размеченным данным целевой модели, был случайный лес, суррогат логистической регрессии (который наиболее точно соответствовал архитектуре целевой модели) имел наибольшее количество враждебных выборок, переданных в целевую модель, но XGBoost имел самый высокий процент состязательные выборки, переданные в цель логистической регрессии.
Целевая модель 2 (LightGBM)
Вот результат нашего процесса поиска возможности уклонения от передачи по второй модели:

Эти результаты также интересны. Модели, которые наиболее точно соответствовали помеченным данным целевой модели, были Random Forest и XGBoost, в то время как у нейронной сети было как наибольшее количество переданных состязательных атак, так и лучший процент переносимости атак на цель LightGBM. По сравнению с двумя другими целевыми моделями Модель 2 также кажется наиболее устойчивой к враждебным образцам.
Целевая модель3 (4-х слойная нейронная сеть)
Вот результат нашего процесса поиска возможности уклонения от передачи по первой модели:

Эти результаты столь же интересны, как и два предыдущих. Большинство моделей были чрезвычайно близки по точности к размеченным данным целевой модели, в то время как логистическая регрессия и XGBoost имели наибольшее количество враждебных выборок, переданных в целевую нейронную сеть. У нейронной сети был лучший процент переносимости атак, но второе худшее количество переданных атак.
Основываясь на результатах, моя стратегия определения архитектуры модели путем измерения возможности переноса атаки на суррогатную модель в данном случае работает не слишком хорошо. В качестве подтверждения для каждой модели я взял наиболее перспективный суррогат для каждой цели и провел те же атаки, что и мы, против моделей белого ящика во втором посте. В итоге это оказалось не так эффективно, и я получил большое количество модификаций для каждого скрипта. В частности, модифицированные сценарии будут иметь очень низкую вероятность запутывания по сравнению с локальным суррогатом, но все равно будут классифицироваться как запутанные целью.
Я ломал голову над объяснением этого, и Уилл смог помочь мне пролить свет на несколько вещей. Это привело к двум основным изменениям в моем подходе: навешиванию ярлыков и переворачиванию моей точки зрения на всю проблему с ног на голову.
Атака на черный ящик, дубль 2 — Soft Labels
Уилл подробно описывает влияние жестких и мягких меток на извлечение модели на слайде 21 из своей презентации BlackHat EU 2021:

Интуитивно это имеет смысл. Жесткая метка, такая как нормальная или запутанная, предоставляет меньше информации, чем набор вероятностей, например запутанная=0,73. Чем больше информации у нас есть, тем лучше мы можем сопоставить внутреннюю часть модели — между жесткими двоичными метками, такими как 0 и 1, есть много пробелов!
Давайте рассмотрим ситуацию, когда наши волшебные API-интерфейсы Invoke-Obfuscation дают вероятность запутывания, равную 0,73, а не просто двоичную метку 0/1. Как мы можем воспользоваться этой дополнительной информацией? Вспомните первый пост, где мы говорили о классификации и регрессии: классификация дает нам ярлыки, а регрессия дает нам число!
Давайте посмотрим, что произойдет, если мы пометим наш враждебный набор данных вероятность того, что скрипт запутан, а не просто жесткой меткой нормальный/запутанный. Мы сохраним пороговое значение 0,5 или выше, что означает, что образец запутан, но его можно отрегулировать (часто для изменения баланса ложноположительных и ложноотрицательных результатов).
Поскольку мы занимаемся регрессией вместо классификации, нам нужен немного другой набор алгоритмов. Нейронные сети, случайные леса, деревья с градиентным усилением и машины опорных векторов имеют регрессионные эквиваленты. Однако вместо логистической регрессии (я знаю, что это сбивающее с толку название классификатора) мы собираемся использовать классическую линейную регрессию, лассо-регрессию (L1), гребенчатую регрессию (L2) и байесовскую гребенчатую регрессию вместо байесовской наивной байесовской. Затем для каждого из них мы проверим среднеквадратичную ошибку (RMSE) в тестовом наборе, общую метрику регрессии, которая возводит в квадрат разницу между каждым прогнозом и его фактическим значением, суммирует все квадраты и извлекает квадратный корень. всего:

Мы также возьмем каждую регрессионную модель, сделаем прогноз для каждой выборки и снова превратим их в жесткие метки, увидев, какие из них равны 0,5 или выше. Это позволит нам получить точность измерения. Все это похоже на подход типа классификатор-аппроксимация-регрессоров. Подробности в блокноте BlackBox.ipynb в репозитории Invoke-Evasion.

