Пришло время попрощаться с pd.to_csv() и pd.read_csv()

Построение сквозного конвейера, управляемого данными, является сложной задачей. Я сам был там, процесс чрезвычайно утомительный, и неизбежно можно получить множество промежуточных файлов. Хотя эти файлы обычно предназначены для использования в качестве контрольных точек или помощи дальнейшим модулям в конвейере, можно непреднамеренно поставить под угрозу время выполнения и повысить требования к хранилищу, если не выбрать подходящий формат для этих промежуточных файлов. CSV.
Будучи специалистом по данным, я понимаю, что CSV обеспечивает огромную гибкость в чтении данных, записи, предварительном просмотре, изучении и т. д. Это удобный формат для вас, меня и почти всех, кто работает с DataFrames. Чаще всего я также использовал формат CSV для экспорта DataFrame UNTIL совсем недавно, когда обнаружил несколько эффективных по времени и оптимизированных для хранения альтернатив CSV.
К счастью, Pandas предлагает множество форматов файлов, в которых вы можете сохранять свои кадры данных, например:
- CSV
- Соленый огурец
- Паркет
- Перо
- JSON
- HDF5
Это побудило меня ранжировать вышеупомянутые форматы на основе их практической эффективности по следующим параметрам:
- Место, которое они занимают на диске.
- Время, необходимое для операций чтения и записи на диск.
Экспериментальная установка
В целях эксперимента я сгенерировал случайный набор данных в Python с миллионом строк и тридцатью столбцами, включая строковые, плавающие и целочисленные типы данных.
Я повторил каждый эксперимент, описанный ниже, десять раз, чтобы уменьшить случайность и сделать справедливые выводы из наблюдаемых результатов. Приведенная ниже статистика является средним значением для десяти экспериментов.
Эксперименты
Эксперимент 1: Использование места на диске после сохранения
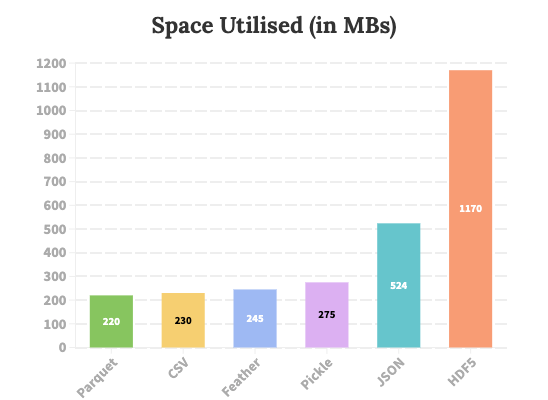
- Очевидно, что HDF5 не должен быть вашим первым выбором, если вы ищете формат, оптимизированный для памяти. Здесь используемое дисковое пространство более чем вдвое превышает следующий лучший формат, видимый на гистограмме выше — JSON, который почти вдвое превышает размер других четырех форматов.
- На данный момент Parquet, CSV, Feather и Pickle представляются подходящими вариантами для хранения нашего DataFrame, поскольку все они блокируют примерно одинаковую часть вторичного хранилища для одного и того же объема данных.
Эксперимент 2: время, необходимое для загрузки и сохранения
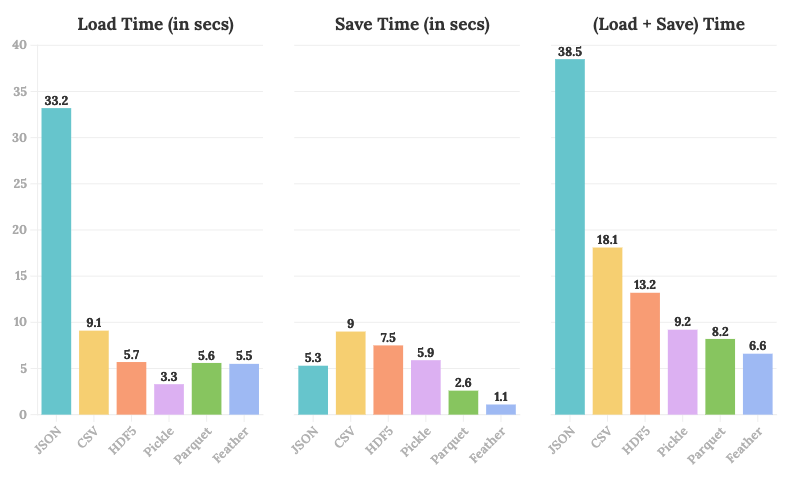
Здесь мы начинаем замечать недостатки использования формата CSV.
- Давайте пока рассмотрим только время загрузки. Время, затрачиваемое на чтение CSV, почти в три раза больше, чем у лучшей доступной альтернативы — рассола. Более того, как мы видели ранее, Pickle и CSV занимают одинаковое количество места, так зачем выбирать более медленный вариант?
- Что касается экономии времени, CSV — самый дорогой вариант на выбор — он потребляет почти в восемь раз больше, чем Feather.
По-видимому, при сохранении вашего DataFrame в определенном формате вы обязаны снова использовать тот же формат при загрузке. Другими словами, после того как вы сохранили свой DataFrame как файл рассола, у вас нет другого выбора, кроме как прочитать его как файл рассола. Поэтому на третьей гистограмме выше мы смотрим на их общую эффективность, т. е. время загрузки + время сохранения.
- К сожалению, CSV — не лучший выбор, который у нас есть.
- По сравнению с Feather, Parquet и Pickle, CSV в среднем в 2,5 раза медленнее, чем эти форматы, что является безумно высоким показателем.
На мой взгляд, и Parquet, и Feather являются лучшими доступными форматами файлов для выбора из шести, которые мы рассмотрели в этой статье.
Заключительные примечания
Я знаю, что CSV — это здорово. Мне они тоже нравятся, и я являюсь поклонником CSV по бесчисленным причинам, таким как:
- При необходимости CSV позволяет мне читать только подмножество столбцов, экономя оперативную память и время чтения.
- CSV по сути является текстовым файлом. Поэтому Pandas позволяет мне просматривать первые n (скажем, 5, 10, 15 и т. д.) строк, присутствующих в CSV.
- Excel — один из моих любимых инструментов, и я могу открыть файл CSV прямо в Excel.
Однако CSV убивает ваш конвейер. Это действительно так. Вы тратите огромное количество времени на операции чтения и записи только потому, что файлы CSV повсюду.
Если вам не нужно просматривать свой DataFrame вне среды, отличной от Python, такой как Excel, ВАМ ВООБЩЕ НЕ НУЖЕН CSV. Вы должны предпочесть Parquet, Feather или Pickle, потому что, как мы заметили выше, они обеспечивают значительно более быстрые операции чтения и записи, чем CSV.
Так что в следующий раз, когда вы собираетесь выполнить pd.to_csv(), подумайте, действительно ли вам нужен CSV.