Одна проблема, с которой я столкнулся, заключается в том, что, поскольку мы строим модели регрессии вместо моделей классификации, мы не можем использовать их из коробки с HopSkipJump или другими алгоритмами атаки. Я предпринял несколько попыток создать собственную классификационную модель, обернувшую регрессионный режим scikit-learn, но ART по-прежнему не работал с ними должным образом. Я уверен, что есть способ сделать это, но есть еще одна серьезная проблема, которую мы еще не рассмотрели…
Атака на черный ящик Дубль 3 — реальная проблема
Большая проблема, с которой я столкнулся, пытаясь понять ситуацию с противоборствующим машинным обучением, заключается в том, как превратить модифицированный враждебный числовой набор данных обратно в рабочий скрипт. Как я уже упоминал в этой серии постов, большинство научных исследований в области состязательного машинного обучения касались данных изображений. Возмущение состязательных признаков для изображений довольно просто или, скорее, не ограничено — мы просто настраиваем биты для пикселей, а затем отправляем изображение в наш целевой классификатор. Практически все алгоритмы уклонения от состязательного машинного обучения используются таким образом. Вы предоставляете массив выборок данных и алгоритм атаки, и создаются возмущенные/состязательные выборки, то есть массивы чисел, которые обманывают целевую модель при обработке.
Мы исследовали возможность маскировки признаков различных алгоритмов атаки во втором посте об атаках на модели белого ящика. Несмотря на то, что мы ограничили модификации меньшим подмножеством более легко модифицируемых функций, это все еще не идеально. Если у нас есть набор функций, измененных из исходного образца, как нам а) превратить его обратно в скрипт, который б) вообще работает и в) по-прежнему выполняет предполагаемую функциональность скрипта?
Как мы говорили во втором посте, что такое ??? процесс на следующем рисунке:
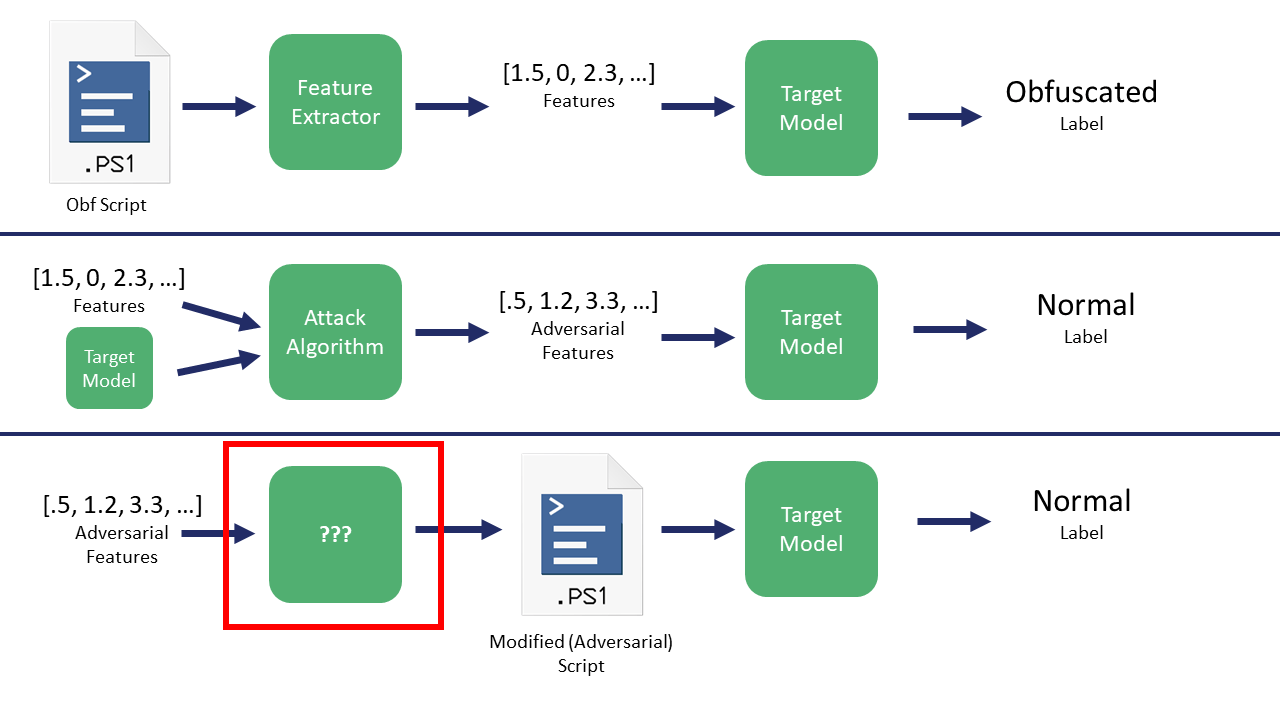
Мне было трудно обдумать это, пока я не прочитал некоторые исходники для ветки mlsecevasion Counterfit и не поговорил с Уиллом, который полностью изменил мою точку зрения. Он поделился ключевой мыслью от Хайрама Андерсона (и кое-что, изученное авторами предыдущего исследования уклонения на основе PE-вредоносного ПО): на самом деле это всего лишь проблема оптимизации!
Алгоритмы атаки «черный ящик» оптимизируют измеренные входные характеристики для противоборствующей задачи «максимум-минимум», о которой мы говорили во втором посте, где мы хотим максимизироватьфункцию ошибки/потери модели для выборки, но минимизируйтеколичество изменений для этого. Вместо того, чтобы оптимизировать модификацию векторизованных объектов напрямую, почему бы нам не оптимизировать ряд последовательных действий, которые влияют на эти объекты?

По сути, мы хотим сначала перечислить ряд действий по модификации, которые мы можем выполнить с конкретным образцом, которые изменяют функции, извлеченные для указанного образца. Например, Counterfit имеет набор добавлений/наложений раздела PE, импорта для добавления и временных меток для попытки для PE. В нашей ситуации нам нужно что-то, что добавляет нормальные функции, и мы можем использовать подходы объяснимости из второго поста, чтобы управлять этим процессом. Затем мы можем использовать такой алгоритм, как HopSkipJump, чтобы найти комбинацию этих функций, которая дает желаемый результат.
Вместо этого наш подход будет выглядеть так:
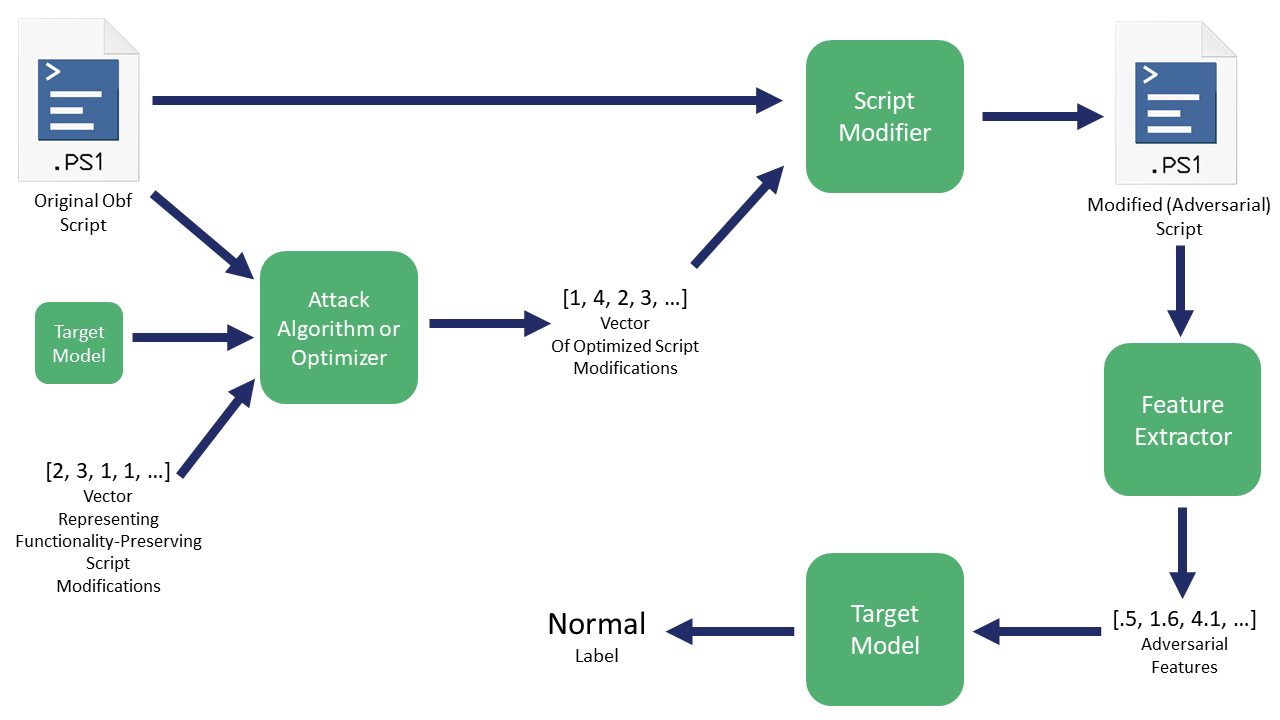
В случае с Counterfit они берут вектор, представляющий модификации для выполнения, и передают его во что-то вроде HopSkipJump. Для некоторых будущих работ я надеюсь создать модуль Counterfit для обфускации PowerShell, но пока мы будем работать вручную.
Существует еще одна альтернатива использованию алгоритмов атаки, байесовская оптимизация, «стратегия последовательного проектирования для глобальной оптимизации функций черного ящика.» Помните, в первом посте мы кратко говорили об Оптуне, фреймворк, созданный для настройки гиперпараметров алгоритмов машинного обучения. Optuna реализует различные байесовские методы оптимизации и является очень гибким, с общим подходом:
- Определите целевую функцию. Эта функция имеет пространство для поиска комбинаций параметров, которые вы ищете, и возвращает одно или несколько объективных значений, которые необходимо минимизировать или максимизировать.
- Проведите ряд испытаний в рамках исследования, где вы ограничиваете количество испытаний или общее время проведения исследования.
- Пусть математика сделает все остальное, создав оптимизированный набор параметров для нашей функции!
Другой ключевой вывод здесь заключается в том, что нам не нужно использовать Optuna только для настройки гиперпараметров! Целевая функция представляет собой черный ящик, а мы можем использовать его для выполнения ряда действий модификации для выполнения нашего целевого скрипта и возврата оценки вероятности обфускации из нашей целевой модели. Это также подход, который реализовал Counterfit, используя фреймворк Hyperopt вместо Optuna.
Если это звучит как обучение с подкреплением, вы не совсем ошибаетесь. Не будучи настолько грамотным в соответствующей математике, как хотелось бы, я заявлю, что считаю, что этот подход похож на обучение с подкреплением в принципе, но отличается на практике. Я чувствую, что этот подход, вероятно, будет работать для небольших наборов атомарных изменений, которые не так сильно зависят от порядка — большее количество последовательных действий, которые очень зависят от контекста, вероятно, будут работать лучше при правильном подходе к обучению с подкреплением. Однако, поскольку у нас есть короткий цикл обратной связи выберите преобразования-обфускация скрипта-измерьте обфускацию, нам, вероятно, не нужны дополнительные накладные расходы полного подхода к обучению с подкреплением.
Оптимизация уклонения от обфускации с помощью нашего черного ящика
Здесь мы собираемся собрать все вместе, объединив подход классификатор-аппроксимация-регрессоров с байесовской оптимизацией модификаций скрипта.
Наша общая цель:взять запутанный входной скрипт DBOdemo1.ps1 и вернуть измененный скрипт, который сохраняет функциональность исходного скрипта, но помечается как обычный нашей настроенной моделью нейронной сети. . Мы также хотим добавить в сценарий как можно меньше символов.

Наш полный подход от начала до конца будет следующим:
- Создайте разумное количество запутанных и нормальных выборок (положительные и отрицательные классы) и извлеките векторизованные функции из каждой выборки. В нашем случае это 446 самых важных признаков, отобранных через Борта-Шап в первом посте.
- Запустите функции для векторизованных выборок через целевую модель, которая возвращает вероятность запутывания. Это создает набор данных, помеченный целевой моделью «оракула».
- Обучите несколько моделей локальной регрессии, чтобы они максимально точно соответствовали вероятностным показателям обучающего набора данных, измеряя конечную производительность по сравнению с проверочным набором. Этот и последний этап составляют часть Извлечение модели в цепочке атаки.
- Извлеките важность функций из наиболее эффективной модели, чтобы предоставить нам наиболее эффективные функции.
- Исследуйте объекты, среднее значение которых выше для обычных выборок, чем для запутанных выборок. Это связано с тем, что мы хотим добавить нормальный код к существующему запутанному образцу.
- Используя эту информацию о большинстве обычных функций, вручную создайте несколько преобразований сценария, которые добавляют дополнительные нормальные данные сценария в начало обфусцированного сценария. Мы хотим, чтобы эти функции преобразования включали информацию о важности функций, но также сохраняли исходную функциональность кода. По сути, мы хотим, чтобы этот код был похож на скриптовые NOP, но больше всего влиял на модель в направлении нормального.
- Создайте целевую функцию, которая принимает входной скрипт и применяет ряд преобразований скрипта, возвращая количество добавленных символов и показатель вероятности обфускации из целевой модели вместо локальной суррогатная модель.
- Запустите исследование оптимизатора Optuna, которое минимизирует оба значения, возвращаемые целевой функцией для многокритериальной оптимизации.
Основная идея здесь заключается в том, что мы извлекаем целевую модель настолько эффективно, насколько это возможно, и используем информацию белого ящика из этой локальной суррогатной модели для управления созданием функций, которые изменяют запутанный целевой сценарий. Затем мы оптимизируем использование этих функций модификации по отношению к целевой модели черного ящика. Такой подход позволяет минимизировать время и количество запросов к API черного ящика.
Результаты нашего исследования оптимизации, длившегося 30 минут, выглядят следующим образом:
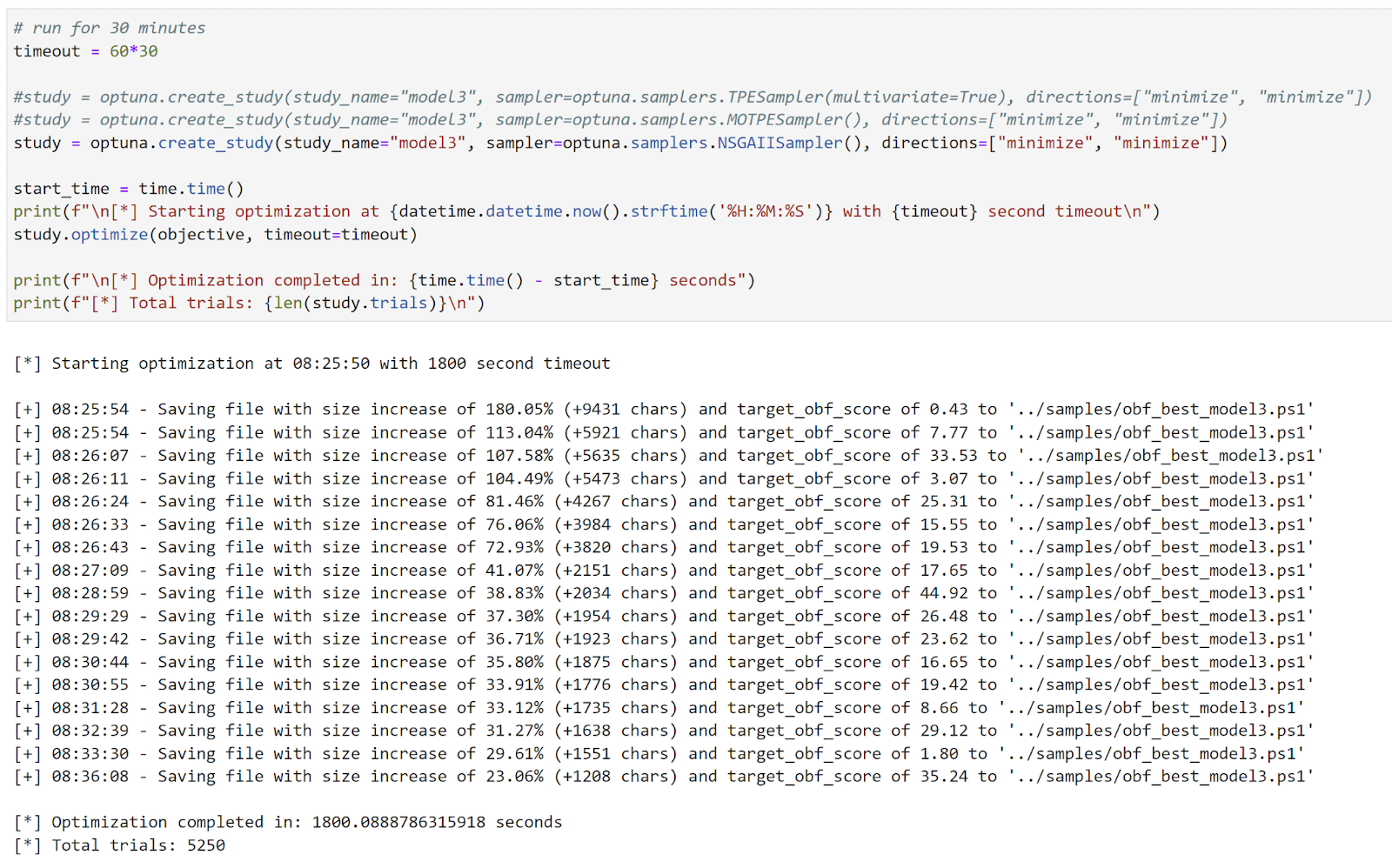
И финальный оптимизированный скрипт выглядит так:
В течение 30 минут мы получили оптимизированный скрипт, размер которого увеличился по сравнению с исходным скриптом всего на 23,06 %, но при этом показатель обфускации по сравнению с целевой моделью составил 35,24 – значительно ниже порогового значения 50 для Нормального.
Последний вопрос, который у меня возникает, звучит так: Переносится ли эта враждебная выборка на две другие целевые модели?. Давайте посмотрим:
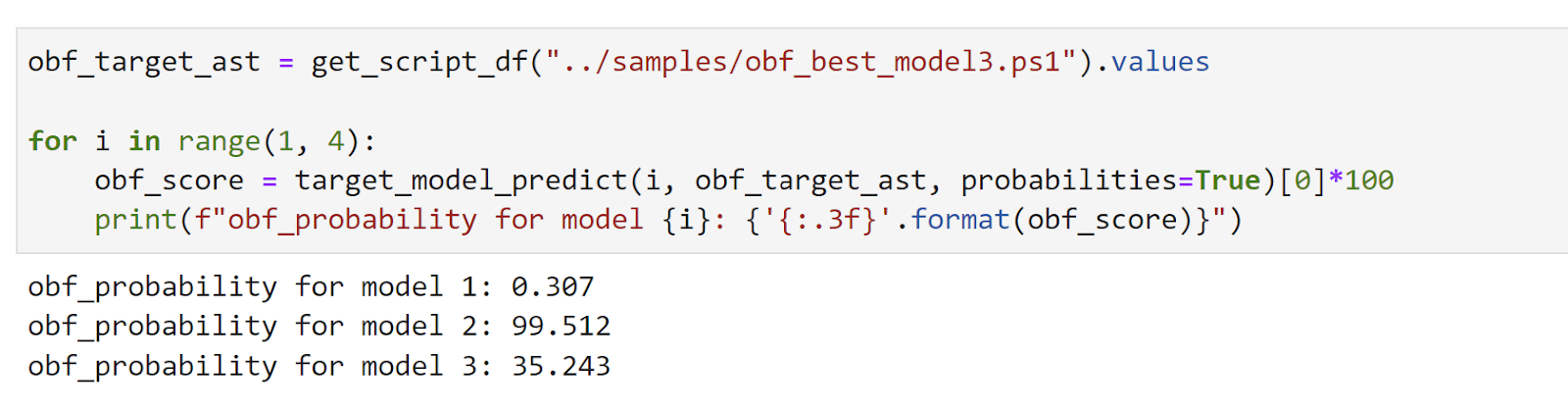
Этот оптимизированный образец оказался успешным в отношении целевой модели 3, нейронной сети, а также модели 1, логистической регрессии. Однако он не перешел на усиленный древовидный ансамбль LightGBM (модель 2). Вероятно, это потому, что мы:
- Построены наши преобразования функций из локальной суррогатной модели, настроенной для вероятностей модели 3.
- Специально оптимизирован для границы решения для модели 3
- От ансамблей деревьев часто бывает сложнее уклониться.
Наблюдения и заключительные мысли
Уклоняться от линейных моделей, таких как логистическая регрессия, легко. Обходить древовидные ансамбли, такие как случайные леса, деревья решений с градиентным усилением или нейронные сети, немного сложнее. Обходить версии этих моделей в виде «черного ящика» еще сложнее или, по крайней мере, требует больше времени и усилий.
Большинство описанных в литературе атак включают в себя создание нескольких образцов со стороны противника и проверку их эффективности против целевой модели, как мы сделали для наших трех целевых моделей. Я знаю не так уж много работы, о которой я знаю (я обещал, что постараюсь найти!)которая включает в себя практические реальные атаки черного ящика на табличные данные, такие как примеры здесь . В зависимости от целевой архитектуры модели и от того, является ли модель «белым ящиком» или «черным ящиком», уклонение от одного образца может иметь различные уровни сложности.
Область состязательного машинного обучения существует менее десяти лет, а первые формализованные атаки были выпущены примерно в 2014 году. До сих пор большая часть работы была академической и в значительной степени сосредоточена на атаках белого ящика против классификаторов изображений. Несмотря на то, что существуют практические фреймворки, такие как Adversarial Robustness Toolbox, secml и secml_malware, многие из классических алгоритмов атаки имеют ограничения, которые делают их либо неприменимыми, либо нежелательными для наших сценариев атак. В частности, не все алгоритмы атаки можно использовать с табличными данными или данными, не относящимися к изображениям, и большинство из них не позволяют вам ограничивать изменяемые функции (известное как маскирование функций).
Что касается алгоритма состязательной атаки, Уилл сообщил мне, что все это просто проблема оптимизации! Информационная безопасность, как и многие другие отрасли, часто остается без внимания достижения в других областях, которые могли бы нам очень помочь. Моим личным примером этого было, когда Энди и я работали над проблемой/инструментом, который в конечном итоге стал оригинальным графовым подходом BloodHound — мы продолжали спотыкаться вокруг проблемы, пока Энди не обсуждал наши проблемы со своим другом Сэмом, который сокрушался, Чувак, как вы, ребята, не слышали о теории графов?
Проблема как нам взять эти цифры злоумышленника и преобразовать их обратно в пригодную для использования атаку — это реальная проблема практического выполнения этих атак. Однако, если мы изменим наше отношение к проблеме, мы можем использовать подходы, на которые повлияли фреймворки Counterfit или secml_malware, или сами фреймворки для оптимизации действий злоумышленников.
Я надеюсь, что академическое сообщество по состязательному машинному обучению продолжает добиваться большего прогресса в практических исследованиях состязательности, выходящих за рамки состязательных атак типа белый ящик на классификаторы изображений (вроде этого, этого , и это"!). Проблемы в реальном мире сложнее, чем просто играть с MNIST, и есть много шансов для отличного сотрудничества с профессионалами отрасли безопасности для решения некоторых из этих практических сценариев. Существует множество моделей деревьев с градиентным усилением, не ориентированных на изображения, развернутых в реальном мире в виде черных ящиков: как мы можем эффективно атаковать их, сводя к минимуму количество запросов?
Также помните, что для того, чтобы иметь хоть какую-то надежду на атаку противника, работающую против модели черного ящика, вам нужно знать входные данные! С изображениями это очевидно, но для реальных систем это может привести к более сложным и может потребовать обратного проектирования, чтобы понять механизмы извлечения признаков.
И, наконец, помните, что модели машинного обучения — это живое решение. Как заявил Ли Холмс, одна вещь, которую следует иметь в виду при работе с моделями машинного обучения или сигнатурами, это то, что они никогда не «готовы. Если вы не проводите переобучение на основе ложноположительных и ложноотрицательных результатов, вы проиграли». Для краткости я пропустил множество реальных проблем, связанных с развертыванием и обслуживанием модели. Возникающая подобласть MLOPs занимается многими из этих вопросов, и я планирую вернуться к практической реализации моделей, которые мы обсуждали в этой серии, по мере того, как я буду больше узнавать об этой новой дисциплине.
Эпилог
А как насчет защиты??!!?
Да, я знаю, я знаю, пожалуйста, не @меня, что я безответственный член команды красных. Я напишу последующий пост, в котором буду размышлять о некоторых способах защиты в этом проблемном пространстве, однако я все еще пытаюсь найти свое место в таких вещах, как дистилляция и противоборствующая подготовка. Но я оставлю вас с пониманием, которое крестный отец враждебного машинного обучения Ян Гудфеллоу высказал около четырех лет назад:
Также важно подчеркнуть, что до сих пор все средства защиты основаны на нереально простых моделях угроз, в которых атакующий очень ограничен… в качестве исследовательской задачи было очень трудно решить даже ограниченную версию, и это остается очень активной областью исследований с много важных задач, которые нужно решить.
Для будущей работы в этой конкретной области, вот несколько общих целей, которые я надеюсь преследовать:
- Изучите обнаружение обфускации на основе текста вместо подхода AST, описанного в этой серии. Это влияет на возможность развертывания в некоторых сценариях.
- Проверьте эффективность средств защиты от машинного обучения против этих конкретных моделей.
- Запустите этот тип исследования белого/черного ящика на другом наборе данных для сравнения.
- Погрузитесь больше в атакующие ансамбли деревьев.
- ???
Теперь, когда мы подошли к концу этого потока информации, разбросанной по трем постам, я надеюсь, вам понравилось читать этот материал так же, как мне понравилось его исследовать и писать. Это был долгий, но полезный путь для меня, и если это пробудило в вас интерес к этой области, я говорю, присоединяйтесь! Вы можете присоединиться к нам на DEF CON AI Village Discord, на канале #DeepThought в BloodHound Slack или написать мне по электронной почте [at]harmj0y.net.
[Править] Вскоре после публикации этого поста Баттиста Биджио указал, что я пропустил репозиторий secml_malware и связанные документы для атак, реализованных в этой среде. Я обновил ссылки в этом посте, чтобы отразить эту предыдущую работу. Хотя мне нужно больше времени, чтобы все переварить, на первый взгляд кажется, что основное внимание уделяется манипулированию байтами PE. По крайней мере, некоторые из существующих работ, такие как GAMMA (Genetic Adversarial Machine Learning Malware Attack) Demetrio et al. включает специальные генетические оптимизаторы для эффективного выполнения PE-преобразований с сохранением функциональности. Структура RAMEN описывает как генетический подход, так и подход к обучению с подкреплением для этого типа проблемы уклонения от PE. Эта существующая работа потрясающая, и я с нетерпением жду возможности углубиться в нее!
Рекомендации
- ШАП
- Инструментарий противодействия устойчивости
- secml и secml_malware
- Подделка (особенно ветка mlsecevasion)
- Эти два поста Адриана Кресса об уклонении от моделей вредоносного ПО с машинным обучением, которые очень вдохновили
- Запись Машинное обучение от идеи к реальности: пример использования PowerShell» автора Джуста Янсена
- Все разговоры Уилла Пирса